


















For ThreadLocal, people’s first reaction might be that it’s simply a per-thread variable copy, with each thread isolated. Here are a few questions you can think about:
- The key of
ThreadLocalis a weak reference. So when callingThreadLocal.get(), after a GC event, is the key null? - What is the data structure of
ThreadLocalMapinsideThreadLocal? - What is the hash algorithm of
ThreadLocalMap? - How are hash collisions resolved in
ThreadLocalMap? - What is the growth mechanism of
ThreadLocalMap? - What is the cleanup mechanism for expired keys in
ThreadLocalMap? The probing cleanup and heuristic cleanup processes? - How does
ThreadLocalMap.set()implement its logic? - How does
ThreadLocalMap.get()implement its logic? - How is
ThreadLocalused in the project? Any caveats? - …
Note: This article’s source code is based on JDK 1.8
ThreadLocal Code Demonstration
We’ll first look at a usage example of ThreadLocal:
public class ThreadLocalTest { private List<String> messages = Lists.newArrayList();
public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) { holder.get().messages.add(message); }
public static List<String> clear() { List<String> messages = holder.get().messages; holder.remove();
System.out.println("size: " + holder.get().messages.size()); return messages; }
public static void main(String[] args) { ThreadLocalTest.add("testsetestse"); System.out.println(holder.get().messages); ThreadLocalTest.clear(); }}Output:
[testsetestse]size: 0ThreadLocal objects can provide thread-local variables; each Thread owns its own copy of the variable, and multiple threads do not interfere with each other.
The data structure of ThreadLocal
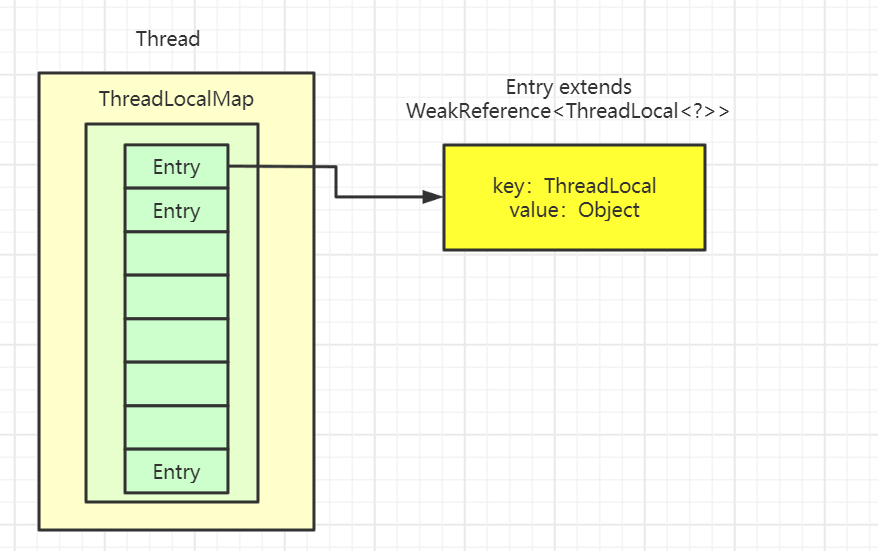
The Thread class has an instance variable of type ThreadLocal.ThreadLocalMap named threadLocals, meaning each thread has its own ThreadLocalMap.
ThreadLocalMap has its own independent implementation. Its key can be viewed as the ThreadLocal, and the value is the value stored in the map (in fact, the key is not the ThreadLocal itself, but a weak reference to it).
Whenever a thread puts a value into a ThreadLocal, it stores it in its own ThreadLocalMap; reads also use the ThreadLocal as the reference and search for the corresponding key within its own map, achieving thread isolation.
ThreadLocalMap is somewhat like a HashMap in structure, but while a HashMap is implemented as an array plus linked lists, ThreadLocalMap does not use a linked-list structure.
We should also note that the Entry’s key is ThreadLocal<?> k, which inherits from WeakReference, i.e., it is a weak reference type.
After GC, is the key null?
Addressing the opening question: the key of ThreadLocal is a weak reference. So after a GC event in a ThreadLocal.get() operation, is the key null?
To resolve this, we need to understand Java’s four reference types:
- Strong reference: Objects created with
neware normally strong references. As long as a strong reference exists, the garbage collector will not reclaim the object, even under memory pressure. - Soft reference: Objects referenced via
SoftReferenceare soft references; the referred object is reclaimed when memory is about to overflow. - Weak reference: Objects referenced via
WeakReferenceare weak references; when a GC occurs, if the object is only softly/weakly reachable via weak references, it will be collected. - Phantom reference: The weakest form; in Java, defined via
PhantomReference. The only purpose is to enqueue notifications that an object is about to be reclaimed.
