


















ThreadLocal に関して、みなさんの最初の反応はとてもシンプルだと思います。スレッドの変数の副本で、各スレッドは分離されています。では、ここでいくつか考えるべき問題を挙げてみましょう:
- ThreadLocal の key は弱参照です。では ThreadLocal.get() のとき、 GC が発生した後、 key は null になりますか?
- ThreadLocalMap のデータ構造は?
- ThreadLocalMap のハッシュアルゴリズムは?
- ThreadLocalMap のハッシュ衝突はどう解決される?
- ThreadLocalMap の拡張機構は?
- ThreadLocalMap の過期キーのクリーンアップ機構は? 探索型クリーニングとヒューリスティッククリーニングのフローは?
- ThreadLocalMap.set() の実装原理?
- ThreadLocalMap.get() の実装原理?
- プロジェクトでの ThreadLocal の使用状況?直面した落とし穴は?
- ……
注記: 本文のソースコードは JDK 1.8 に基づいています
ThreadLocalコード演示
まずは ThreadLocal の使用例を見てみましょう:
public class ThreadLocalTest { private List<String> messages = Lists.newArrayList();
public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) { holder.get().messages.add(message); }
public static List<String> clear() { List<String> messages = holder.get().messages; holder.remove();
System.out.println("size: " + holder.get().messages.size()); return messages; }
public static void main(String[] args) { ThreadLocalTest.add("testsetestse"); System.out.println(holder.get().messages); ThreadLocalTest.clear(); }}出力結果:
[testsetestse]size: 0ThreadLocal オブジェクトはスレッドローカル変数を提供します。各スレッドは自分自身の副本変数を持ち、複数のスレッドは互いに干渉しません。
ThreadLocal のデータ構造
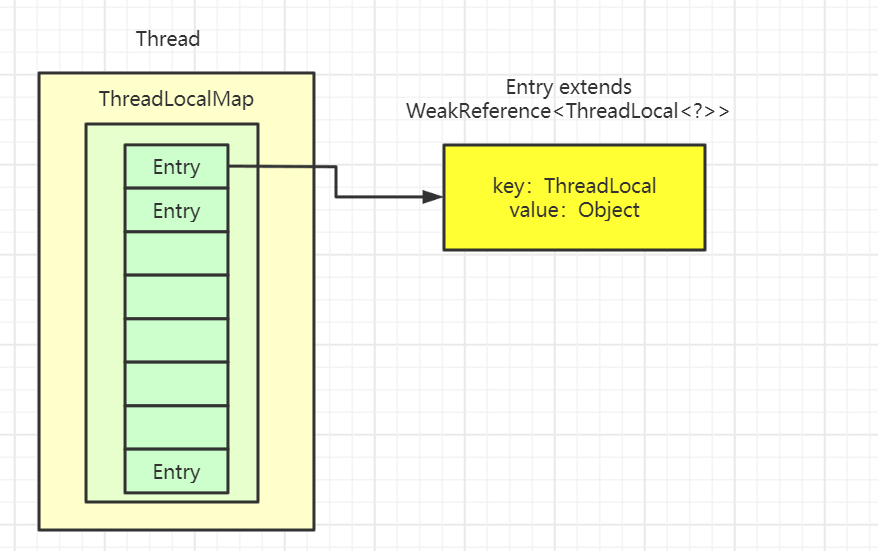
Thread クラスには型が ThreadLocal.ThreadLocalMap のインスタンス変数 threadLocals があり、つまり各スレッドは自分自身の ThreadLocalMap を持っています。
ThreadLocalMap は独自実装を持っており、その key を ThreadLocal と見なし、value はコード中に格納される値です(実際には key は ThreadLocal 本体ではなく、それの弱参照です)。
各スレッドが ThreadLocal に値を格納するときは自分の ThreadLocalMap に格納します。読み取りも ThreadLocal をキーとして自分の map の中で対応する key を探すことで、スレッドごとの隔離を実現します。
ThreadLocalMap は HashMap のような構造をしているものの、HashMap が配列+リストで実装されているのに対して、ThreadLocalMap にはリスト構造はありません。
また Entry の key は ThreadLocal<?> k で、WeakReference を継承しており、つまり弱参照タイプであることに留意します。
GC 後に key は null になるか?
冒頭の問題への回答として、ThreadLocal の key は弱参照です。では ThreadLocal.get() を実行し、GC が発生した後、key は null になるのでしょうか?
