


















pandas
Pandas Introduction
Pandas is an open-source library for data analysis and data processing, based on the Python programming language.
Pandas provides easy-to-use data structures and data analysis tools, especially suitable for handling structured data such as tabular data (similar to Excel spreadsheets).
Pandas is one of the commonly used tools in data science and analytics, enabling users to easily import data from various data sources and perform efficient operations and analysis on the data.
Pandas introduces two main data structures: DataFrame and Series
- Series: Similar to a one-dimensional array or list, consisting of a set of data and associated data labels (indices). A Series can be viewed as a column in a DataFrame, or as a standalone one-dimensional data structure.
- DataFrame: Similar to a two-dimensional table, it is the most important data structure in Pandas. DataFrame can be seen as a table composed of multiple Series arranged by column; it has both row indices and column indices, making it convenient to perform row/column selection, filtering, merging, etc.
Pandas provides a rich set of features, including:
- Data cleaning: handling missing data, duplicate data, etc.
- Data transformation: changing the shape, structure, or format of data.
- Data analysis: performing statistical analysis, aggregation, grouping, etc.
- Data visualization: by integrating libraries such as Matplotlib and Seaborn, you can perform data visualization.
Pandas Installation
-
Install Python
Download from the official site / Docker installation
-
Install Pandas
pip install pandasValidation:
import pandas as pdpd.__version__
Pandas Series
Structure
- Index: Each Series has an index, which can be integers, strings, dates, etc. If no explicit index is specified, Pandas automatically creates a default integer index.
- Data type: A Series can contain elements of different data types, including integers, floats, strings, etc.
pandas.Series( data, index, dtype, name, copy)
## data:A set of data (ndarray type).## index:Data indexing labels; if not specified, default starts from 0.## dtype:Data type; defaults to auto-detection.## name:Set the name.## copy:Copy the data, defaults to False.Examples
-
Using series
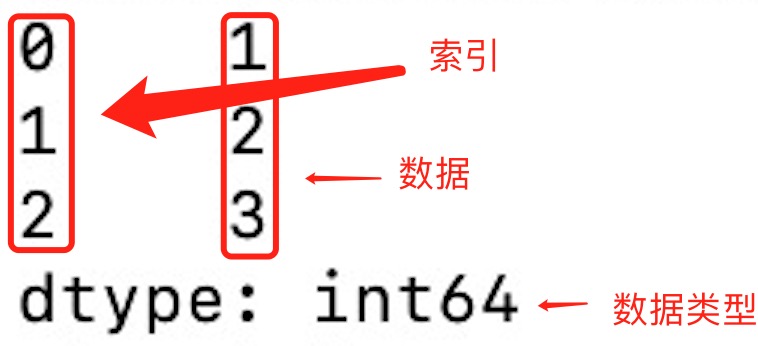
import pandas as pda = [1, 2, 3]myvar = pd.Series(a)print(myvar)print(myvar[1])Output:
-
Setting index with pd.Series
import pandas as pda = ["Google", "Runoob", "Wiki"]myvar = pd.Series(a, index = ["x", "y", "z"])print(myvar)print(myvar["y"]) -
Creating from a dictionary
import pandas as pdsites = {1: "Google", 2: "Runoob", 3: "Wiki"}myvar = pd.Series(sites)print(myvar)myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )print(myvar)myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )print(myvar)
Basic Operations
-
Basic Operations
## Get valuevalue = series[2] ## Get the value with index 2## Get multiple valuessubset = series[1:4] ## Get the values with index 1 to 3## Use a custom indexvalue = series_with_index['b'] ## Get the value for index 'b'## Index and value correspondencefor index, value in series_with_index.items():print(f"Index: {index}, Value: {value}") -
Arithmetic Operations
## Arithmetic operationsresult = series * 2 ## Multiply all elements by 2## Filteringfiltered_series = series[series > 2] ## Select elements greater than 2## Mathematical functionsimport numpy as npresult = np.sqrt(series) ## Take the square root of each element -
Attributes and Methods
## Get indexindex = series_with_index.index## Get values arrayvalues = series_with_index.values## Get descriptive statisticsstats = series_with_index.describe()## Get the index of the maximum and minimum valuesmax_index = series_with_index.idxmax()min_index = series_with_index.idxmin() -
Notes
- Data in a Series is ordered.
- A Series can be viewed as a one-dimensional array with an index.
- The index can be unique, but it is not required.
- Data can be scalars, lists, NumPy arrays, etc.
Pandas DataFrame
DataFrame Structure
- Columns and rows: DataFrame is composed of multiple columns, each column has a name and can be seen as a Series. At the same time, DataFrame has a row index used to identify each row.