Now looking at the code, we use reflection to inspect the data in GC’d state:
public class ThreadLocalDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException { Thread t = new Thread(()->test("abc",false)); t.start(); t.join(); System.out.println("--gc后--"); Thread t2 = new Thread(() -> test("def", true)); t2.start(); t2.join(); }
private static void test(String s,boolean isGC) { try { new ThreadLocal<>().set(s); if (isGC) { System.gc(); } Thread t = Thread.currentThread(); Class<? extends Thread> clz = t.getClass(); Field field = clz.getDeclaredField("threadLocals"); field.setAccessible(true); Object ThreadLocalMap = field.get(t); Class<?> tlmClass = ThreadLocalMap.getClass(); Field tableField = tlmClass.getDeclaredField("table"); tableField.setAccessible(true); Object[] arr = (Object[]) tableField.get(ThreadLocalMap); for (Object o : arr) { if (o != null) { Class<?> entryClass = o.getClass(); Field valueField = entryClass.getDeclaredField("value"); Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent"); valueField.setAccessible(true); referenceField.setAccessible(true); System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o))); } } } catch (Exception e) { e.printStackTrace(); } }}Output:
弱引用key:java.lang.ThreadLocal@433619b6,值:abc弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12--gc后--弱引用key:null,值:defAs shown, because the ThreadLocal created here does not point to any value yet (i.e., there are no references), the key will be collected after GC, and in the above debug, the referent is null.
If you look at this topic without deeper thought—just considering weak references and garbage collection—it might seem like the key is null.
In fact, that’s not correct, because the scenario described is during a ThreadLocal.get() operation, which proves that there is still a strong reference present, so the key is not null; the strong reference to the ThreadLocal still exists.
If our strong reference did not exist, the key would be collected, which would cause the value to remain and the key to be collected, leading to a memory leak.
The detailed source of ThreadLocal.set()
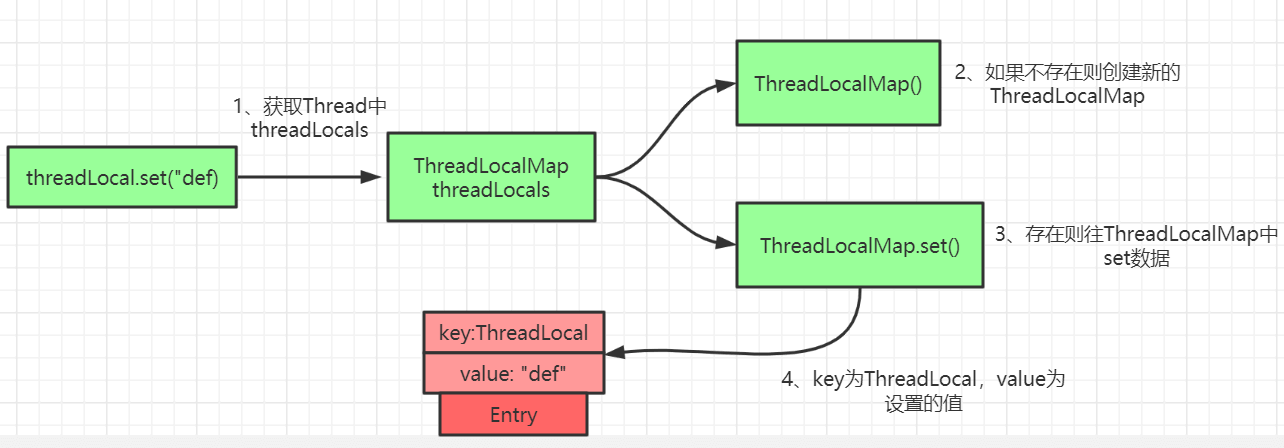
The principle of the set method in ThreadLocal is as shown in the figure above. It’s simple: mainly checks whether the ThreadLocalMap exists, then uses the set method in ThreadLocal to handle the data.
Code:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value);}
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue);}The core logic is still in ThreadLocalMap.
The hash algorithm of ThreadLocalMap
Since it’s a Map structure, ThreadLocalMap must implement its own hash algorithm to resolve collisions in the hash table array.
int i = key.threadLocalHashCode & (len-1);The hash algorithm in ThreadLocalMap is straightforward. Here, i is the index in the hash table that the current key maps to.
The key point is the calculation of the threadLocalHashCode value. ThreadLocal has a field with the value HASH_INCREMENT = 0x61c88647.
public class ThreadLocal<T> { private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
static class ThreadLocalMap { ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } }}Whenever a ThreadLocal object is created, the value ThreadLocal.nextHashCode increases by 0x61c88647.
This value is special: it is related to the golden ratio. The hash increment being this number yields a very uniform distribution.
ThreadLocalMap hash collisions
Note: In all the sample diagrams below, green blocks representing Entry denote normal data, gray blocks denote Entries whose key value is null (garbage collected), and white blocks denote null entries.
Although ThreadLocalMap uses the golden ratio as the hash factor to greatly reduce collision probability, collisions can still occur.