この問題を理解するには、Java の4種類の参照型を知る必要があります:
- 強参照:通常私たちが new で作るオブジェクト。強参照が存在する限り GC は回収しません。
- ソフト参照 SoftReference:メモリが不足する時に回収される可能性がある参照。
- 弱参照 WeakReference:GC が発生すると、弱参照だけに指されているオブジェクトは回収されます。
- 虚引用 PhantomReference:最も弱い参照で、ファントム参照は死亡通知をキューに受け取る用途だけのもの。
コードを反射で見て、GC 後の ThreadLocal のデータ状況を確認してみます:
public class ThreadLocalDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException { Thread t = new Thread(()->test("abc",false)); t.start(); t.join(); System.out.println("--gc后--"); Thread t2 = new Thread(() -> test("def", true)); t2.start(); t2.join(); }
private static void test(String s,boolean isGC) { try { new ThreadLocal<>().set(s); if (isGC) { System.gc(); } Thread t = Thread.currentThread(); Class<? extends Thread> clz = t.getClass(); Field field = clz.getDeclaredField("threadLocals"); field.setAccessible(true); Object ThreadLocalMap = field.get(t); Class<?> tlmClass = ThreadLocalMap.getClass(); Field tableField = tlmClass.getDeclaredField("table"); tableField.setAccessible(true); Object[] arr = (Object[]) tableField.get(ThreadLocalMap); for (Object o : arr) { if (o != null) { Class<?> entryClass = o.getClass(); Field valueField = entryClass.getDeclaredField("value"); Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent"); valueField.setAccessible(true); referenceField.setAccessible(true); System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o))); } } } catch (Exception e) { e.printStackTrace(); } }}結果は以下のとおり:
弱引用key:java.lang.ThreadLocal@433619b6,値:abc弱引用key:java.lang.ThreadLocal@418a15e3,値:java.lang.ref.SoftReference@bf97a12--gc后--弱引用key:null,值:def図のとおり、ここでは作成した ThreadLocal がいずれも値を指していない、すなわち参照がない状態です。そのため GC 後、key は回収され、デバッグの referent=null が見えます。