- Two-dimensional structure: DataFrame is a two-dimensional table with rows and columns. It can be viewed as a dictionary of multiple Series objects.
- Data types of columns: Different columns can contain different data types, such as integers, floats, strings, etc.
pandas.DataFrame( data, index, columns, dtype, copy)
# data:A set of data (ndarray, series, map, lists, dict types).# index: The index values, or row labels# columns: Column labels, default is RangeIndex (0, 1, 2, ..., n)# dtype: Data type; defaults to auto-detection.# copy: Copy the data, defaults to False.DataFrame Examples
-
Using DataFrame
import pandas as pddata = [['Google',10],['Runoob',12],['Wiki',13]]df = pd.DataFrame(data,columns=['Site','Age'])print(df) -
Creating from ndarrays
import pandas as pddata = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}df = pd.DataFrame(data)print (df) -
Creating from dictionaries
import pandas as pddata = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]df = pd.DataFrame(data)print (df)Missing parts of data are NaN.
-
Returning specified rows with loc Pandas can use the loc attribute to return data for specified rows. If no index is set, the first row has index 0, the second row 1, and so on
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]}# Load data into a DataFrame objectdf = pd.DataFrame(data)# Return the first rowprint(df.loc[0])# Return the second rowprint(df.loc[1])# Return the first and second rowsprint(df.loc[[0, 1]])# Specify the indexprint(df.loc["duration"]) -
pd.DataFrame with specified index
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]}df = pd.DataFrame(data, index = ["day1", "day2", "day3"])print(df)
Basic DataFrame Operations
-
Basic Operations
# Get a columnname_column = df['Name']# Get a rowfirst_row = df.loc[0]# Select multiple columnssubset = df[['Name', 'Age']]# Filter rowsfiltered_rows = df[df['Age'] > 30] -
Data Manipulation
# Add a new columndf['Salary'] = [50000, 60000, 70000]# Delete a columndf.drop('City', axis=1, inplace=True)# Sortdf.sort_values(by='Age', ascending=False, inplace=True)# Rename a columndf.rename(columns={'Name': 'Full Name'}, inplace=True) -
Attributes and Methods
# Get column namescolumns = df.columns# Get shape (rows and columns)shape = df.shape# Get indexindex = df.index# Get descriptive statisticsstats = df.describe() -
Creating from external data sources
# Create DataFrame from a CSV filedf_csv = pd.read_csv('example.csv')# Create DataFrame from an Excel filedf_excel = pd.read_excel('example.xlsx')# Create DataFrame from a list of dictionariesdata_list = [{'Name': 'Alice', 'Age': 25}, {'Name': 'Bob', 'Age': 30}]df_from_list = pd.DataFrame(data_list) -
Notes
- DataFrame is a flexible data structure that can accommodate columns with different data types.
- Column names and row indices can be strings, integers, etc.
- DataFrame can be queried, filtered, modified, and analyzed in many ways.
- Through working with DataFrame, you can perform data cleaning, transformation, analysis, and visualization.
Pandas CSV
Introduction
CSV (Comma-Separated Values; sometimes also referred to as Character-Separated Values, since the separator character can be something other than a comma) stores tabular data (numbers and text) in plain text files.
CSV is a general-purpose, relatively simple file format widely used by users, businesses, and scientists.
-
Handling CSVs Pandas can easily handle CSV files
import pandas as pddf = pd.read_csv('site.csv')print(df.to_string()) -
Storing CSVs You can use the to_csv() method to store a DataFrame as a CSV file
import pandas as pd# Three fields name, site, agenme = ["Google", "Runoob", "Taobao", "Wiki"]st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]ag = [90, 40, 80, 98]# Dictionarydict = {'name': nme, 'site': st, 'age': ag}df = pd.DataFrame(dict)# Save dataframedf.to_csv('site.csv')
Data Processing
head()
head(n) method is used to read the first n rows; if n is not provided, it defaults to 5 rows.
import pandas as pd
df = pd.read_csv('nba.csv')print(df.head())
print(df.head(10))tail()
tail(n) method is used to read the last n rows; if n is not provided, it defaults to 5 rows, and the values of empty rows are NaN.
import pandas as pd
df = pd.read_csv('nba.csv')print(df.tail())
print(df.tail(10))info()
info() method returns some basic information about the table:
import pandas as pd
df = pd.read_csv('nba.csv')print(df.info())Pandas JSON
JSON (JavaScript Object Notation) is a syntax for storing and exchanging text information, similar to XML.
JSON is smaller, faster, and easier to parse than XML; for more JSON content, refer to JSON tutorials.