In a HashMap collisions are resolved by constructing a linked-list structure on the array; conflicting data are attached to the list. If the list grows too long, it may be converted into a red-black tree.
But ThreadLocalMap does not use a linked-list structure, so the HashMap strategy for collisions cannot be used here.
As shown above, if we insert a data with value=27, after hashing it should land in slot 4, but slot 4 already holds an Entry.
At this point, a linear forward probe occurs until a slot with Entry equal to null is found, and the current element is placed there. Of course, during iteration there are other cases, such as encountering an Entry with a non-null key and an equal key value, or an Entry with a null key, etc., each with different handling that will be described in detail later.
We also illustrate an Entry with a null key (a gray block for Entry=2). Because the key is a weak reference, such data can exist. In the set process, if an Entry with an expired key is encountered, a probing cleanup operation will actually be performed.
The detailed explanation of ThreadLocalMap.set()
Diagrammatic explanation of ThreadLocalMap.set()
After understanding the hash algorithm, let’s see how set is implemented.
Setting data in ThreadLocalMap (new or updated) falls into several situations; for each situation, we illustrate with diagrams.
-
The slot computed by the hash points to an empty
Entry: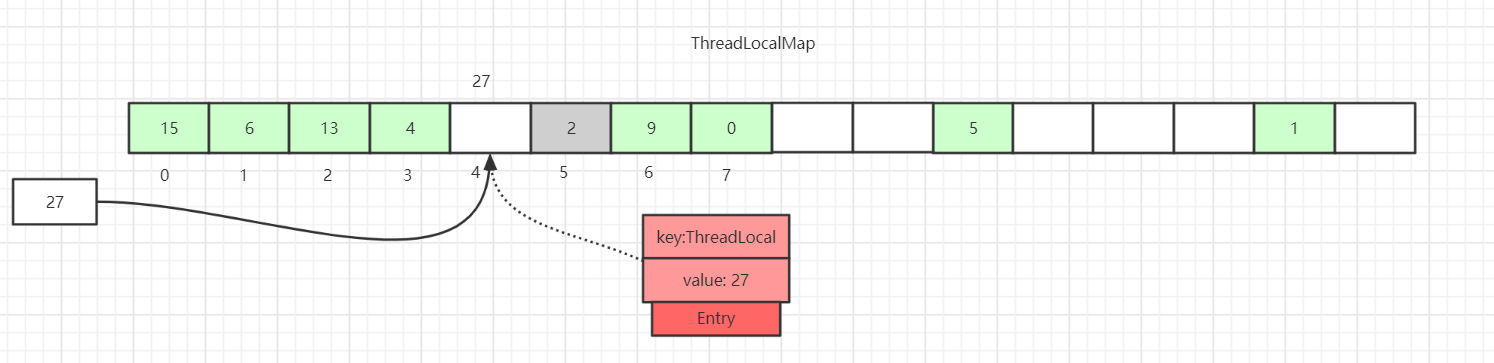
Here we simply place the data into that slot.
-
The slot contains data, and the key equals the current
ThreadLocal’s hashed key: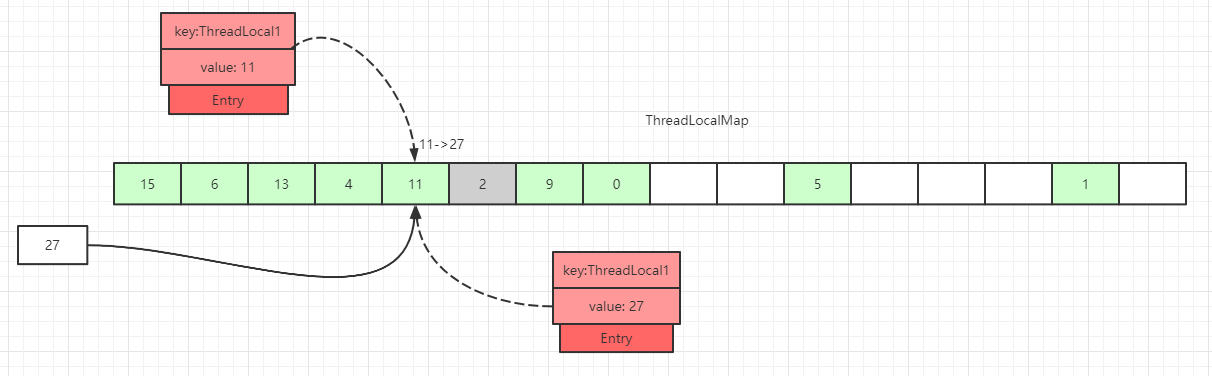
Here we directly update the data in that slot.