この問題を最初に見たとき、弱参照とガベージコレクションだけを思い浮かべると、確かに null になると考えがちですが、実際には ThreadLocal.get() 操作を行っている場合には強参照がまだ存在するため、key は null にはなりません。強参照が存在する限り、key は回収されず、value も存続します。もし強参照が存在しなければ、key は回収され、結果的にメモリリークが発生する恐れがあります。
ThreadLocal.set() のソースコード解説
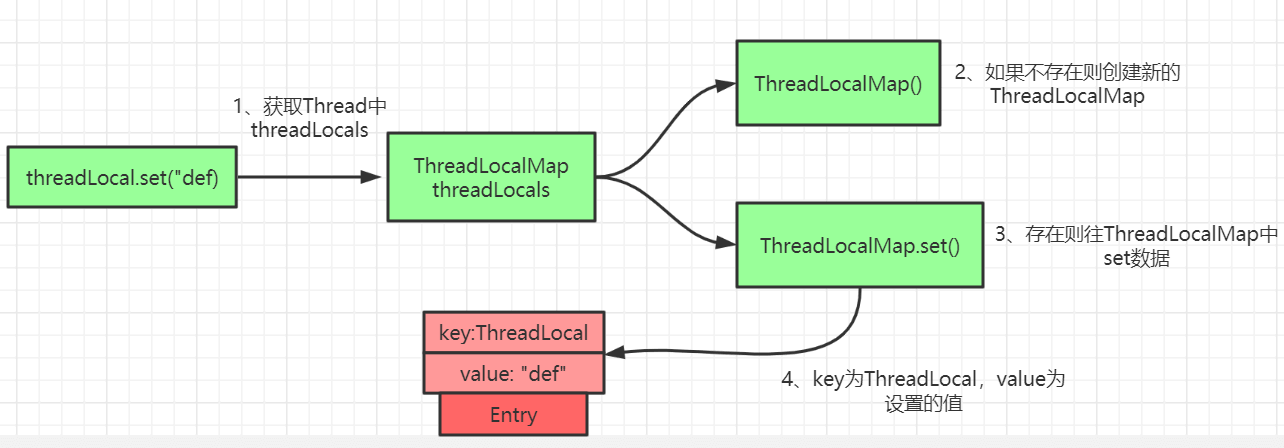
ThreadLocal の set メソッドの原理は上の図のとおりです。基本は ThreadLocalMap が存在するかどうかの判定と、ThreadLocal の set によるデータ処理です。
コードは以下のとおり:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value);}
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue);}核心は ThreadLocalMap 側のロジックにあります。
ThreadLocalMap のハッシュアルゴリズム
Map 構造である以上、ThreadLocalMap もハッシュテーブルの衝突を解決する独自のアルゴリズムを持ちます。
int i = key.threadLocalHashCode & (len-1);ThreadLocalMap のハッシュアルゴリズムはとてもシンプルで、ここの i が現在のキーがハッシュテーブル内で対応する配列のインデックス位置です。
ここで最も重要なのは、threadLocalHashCode の値の計算です。ThreadLocal には HASH_INCREMENT = 0x61c88647 という属性があります。
public class ThreadLocal<T> { private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
static class ThreadLocalMap { ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } }}ThreadLocal オブジェクトを新たに作成するたびに、ThreadLocal.nextHashCode の値は 0x61c88647 増加します。
この値は非常に特別で、フィボナッチ数、いわゆる黄金比です。ハッシュの増分としてこの数を用いると、ハッシュの分布が非常に均一になります。
ThreadLocalMap のハッシュ衝突
注記: 以下のすべての図では、緑色のブロック Entry は通常データ、灰色のブロックは Entry の key が null になりゴミ箱化済み、白色のブロックは Entry 自体が null です。
ThreadLocalMap では黄金比をハッシュ計算因子として用いて衝突の確率を大きく低減していますが、それでも衝突は発生します。
HashMap では衝突を解決する手法として、配列上にリンクリスト構造を作成します。衝突データはリストに付けられ、リストの長さが一定以上になると赤黒木に変換されます。
一方、ThreadLocalMap にはリンクリスト構造がありません。したがって衝突を HashMap の解法で扱うことはできません。
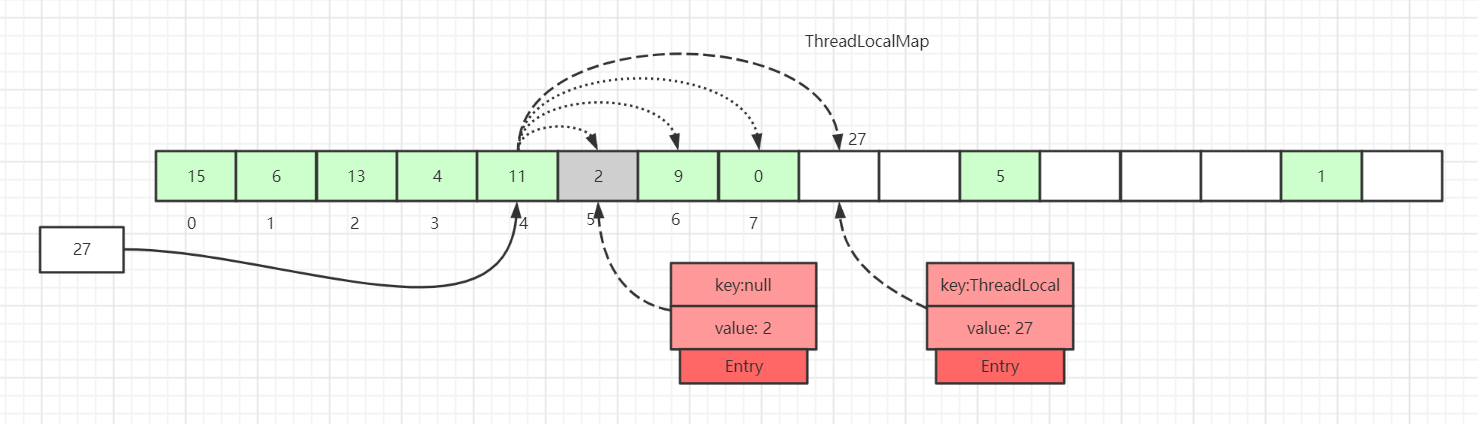
上図のように、値を 27 として挿入した場合、ハッシュ計算後にはスロット 4 に入るはずですが、すでにスロット 4 にはエントリが存在します。
この時点で直線的に後方へ探索して、Entry が null のスロットを見つけるまで探査を続け、現在の要素をそのスロットに格納します。もちろん、反復の途中で他にも、Entry が null ではない場合や、キーの値が等しい場合、あるいは Entry のキーが null の場合など、さまざまなケースの処理があります。後述で詳しく説明します。