Pandas can easily handle JSON data
Plain JSON Handling
import pandas as pd
df = pd.read_json('sites.json')print(df.to_string())
URL = '<https://static.runoob.com/download/sites.json>'df = pd.read_json(URL)print(df)JSON objects have the same format as Python dictionaries, so we can directly convert Python dictionaries into DataFrame data
Nested JSON Handling
Using the json_normalize() method to fully parse nested data
import pandas as pdimport json
# Load data using Python's JSON modulewith open('nested_list.json','r') as f: data = json.loads(f.read())
# Flatten datadf_nested_list = pd.json_normalize(data, record_path =['students'])print(df_nested_list)More complex data
import pandas as pdimport json
# Load data using Python's JSON modulewith open('nested_mix.json','r') as f: data = json.loads(f.read())
df = pd.json_normalize( data, record_path =['students'], meta=[ 'class', ['info', 'president'], ['info', 'contacts', 'tel'] ])
print(df)Reading a Group of Data from Nested JSON
Use the glom module to handle nested data; the glom module allows us to access nested object attributes using dot notation
-
Install glom
pip3 install glom -
Usage
import pandas as pdfrom glom import glomdf = pd.read_json('nested_deep.json')data = df['students'].apply(lambda row: glom(row, 'grade.math'))print(data)
Data Cleaning
Cleaning Missing Values
If we want to delete rows that contain empty fields, we can use the dropna() method; the syntax is as follows:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# axis: defaults to 0, meaning drop the entire row when a missing value is present; if axis=1 is set, drop the entire column.# how: defaults to 'any'. If any data in a row (or column) has NA, drop the entire row; if how='all', a row (or column) where all values are NA is dropped.# thresh: set how many non-empty values are required to keep the row.# subset: set the columns to check. If multiple columns, you can use a list of column names.# inplace: If True is set, the calculated values overwrite the previous values and return None, modifying the source data.You can use isnull() to determine whether each cell is empty.
In pandas.read_csv you can specify na_values to designate missing values
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df['NUM_BEDROOMS'])print(df['NUM_BEDROOMS'].isnull())
# Specify missing datamissing_values = ["n/a", "na", "--"]df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])print (df['NUM_BEDROOMS'].isnull())
# Remove missing datanew_df = df.dropna()print(new_df.to_string())
# Modify the original DataFramedf.dropna(inplace = True)print(df.to_string())
# Remove rows with missing values in specified columnsdf.dropna(subset=['ST_NUM'], inplace = True)print(df.to_string())Using fillna() to replace missing values
A common method to replace empty cells is to compute the mean, median, or mode of the column.
Pandas uses mean(), median(), and mode() to compute the column mean (the average of all values), median (the middle value after sorting), and mode (the value that appears most frequently).
import pandas as pd
df = pd.read_csv('property-data.csv')
# Replace missing fields with 12345df.fillna(12345, inplace = True)print(df.to_string())
# Replace missing fields with the meanx = df["ST_NUM"].mean()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())
# Replace missing fields with the medianx = df["ST_NUM"].median()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())
# Replace missing fields with the modex = df["ST_NUM"].mode()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())Cleaning Incorrect Data
Data with incorrect formats can make data analysis difficult, even impossible.
We can address this by either including rows with empty cells, or converting all cells in a column to the same format data.
import pandas as pd
# The third date format is incorrectdata = { "Date": ['2020/12/01', '2020/12/02' , '20201226'], "duration": [50, 40, 45]}df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# In newer Python 3, the following will raise an error; you need to specify format='mixed' to clearly indicate mixed formats to run properly# pd.to_datetime(df['Date'])df['Date'] = pd.to_datetime(df['Date'], format='mixed')print(df.to_string())Using astype to modify data types
data['语文'].dropna(how='any').astype('int')Cleaning Erroneous Data
import pandas as pd
person = { "name": ['Google', 'Runoob' , 'Taobao'], "age": [50, 200, 12345]}
df = pd.DataFrame(person)
# Directly modify datadf.loc[2, 'age'] = 30
# Loop-based checksfor x in df.index: if df.loc[x, "age"] > 120: df.loc[x, "age"] = 120
# Delete rowsfor x in df.index: if df.loc[x, "age"] > 120: df.drop(x, inplace = True)
print(df.to_string())Cleaning Duplicate Data
If we want to clean duplicate data, you can use duplicated() and drop_duplicates() methods.
If the data is duplicated, duplicated() will return True; otherwise, it returns False.
import pandas as pd
person = { "name": ['Google', 'Runoob', 'Runoob', 'Taobao'], "age": [50, 40, 40, 23]}df = pd.DataFrame(person)
# Find duplicated dataprint(df.duplicated())
# Remove duplicate datadf.drop_duplicates(inplace = True)print(df)If this article helped you, please share it with others!
Some information may be outdated