-
The slot contains data, and while traversing forward, before finding a slot with
Entryequal to null, we have not encountered an expired key: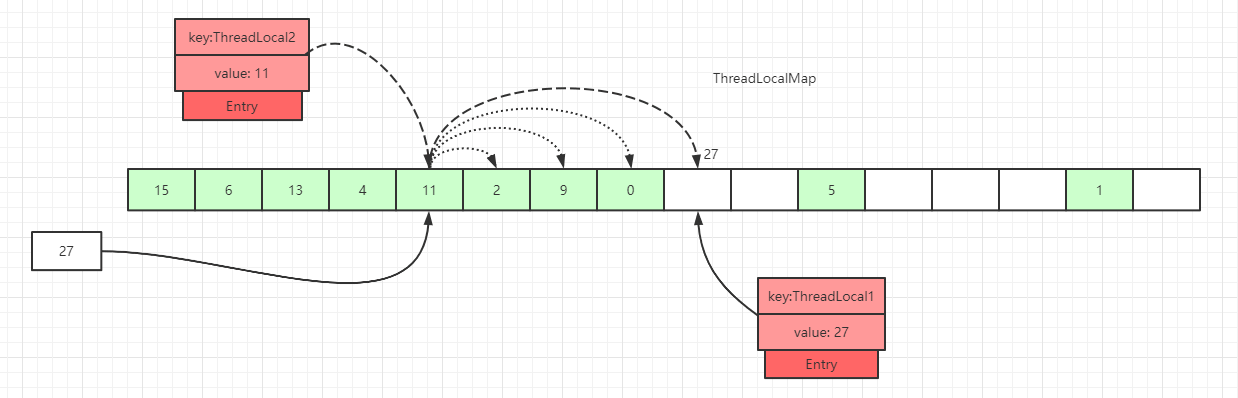
We traverse the hash array linearly; if we find a slot with
Entryequal to null, we put the data there; or, during traversal, if we encounter data with the same key value, we update it directly. -
The slot contains data, and while traversing forward, before finding a slot with
Entryequal to null, we encounter an expired keyEntryas shown: theEntryat index 7 haskey=null: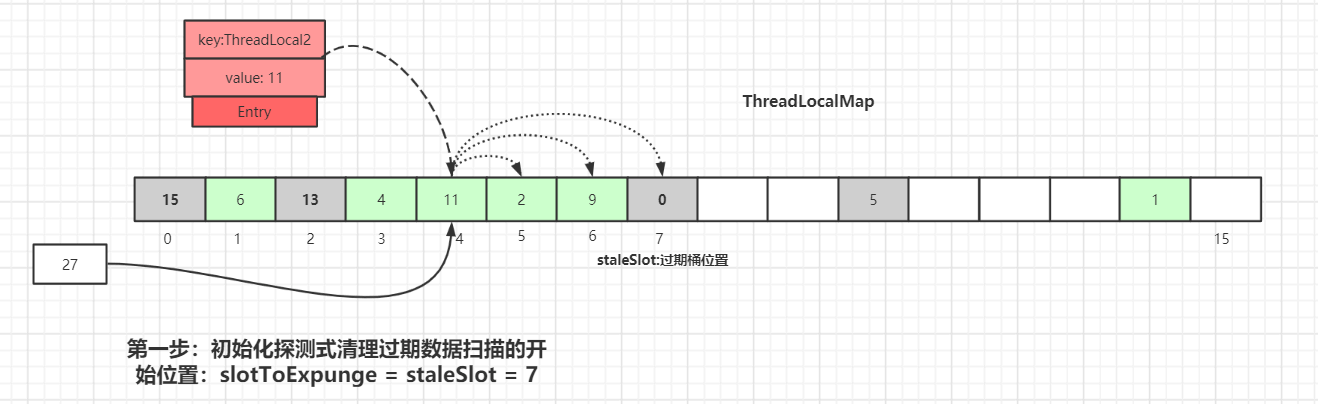
The hash table index 7 has an
Entrywhosekeyisnull, indicating that this data’s key value has been garbage collected. In this case thereplaceStaleEntry()method is invoked, which handles the logic of replacing expired data. Starting from index 7, it performs a probing cleanup.The initialization of the probing cleanup start position is:
slotToExpunge = staleSlot = 7Starting from the current
staleSlot, we iterate backward to find other expired data, updating the starting scan indexslotToExpunge. The loop ends when it hits anEntrythat isnull.If expired data is found, we continue forward; if we encounter data with the same key value, we update that
Entry’s data and swap thestaleSlotelement with thatEntry(thestaleSlotposition becomes an expired element). After updating theEntrydata, we begin cleaning up expired entries, as shown:If during the backward iteration we do not find an expired data, the forward iteration may not find a matching key; in that case, a new
Entryis created and replaces thetable[staleSlot]position: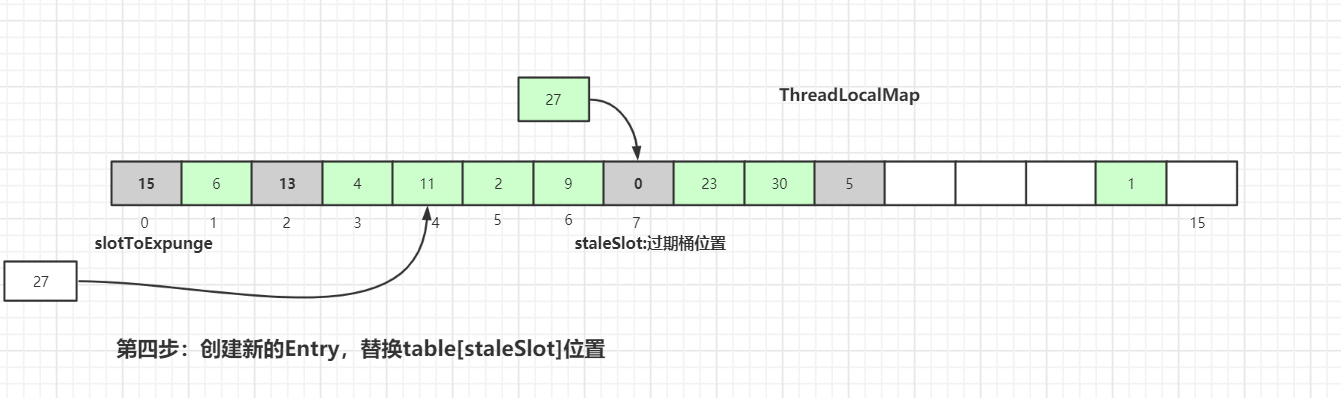
After replacement, cleanup of expired elements is performed via two methods:
expungeStaleEntry()andcleanSomeSlots().
The source of ThreadLocalMap.set()
The above diagrams already illustrate the principle of set(); the actual code is as follows:
private void set(ThreadLocal<?> key, Object value) { // Determine the slot using the key and then linearly search forward to find a usable bucket. Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1);
// Iterate forward for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // If the bucket’s Entry for the key is not null ThreadLocal<?> k = e.get();
// If k equals key, this is a replacement operation; update and return if (k == key) { e.value = value; return; }
// If k == null, this is an expired entry; perform replaceStaleEntry() and return if (k == null) { replaceStaleEntry(key, value, i); return; } }
// If we get here, we found a null slot after iterating // Create a new Entry in this slot and increment size tab[i] = new Entry(key, value); int sz = ++size; // Perform a heuristic cleanup of expired data // If no cleanup occurred and size exceeds the threshold, perform a rehash if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();}