また、キーが null のデータ(Entry=2 の灰色のブロック)も描かれています。これはキーが弱参照型であるために起こるデータです。set の過程で、キーが過期の Entry データに遭遇すると、実際には一度の探査型クリーニングが行われます。
ThreadLocalMap.set() の詳解
ThreadLocalMap.set() の原理図解
ThreadLocal のハッシュアルゴリズムを見た後、set がどのように実装されているかを見ていきます。
ThreadLocalMap にデータを設定(新規 or 更新)する場合、いくつかのケースに分かれ、それぞれ図で解説します。
-
ハッシュで計算されたスロットの
Entryデータが空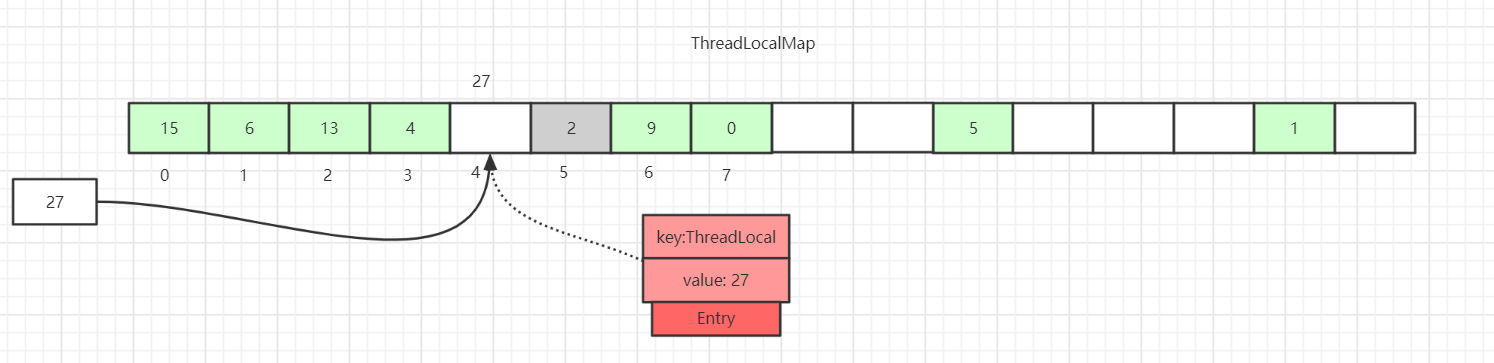
このスロットにそのままデータを格納します。
-
スロットのデータが空でなく、
keyが現在のThreadLocalがハッシュ計算で得たkeyと一致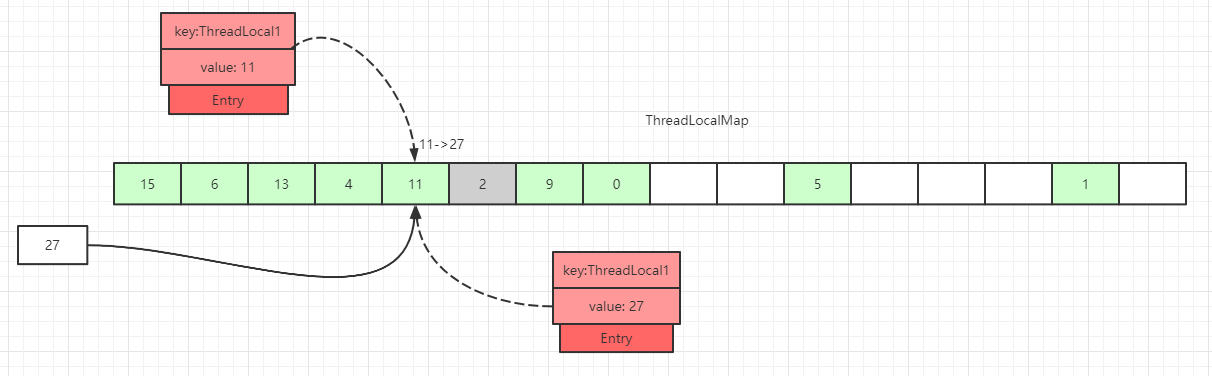
このスロットのデータを直接更新します。
-
スロットのデータが空でなく、後方へ走査中に
Entryが null になる前に、過去にkeyが過期のEntryが現れなかった場合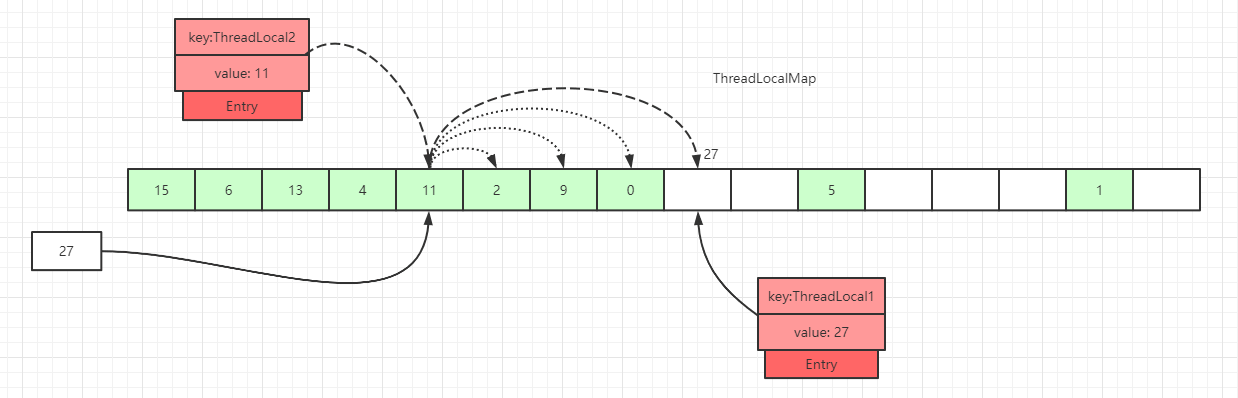
ハッシュ配列を走査し、線形に後方へ探査します。
Entryが null のスロットを見つけた場合にデータを格納します。途中、Entryのキーが等しいケースや、Entryのキーが null のケースなど、さまざまな分岐があります。 -
スロットのデータが空でなく、後方へ走査中に、過期の
Entryに遭遇した場合。下図のように、index=7のスロットのEntryのkeyが null となっているケース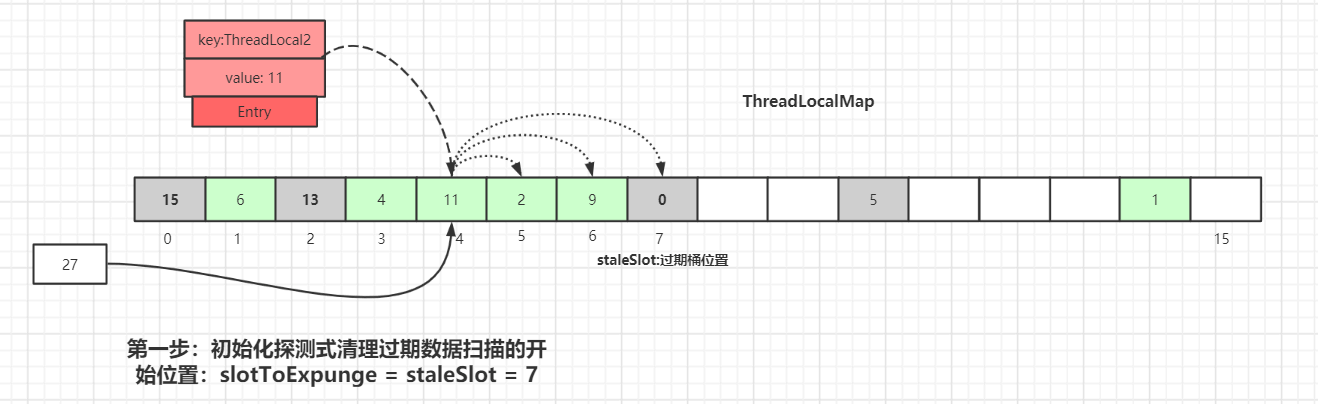
ハッシュ配列のインデックス 7 にある
Entryのkeyが null のため、このデータのkeyは GC によって回収済みであることを示します。この時点でreplaceStaleEntry()メソッドを実行します。replaceStaleEntry()は「期限切れデータを置換する」ロジックで、開始点を index=7 から探査を実行します。初期化:
slotToExpunge = staleSlot = 7現在の
staleSlotから前方へ走査して、他の期限切れデータを探し、過期データの開始スキャン位置slotToExpungeを更新します。forループはEntryが null になるまで、前方へ進みます。もし過期データが見つかれば、前方へ進み続け、
Entryが null になるまで探索を続け、探索開始位置を更新します。例えば上図ではslotToExpungeが 0 に更新されます。続いて
staleSlotの位置( index=7 )から後方へ走査し、同じキー値を持つEntryデータを見つけた場合は、値を更新して、staleSlotのエントリと交換します。これにより過期エントリをクリーニングします。後方を走査して同じキーを持つ
Entryが見つからなかった場合は、新しいEntryを作成してtable[staleSlot]を置換します。置換完了後も、過期要素のクリーニングを行います。主に
expungeStaleEntry()とcleanSomeSlots()の二つのメソッドが用いられます。
ThreadLocalMap の過期キーの探査型クリーニングの流れ
上記では、ThreadLocalMap の過期キーのクリーニングには「探索型クリーニング」と「ヒューリスティッククリーニング」の二つの方法があると説明しました。
探索型クリーニング