private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0);}
private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1);}When is a bucket usable?
- The key equals the current key: replacement is allowed.
- When encountering an expired bucket, perform replacement to occupy the expired bucket.
- While traversing, when encountering an
EntrywithEntry=null, use it.
Next, focus on the replaceStaleEntry() method, which provides the logic to replace expired data. We can map this to the fourth scenario’s principle diagram. The code is:
java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry() …private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e;
// Start of probing cleanup: begin from the current staleSlot int slotToExpunge = staleSlot; // Walk backward from the current staleSlot, until we encounter null for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
// If an expired entry is found, update the start of probing cleanup if (e.get() == null) slotToExpunge = i;
// Walk forward from staleSlot; until we encounter a null Entry for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// If we meet the same key, this is a replacement // Replace the data and swap the staleSlot element if (k == key) { e.value = value;
tab[i] = tab[staleSlot]; tab[staleSlot] = e;
// If the initial probe didn’t find stale data // set the new starting expunge index to i if (slotToExpunge == staleSlot) slotToExpunge = i; // Clean up with a heuristic cleanup cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // If key is null, and slotToExpunge == staleSlot // update slotToExpunge to i if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // If no matching key is found, add a new entry at staleSlot tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value);
// If there were other expired slots, start cleanup if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);}The probing cleanup flow for expired keys in ThreadLocalMap
We mentioned two ways to clean expired keys in ThreadLocalMap: probing cleanup and heuristic cleanup.
Probing cleanup
Probing cleanup is performed by the expungeStaleEntry method. It traverses the hash array from a starting position forward, clearing expired entries, and rehashing encountered non-expired entries to nearer-than-cur-slot positions if needed. The logic is as follows:
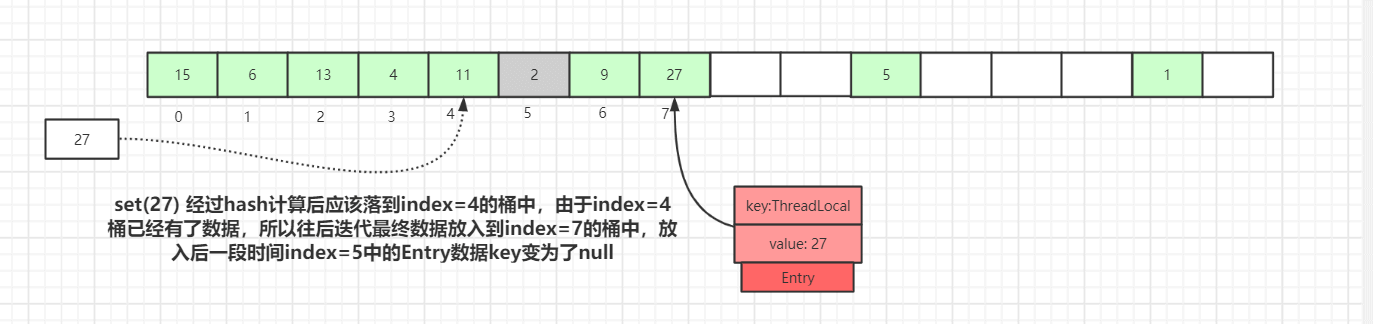
As shown, after set(27), the hashed position would be index 4, but index 4 already contains data. It then iterates forward to eventually place at index 7. After some time, the key at index 5 becomes null due to expiration.
If additional data is set into the map, probing cleanup is triggered.
After probing cleanup, the data at index 5 is cleared, the iteration continues, and after rehashing, the element at index 7 ends up at index 4. The nearest null slot is used to place the data that has been probed, making positions closer to the correct index.
One probing cleanup pass clears expired keys; after rehashing, non-expired entries are placed closer to their correct bucket positions, improving lookup performance.
Next, we examine the exact implementation of the cleanup process:
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length;
// Clear the stale slot and decrease size tab[staleSlot].value = null; tab[staleSlot] = null; size--;
Entry e; int i; // Iterate forward from the staleSlot for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // If the key has expired if (k == null) { e.value = null; tab[i] = null; size--; } else { // If the key hasn’t expired, recalculate its index int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null;
while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i;}This handles the normal cases where a hash collision occurred; after probing, entries are moved to closer positions, improving lookup efficiency.
Heuristic cleanup flow
Probing cleanup is a linear probe cleanup from the current entry forward until a null is encountered.
Heuristic cleanup, defined by the author as: Heuristically scan some cells looking for stale entries.
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed;}The growth mechanism of ThreadLocalMap
In ThreadLocalMap.set(), after performing heuristic cleanup, if nothing was cleaned and the size has reached the threshold (len * 2/3), it triggers a rehash:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();Next, the implementation of rehash() is as follows:
private void rehash() { expungeStaleEntries();
if (size >= threshold - threshold / 4) resize();}
private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); }}- Perform probing cleanup across the table from the start.
- After cleanup, there may be entries with
nullkeys; this is removed byexpungeStaleEntries(). - Then, based on the condition
size >= threshold - threshold / 4(i.e.,size >= 3/4 of threshold), decide whether to expand.
When asked about the expansion mechanism, it’s important to mention these two steps.
Next, the actual resize() method (for demonstration, consider an example where oldTab.len = 8):
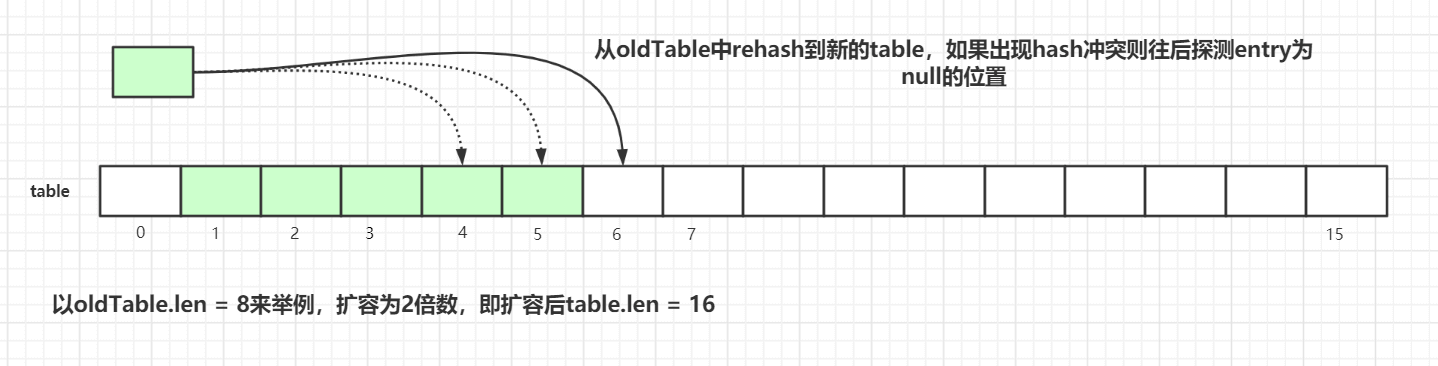
The new table size is oldLen * 2.
- Traverse the old hash table, recompute hash positions, and place entries into the new table.
- If a hash conflict occurs, pick the nearest slot whose
Entryisnull. - After traversal, all entries from the old table have been moved into the new one.
- Recompute the next expansion threshold for the new table.