探索型クリーニング、すなわち expungeStaleEntry メソッドを見ていきます。ハッシュテーブル配列を前方へ走査して過期データをクリーニングします。過期データの Entry を null に設定します。途中で未過期データに遭遇した場合、それを再ハッシュして再配置します。もし再配置先がすでにデータを含んでいる場合は、過去のデータを現在の位置に近い「Entry=null」の桶へ移動します。これにより、再ハッシュ後の Entry データが正しい桶の位置に近づくようになります。操作の流れは以下のとおりです:
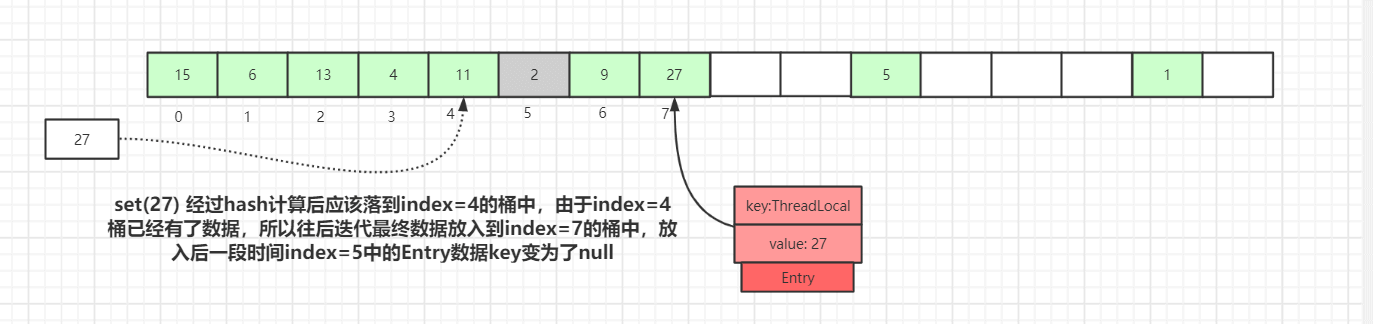
上図のように、set(27) はハッシュ計算後に index=4 の桶に落ちるはずですが、 index=4 には既にデータがあるため、後方へ走査して最終的に index=7 の桶に格納されます。格納直後、index=5 のデータのキーが null に変わります。
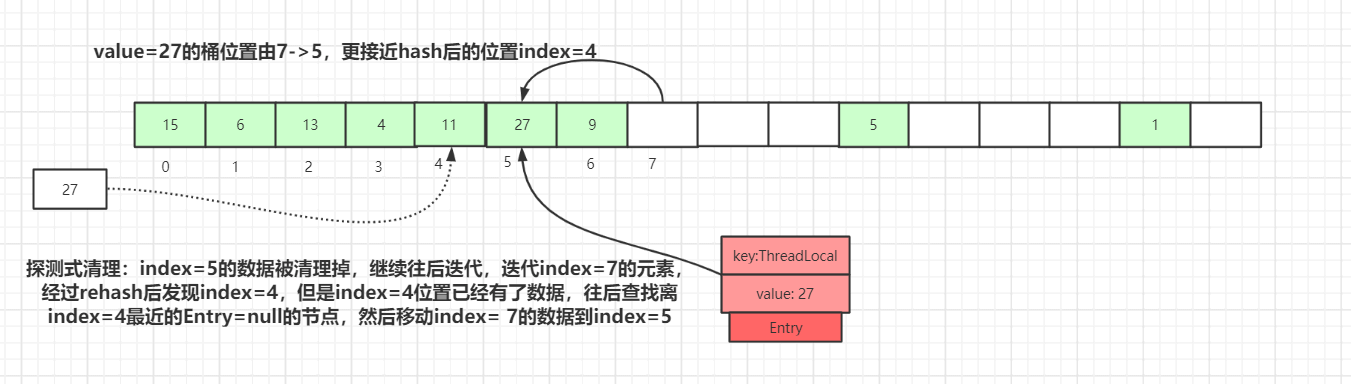
他のデータがさらに map に set されると、探索型クリーニングが発生します。
上図のように探索型クリーニングを実行すると、 index=5 のデータがクリアされ、さらに後方へ進んで index=7 の要素を見つけ、再ハッシュ後にこの要素は実際には index=4 に正しく落ちていることが分かります。しかしこの場所には既にデータがあるため、index=4 に最も近い「キーが null のエントリ」を探し、 index=5 に index=7 のデータを移動します。これにより、正しい位置 index=4 により近く配置されます。
この探索型クリーニングを一巡行うと、過期キーのデータはクリアされ、過期でないデータは再ハッシュ後により正しい位置に近づくため、全体の検索性能が向上します。
expungeStaleEntry() の具体的な実装は以下のとおりです:
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length;
// staleSlot のデータをクリアして size をデクリメント tab[staleSlot].value = null; tab[staleSlot] = null; size--;
Entry e; int i; // staleSlot を起点に後方へ走査 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // キーが null の場合はクリア if (k == null) { e.value = null; tab[i] = null; size--; } else { // キーが過去でない場合、ハッシュの新しい位置を計算して再配置 int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null;
while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i;}ここでは過去データの「通常の衝突データ」を処理します。反復の末尾に近い位置へと再配置が進むため、検索の効率が高まります。
ヒューリスティッククリーニング
探索型クリーニングの後に、作者が定義したヒューリスティッククリーニングが行われます。
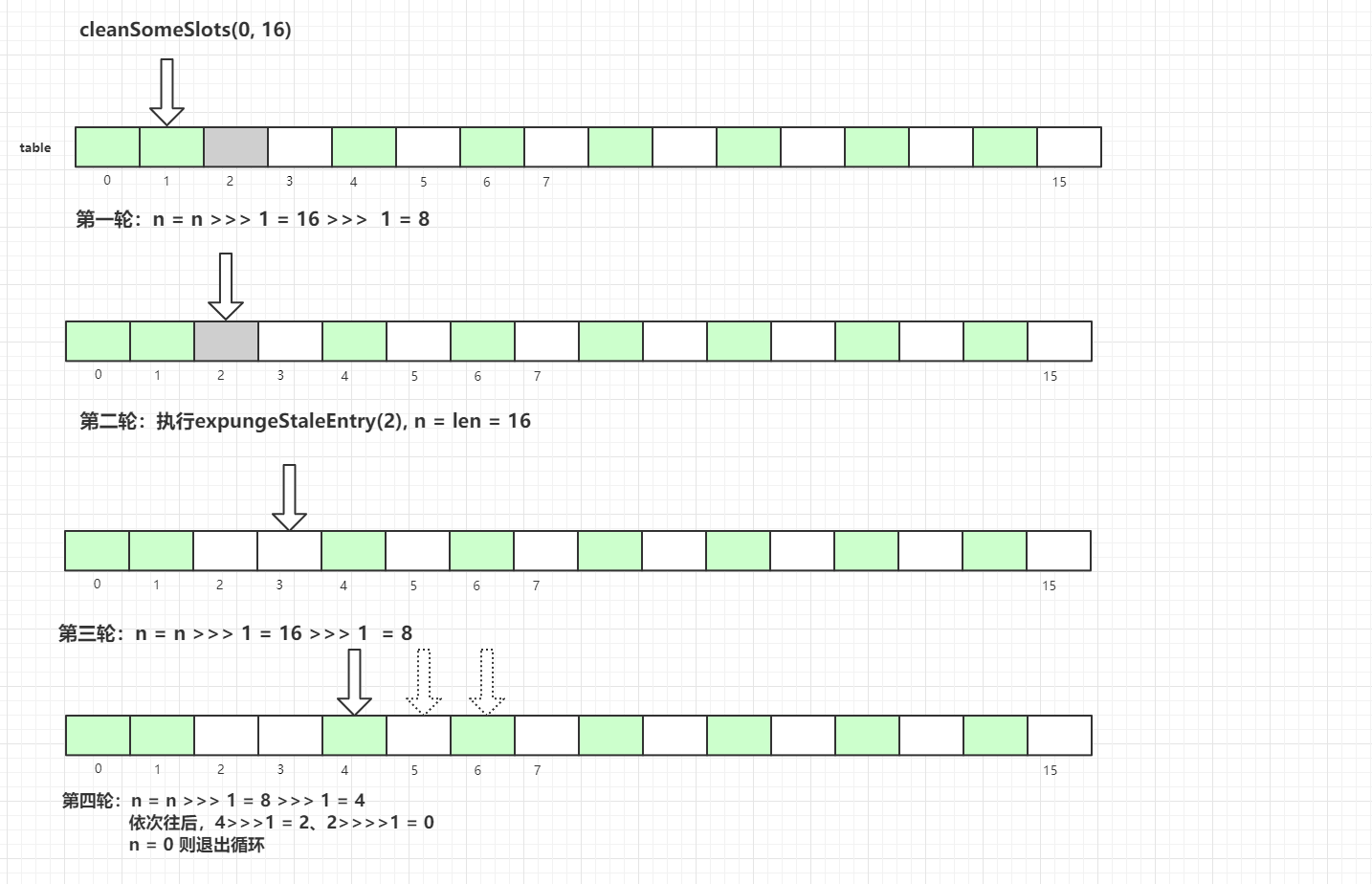
具体的なコードは以下です:
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed;}ThreadLocalMap の拡張機構
ThreadLocalMap.set() の末尾で、ヒューリスティッククリーニングを行ってもデータがクリアされず、かつ現在のハッシュテーブルの Entry の数が拡張閾値( len * 2 / 3 )に達した場合、rehash() を実行します。
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();rehash() の具体的実装は以下の通り:
private void rehash() { expungeStaleEntries();
if (size >= threshold - threshold / 4) resize();}
private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); }}- 探索型クリーニングを実行し、テーブル全体の過期データをクリアします。
- クリア後、
tableにキーが null のEntryが残っている可能性があるため、それをexpungeStaleEntryで整理します。 - さらに、
size >= threshold - threshold / 4、すなわちsize >= threshold * 3/4で拡張するかを判断します。
なお、rehash() の閾値は元々 size >= threshold です。面接でこの拡張機構を尋ねられたときには、この二段階の説明を必ず含めてください。
続いて resize() の実装。デモの都合上、oldTab.len=8 を例にします:
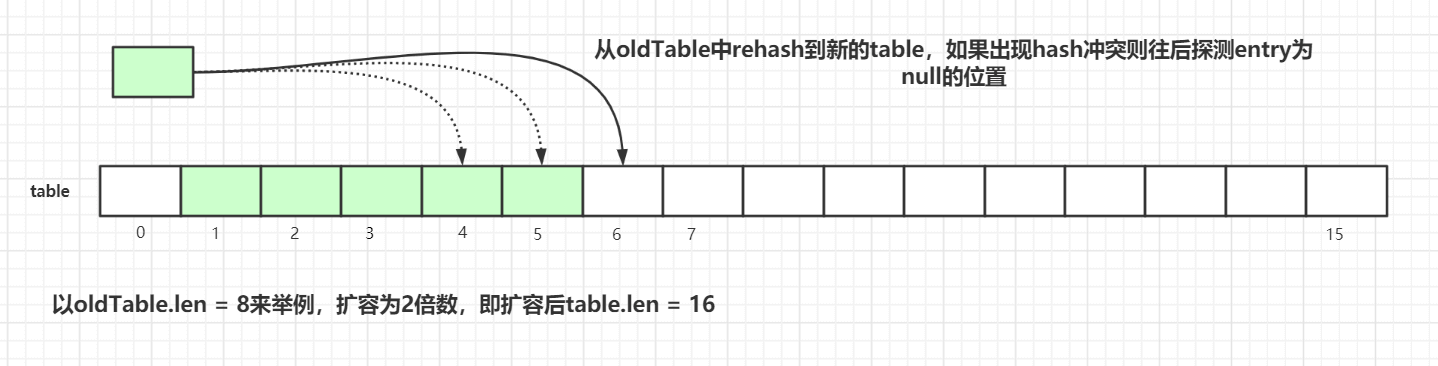
拡張後の tab のサイズは oldLen * 2 です。
- 古いハッシュ表を走査し、再計算したハッシュ位置に新しい
tab配列へ格納します。 - 衝突が発生した場合は、最近の
entryが null となるスロットを探して格納します。 - 走査完了後、古い
oldTabの全てのエントリデータを新しいtabに移します。 - 次回の拡張の閾値を再計算します。
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; int count = 0;
for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; } else { int h = k.threadLocalHashCode & (newLen - 1); while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } }
setThreshold(newLen); size = count; table = newTab;}ThreadLocalMap.get() 詳解
上記で set() の挙動を見ましたので、次は get() の仕組みを見ていきます。
ThreadLocalMap.get() の図解
-
キーの値を探索してハッシュからスロット位置を求め、そこに格納されている
Entry.keyが検索したkeyと一致すれば返します。 -
スロットの
Entry.keyが検索したkeyと一致しない場合:
例えば get(ThreadLocal1) を例にとると、ハッシュ計算後の正しいスロット位置は 4 ですが、 index=4 のスロットにはデータがあり、キーが ThreadLocal1 と等しくありません。そのため後方へと反復して探します。
index=5 へ到達した時、Entry.key が null になり、探査がトリガーされます。expungeStaleEntry() を実行すると、 index=5,8 のデータが回収され、 index=6,7 のデータは前へ移動します。移動後、再度 index=5 から後方へ反復を継ぎ、 index=6 でキーが等しい Entry を見つけます。
このようにして目的の Entry を見つけることができます。
ThreadLocalMap.get() のソースコード詳細
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e);}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null;}InheritableThreadLocal