Code:
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; int count = 0;
for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; } else { int h = k.threadLocalHashCode & (newLen - 1); while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } }
setThreshold(newLen); size = count; table = newTab;}ThreadLocalMap.get() Detailed Explanation
We’ve just covered set(); now let’s examine how get() works.
Diagram of ThreadLocalMap.get()
-
Compute the slot from the key; if the
Entry.keyin that slot matches the searched key, return it: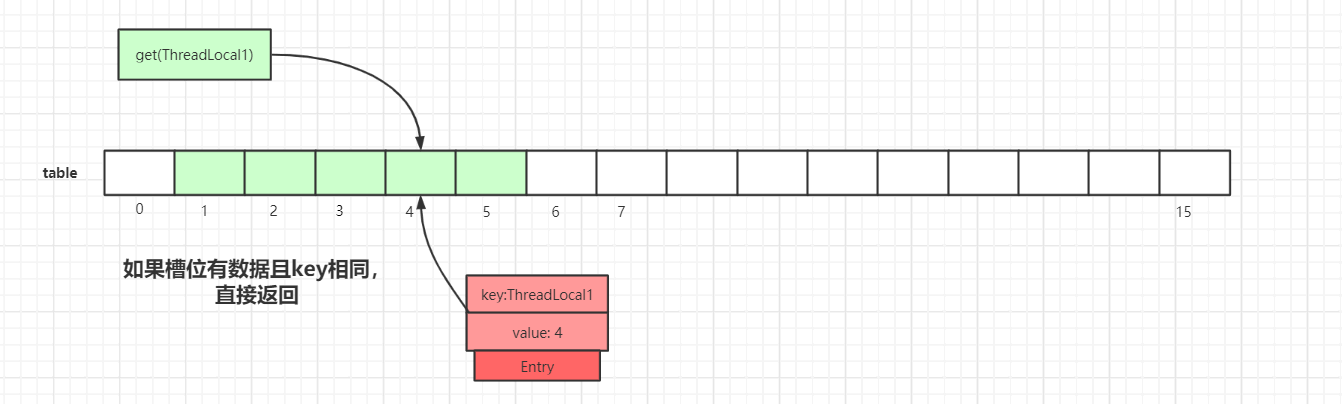
-
If the
Entry.keyin the slot does not match the searched key: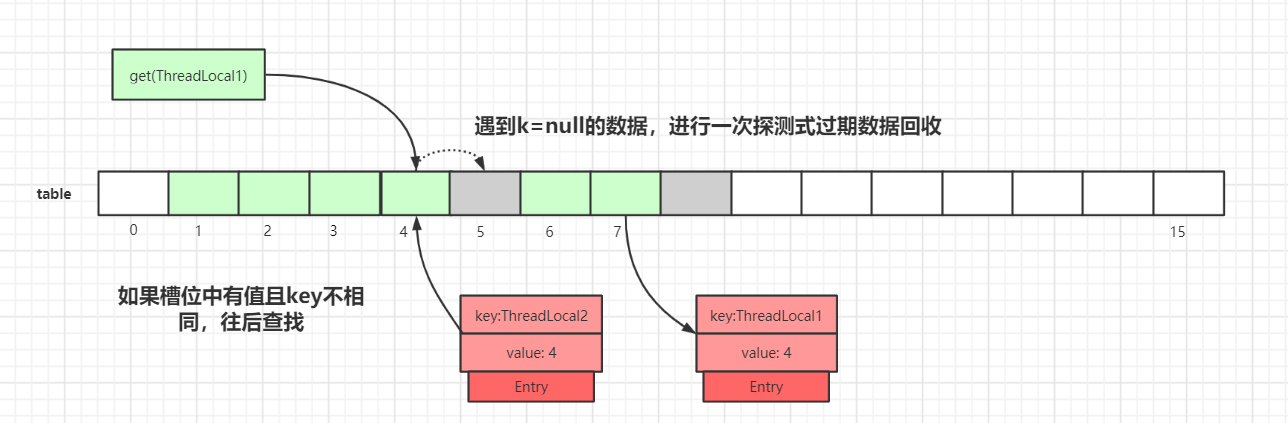
We take get(ThreadLocal1) as an example. After hashing, the correct slot would be 4, but index 4 already has data whose key is not ThreadLocal1, so we need to continue iterating.
When we reach index 5, the Entry.key is null. This triggers a probing cleanup operation via expungeStaleEntry(). After cleanup, data at index 5 and 8 are cleared, and data at indices 6 and 7 move forward. After moving forward, we resume from index 5 and continue to index 6, where we find the entry whose key matches, as shown:
The source of ThreadLocalMap.get() code
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e);}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null;}InheritableThreadLocal
When using ThreadLocal, in asynchronous scenarios you cannot share the parent thread’s copy of data with child threads.
To solve this, there is InheritableThreadLocal in the JDK. Consider the following example:
public class InheritableThreadLocalDemo { public static void main(String[] args) { ThreadLocal<String> ThreadLocal = new ThreadLocal<>(); ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>(); ThreadLocal.set("Parent data: threadLocal"); inheritableThreadLocal.set("Parent data: inheritableThreadLocal");
new Thread(new Runnable() { @Override public void run() { System.out.println("Child thread obtains parent ThreadLocal data: " + ThreadLocal.get()); System.out.println("Child thread obtains parent inheritableThreadLocal data: " + inheritableThreadLocal.get()); } }).start(); }}Output:
Child thread obtains parent ThreadLocal data:nullChild thread obtains parent inheritableThreadLocal data:Parent data: inheritableThreadLocalThe principle is that when a child thread is created by the parent thread via new Thread(), the Thread#init method is invoked during the thread’s construction. In the init method, the parent thread’s data is copied to the child thread:
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { if (name == null) { throw new NullPointerException("name cannot be null"); }
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); this.stackSize = stackSize; tid = nextThreadID();}But InheritableThreadLocal still has limitations. In practice, asynchronous processing often uses thread pools, and InheritableThreadLocal assigns values in the child thread’s init() method, while thread pools reuse threads, which can cause issues.
Of course, there are solutions. Alibaba open-sourced a TransmittableThreadLocal component to solve this problem. I won’t go into it further here; you can explore it if you’re interested.
Practical usage of ThreadLocal in projects
Use cases for ThreadLocal
In our project, we use ELK+Logstash for logging, and Kibana for viewing and searching.
All services are typically exposed in a distributed system; cross-service calls can be linked with a traceId. But how is the traceId passed across different projects?
We use org.slf4j.MDC to implement this, which internally relies on ThreadLocal. The implementation is as follows:
When a request hits Service A, Service A generates a string traceId similar to a UUID and places it in the current thread’s ThreadLocal. When calling Service B, the traceId is written into the request’s headers. Service B, on receiving the request, first checks if the header contains traceId, and if present, writes it into its own thread’s ThreadLocal.
requestId is the cross-system trace identifier; inter-service calls use it to locate the corresponding path. There are also other scenarios:
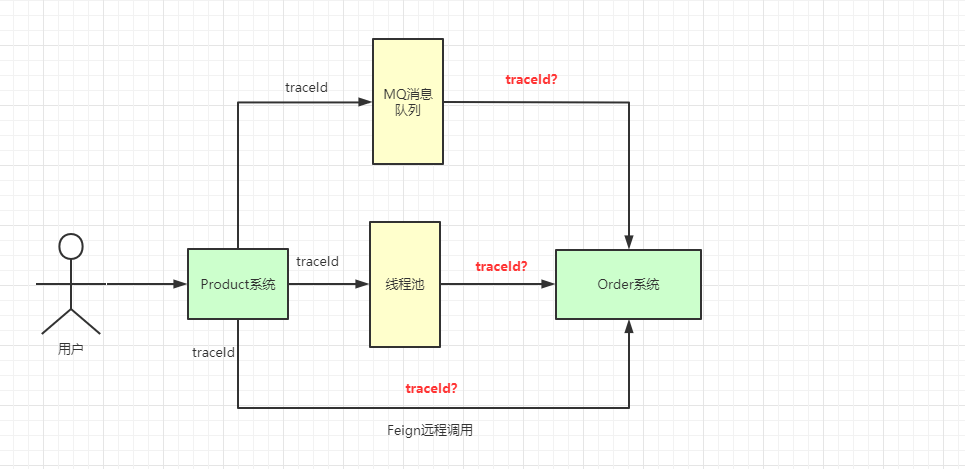
For these scenarios, there are corresponding solutions, as shown below.
Feign remote invocation solution
Service sending request:
@Component@Slf4jpublic class FeignInvokeInterceptor implements RequestInterceptor {
@Override public void apply(RequestTemplate template) { String requestId = MDC.get("requestId"); if (StringUtils.isNotBlank(requestId)) { template.header("requestId", requestId); } }}Service receiving request:
@Slf4j@Componentpublic class LogInterceptor extends HandlerInterceptorAdapter {
@Override public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) { MDC.remove("requestId"); }
@Override public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) { }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY); if (StringUtils.isBlank(requestId)) { requestId = UUID.randomUUID().toString().replace("-", ""); } MDC.put("requestId", requestId); return true; }}Thread pool asynchronous invocation, passing requestId
Because MDC is based on ThreadLocal, in asynchronous operations, child threads cannot access the parent thread’s ThreadLocal data. You can customize the thread pool executor and modify its run() method:
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
@Override public void execute(Runnable runnable) { Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> run(runnable, context)); }
@Override private void run(Runnable runnable, Map<String, String> context) { if (context != null) { MDC.setContextMap(context); } try { runnable.run(); } finally { MDC.remove(); } }}Use MQ to send messages to a third-party system
In the MQ message body, add a custom property requestId. The receiver consumes the message and can parse the requestId for use.
If this article helped you, please share it with others!
Some information may be outdated