ThreadLocal を使うと、非同期の場面では親スレッドで作成したスレッドローカルデータを子スレッドに共有できません。
この問題を解決するために JDK には InheritableThreadLocal が用意されています。例を見てみましょう:
public class InheritableThreadLocalDemo { public static void main(String[] args) { ThreadLocal<String> ThreadLocal = new ThreadLocal<>(); ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>(); ThreadLocal.set("父クラスのデータ:threadLocal"); inheritableThreadLocal.set("父クラスのデータ:inheritableThreadLocal");
new Thread(new Runnable() { @Override public void run() { System.out.println("子スレッドでの父スレッドの ThreadLocal データ:" + ThreadLocal.get()); System.out.println("子スレッドでの父スレッドの inheritableThreadLocal データ:" + inheritableThreadLocal.get()); } }).start(); }}出力結果:
子スレッドでの父スレッドの ThreadLocal データ:null子スレッドでの父スレッドの inheritableThreadLocal データ:父クラスのデータ:inheritableThreadLocal実装原理として、子スレッドは父スレッドの Thread の init の際にデータをコピーします。Thread#init は Thread のコンストラクタ内で呼び出され、inheritThreadLocals が有効な場合、親スレッドのデータを子スレッドへコピーします。
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { if (name == null) { throw new NullPointerException("name cannot be null"); }
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); this.stackSize = stackSize; tid = nextThreadID();}ただし InheritableThreadLocal には欠点があり、通常は非同期処理にはスレッドプールを用います。スレッドプールはスレッドを再利用するため、InheritableThreadLocal の伝搬は期待通りにはいきません。そのため Alibaba が公開している TransmittableThreadLocal というコンポーネントが解決策として提案されています。ここでは詳述を省きます。興味があれば調べてみてください。
ThreadLocal の実運用活用
ThreadLocal の使用シーン
私たちは現在のプロジェクトでログの記録に ELK+Logstash を利用し、最終的には Kibana で表示・検索を行っています。
分散システムが外部へサービスを提供する現状、プロジェクト間の呼び出し関係を traceId で結び付けることができます。しかし、異なるプロジェクト間で traceId をどう伝えるかが課題です。
ここでは org.slf4j.MDC を用いてこの機能を実現します。内部的には ThreadLocal によって実現されます。具体的な実装は以下のとおりです:
端末からサービス A へリクエストを送ると、サービス A は traceId という UUID 風の文字列を生成し、現在のスレッドの ThreadLocal にこの文字列を格納します。サービス B へ依頼する際には、traceId をリクエストのヘッダに書き込み、サービス B は受信時にヘッダに traceId があるかを判定し、存在すれば自分のスレッドの ThreadLocal に書き込みます。
requestId は各システムのチェーンを関連付けるキーです。システム間の呼び出しはこの requestId によって対応するチェーンを辿ることができます。その他にもいくつかのシーンがあります。
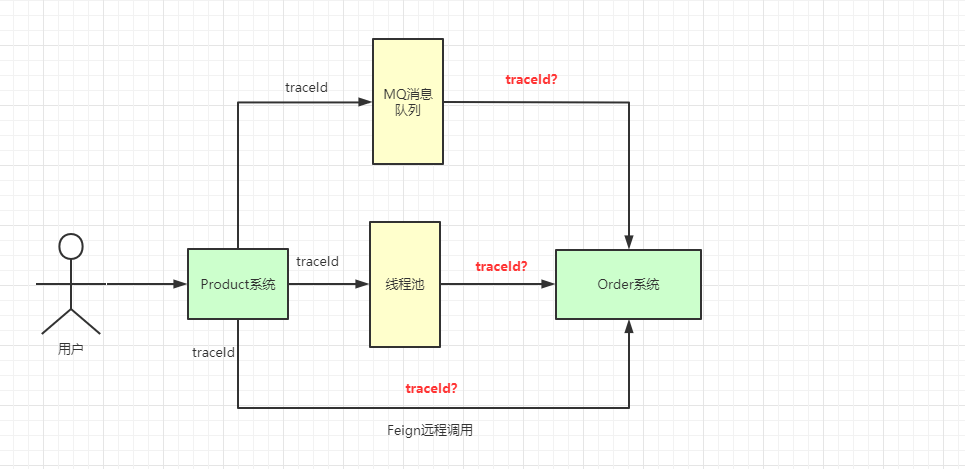
これらのシーンに対して、以下のような解決策があります。
Feign リモート呼び出しの解決策
サービスがリクエストを送る場合:
@Component@Slf4jpublic class FeignInvokeInterceptor implements RequestInterceptor {
@Override public void apply(RequestTemplate template) { String requestId = MDC.get("requestId"); if (StringUtils.isNotBlank(requestId)) { template.header("requestId", requestId); } }}サービスがリクエストを受け取る場合:
@Slf4j@Componentpublic class LogInterceptor extends HandlerInterceptorAdapter {
@Override public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) { MDC.remove("requestId"); }
@Override public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) { }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY); if (StringUtils.isBlank(requestId)) { requestId = UUID.randomUUID().toString().replace("-", ""); } MDC.put("requestId", requestId); return true; }}スレッドプールを用いた非同期呼び出しでの requestId の伝搬
MDC は ThreadLocal に基づいています。そのため、非同期処理の子スレッドは親スレッドの ThreadLocal データを取得できません。そこで、カスタムのスレッドプール実行器を用意し、run() メソッドを次のように変更します。
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
@Override public void execute(Runnable runnable) { Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> run(runnable, context)); }
@Override private void run(Runnable runnable, Map<String, String> context) { if (context != null) { MDC.setContextMap(context); } try { runnable.run(); } finally { MDC.remove(); } }}MQ を用いて第三者システムへメッセージを送る
MQ で送信するメッセージ体にカスタム属性 requestId を含めておき、受信側でそれを解析して使用します。
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります