


















Java 言語の特徴
- 簡単で学びやすい
- オブジェクト指向(カプセル化、継承、多態性)
- プラットフォーム非依存性( Java 仮想機械がプラットフォーム非依存性を実現)
- マルチスレッドをサポート( C++ には組み込みのマルチスレッド機能がなく、OS のマルチスレッド機能を呼び出してマルチスレッドプログラムを設計する必要があるが、Java はマルチスレッドのサポートを提供)
- 信頼性(例外処理と自動メモリ管理を備える)
- セキュリティ(Java 自体の設計にはアクセス修飾子、OS リソースへの直接アクセスを制限するなどの複数のセキュリティ防護機構が組み込まれている)
- 高効率性(Just In Time コンパイラ等の技術による最適化を通じて、Java の実行効率は依然として非常に優れている)
- ネットワークプログラミングをサポートし、非常に扱いやすい
- コンパイルと解釈の併存
- 動的性(Java は解釈型言語であり、実行時には多くの不確定な状況を実行時にしか決定できないため、これらを解釈実行するインタプリタが必要。さらに Java はコンパイル型言語でもあり、実行前にソースコードをバイトコードに変換する必要がある。このバイトコードは機械語には直接対応しておらず、特定のマシン用の機械語ではない。そのため、実行時にはインタプリタが必要となり、バイトコードを解釈して実行する。)
Write Once, Run Anywhere(ワンタイム作成、どこでも実行)
Java SE と Java EE
- Java SE(Java Platform, Standard Edition): Java プラットフォーム標準版。Java 言語の基礎で、Java アプリケーションの開発と実行を支えるコアライブラリと仮想機械などの核心コンポーネントを含む。Java SE はデスクトップアプリケーションや簡易的なサーバーアプリケーションの構築にも利用できる。
- Java EE(Java Platform, Enterprise Edition): Java プラットフォームのエンタープライズ版。Java SE を基盤として、企業向けアプリケーションの開発とデプロイを支援する標準と仕様(例えば Servlet、JSP、EJB、JDBC、JPA、JTA、JavaMail、JMS など)を含む。Java EE は分散型で移植性が高く、堅牢でスケーラブルかつ安全なサーバーサイドの Java アプリケーション(例:Web アプリケーション)の構築に利用できる。
簡単に言えば、Java SE は Java の基礎版、Java EE は Java の上位版。Java SE はデスクトップアプリや簡易的なサーバーアプリの開発に、Java EE は複雑なエンタープライズアプリケーションや Web アプリの開発に適している。
Java SE と Java EE の他に、Java ME(Java Platform, Micro Edition)もある。Java ME は Java のマイクロ版で、組み込み対応の家電機器向けアプリケーションの開発などに用いられる。Java ME は特に注目する必要はなく、存在を知っておけば十分。現在はあまり使われていない。
JVM vs JDK vs JRE
JVM
Java 仮想機(JVM)は Java バイトコードを実行する仮想機です。JVM には Windows、Linux、macOS などの各システム向けの特定実装があり、同じバイトコードを用いて同じ結果を得られることを目的としています。バイトコードと異なるシステムの JVM 実装が、Java 言語の「一度書けばどこでも実行」というキーとなる点です。
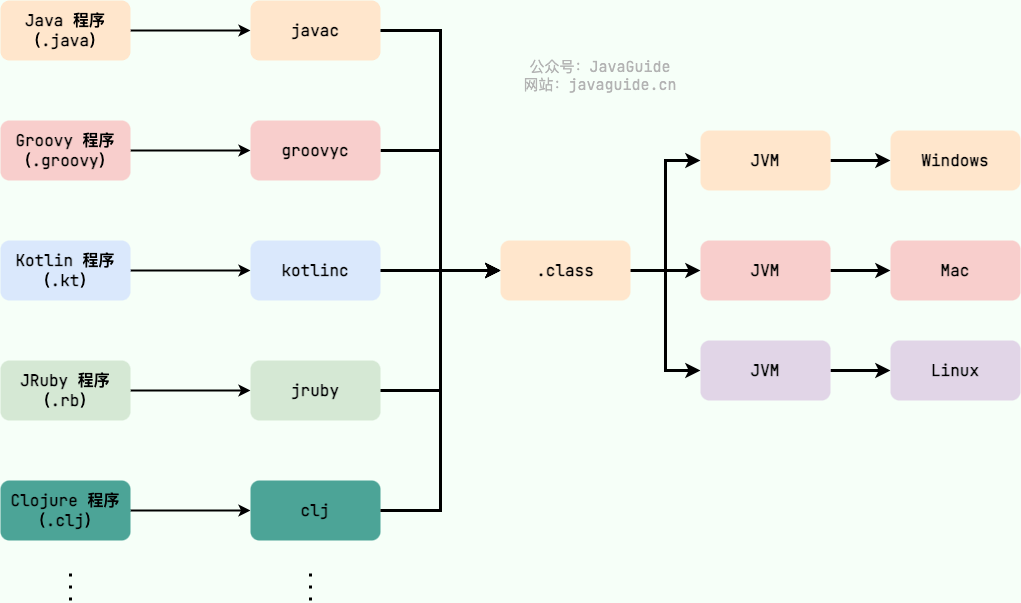
JVM は1つではありません!JVM 規格を満たしていれば、各社・組織・個人が自分たちの専用 JVM を開発できます。つまり普段触れている HotSpot VM は JVM 規格の1つの実装に過ぎません。
HotSpot VM のほかにも J9 VM、Zing VM、JRockit VM などの JVM があります。Wikipedia には一般的な JVM の比較が掲載されています:Comparison of Java virtual machines
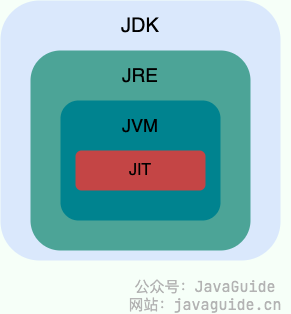
JDKとJRE
JDK(Java Development Kit)は、機能が揃った Java の SDK で、開発者向けの開発キット。JRE を含み、さらに java のソースコードをコンパイルするコンパイラ javac やその他のツール(例えば javadoc、jdb、jconsole、javap など)を含む。
JRE(Java Runtime Environment)は Java の実行時環境。既にコンパイル済みの Java プログラムを動作させるのに必要なすべてを含む集合で、主に Java 仮想機械(JVM)と Java 標準ライブラリを含む。
要するに、JRE は Java の実行時環境のみで、アプリケーションの実行と必要なライブラリを含む。一方 JDK は JRE を含みつつ、javac などの開発ツールを含むため、Java アプリケーションの開発とデバッグに使用される。Java のプログラミング作業(プログラムの作成・コンパイル、Java API ドキュメントの利用など)を行うには JDK が必要です。また、JSP の変換、反射など Java の機能を活用するアプリケーションには JDK の利用が必須となる場合があるため、Java アプリ開発を行う予定がなくても JDK の導入が必要になることがあります。
ただし、JDK 9 以降は JDK と JRE の区別は不要となり、モジュールシステム(JDK は 94 個のモジュールに再編成)と jlink(Java 9 と同時にリリースされた新しいコマンドラインツールで、特定アプリケーションに必要なモジュールだけを含むカスタム Java 実行イメージを生成)という形へ移行しました。さらに JDK 11 以降は Oracle は単独の JRE ダウンロードを提供していません。
バイトコードとは何か? バイトコードを採用する利点は?
Java では、JVM が理解できるコードをバイトコードと呼びます(拡張子 .class のファイル)。これは特定のプロセッサには依存せず、仮想マシンを対象としています。Java 言語はバイトコードを介して、従来の解釈型言語の実行効率の低さをある程度解決しつつ、解釈型言語の移植性を保っています。従って、Java プログラムの実行は比較的効率的であり(C、C++、Rust、Go などと比べるとまだ差はあるが)、バイトコードが特定のマシンに依存しないため、さまざまな OS のコンピュータ上で再コンパイル不要で実行できます。
バイトコードから機械語への変換(クラスファイル → マシンコード)には特に注意が必要です。JVM のクラスローダーがバイトコードを最初にロードし、インタプリタが逐次解釈実行しますが、この方法は比較的遅いです。よく呼ばれるメソッドやブロック(ホットコード)には後に JIT(Just-In-Time)コンパイラが導入され、JIT は「実行時コンパイル」に属します。
JIT コンパイラが初回のコンパイルを完了すると、バイトコードに対応する機械語を保存して次回は直接使用できます。機械語の実行速度は Java の解釈実行よりも高いことが多いです。だから Java は「コンパイルと解釈の共存する言語」とよく言われます。
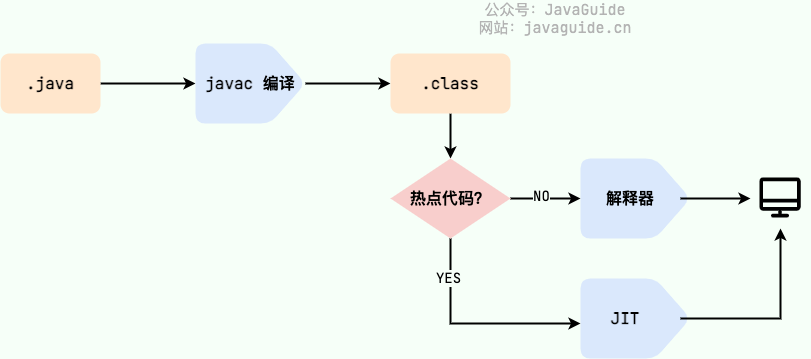
HotSpot は遅延評価(Lazy Evaluation)を採用し、二八の定理に従って、システム資源の大半を消費するのはほんの一部のコード(ホットコード)だけです。JIT はこの部分をコンパイルします。JVM はコードの実行状況に応じて情報を収集し、最適化を行うため、実行回数が増えるほど高速になります。
为什么说 Java 语言“编译与解释并存”?
実際、バイトコードについて話したときに既に触れましたが、重要なので再度触れます。
私たちは高級言語を実行方式で二つに分けられます。
- コンパイル型:ソースコードをコンパイラが一度だけそのプラットフォームの実行可能な機械語へ翻訳します。実行速度は速いが、開発効率は低い。代表的なコンパイル型言語には C、C++、Go、Rust など。
- 解説型:解釈器がコードを一行ずつ解釈して機械語に変換して実行します。開発効率は高いが、実行速度は遅い。代表的な解釈型言語には Python、JavaScript、PHP など。
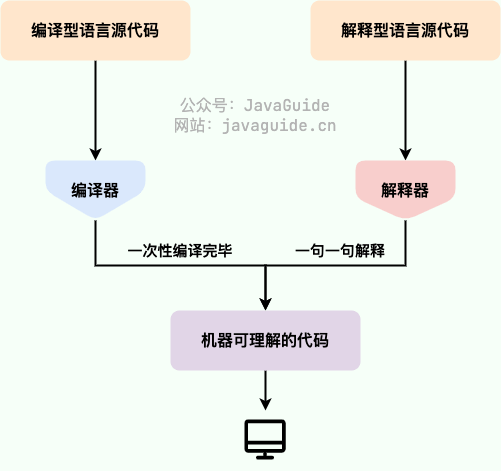
コンパイル型の効率を改善するために発展した即時コンパイル技術(JIT など)は、両者の差を縮小しました。この技術は、プログラムのソースコードをまずバイトコードへとコンパイルし、実行時にバイトコードを逐次解釈して機械語へと翻訳して実行します。Java と LLVM はこの技術の代表的な成果です。
AOT の利点とは?なぜすべてを AOT にするのか?
JDK 9 では新しいコンパイルモード AOT(Ahead of Time Compilation)が導入されました。JIT とは異なり、プログラムが実行される前に機械語へとコンパイルされる静的コンパイル(C、C++、Rust、Go などは静的コンパイル)。AOT は JIT の予熱などのオーバーヘッドを回避し、Java プログラムの起動を速くし、温度上昇の遅延を短くします。さらに、AOT はメモリ占有を削減し、Java プログラムのセキュリティを強化する(AOT コンパイル後のコードは逆コンパイル・改変されにくい)など、クラウドネイティブな場面にも適しています。
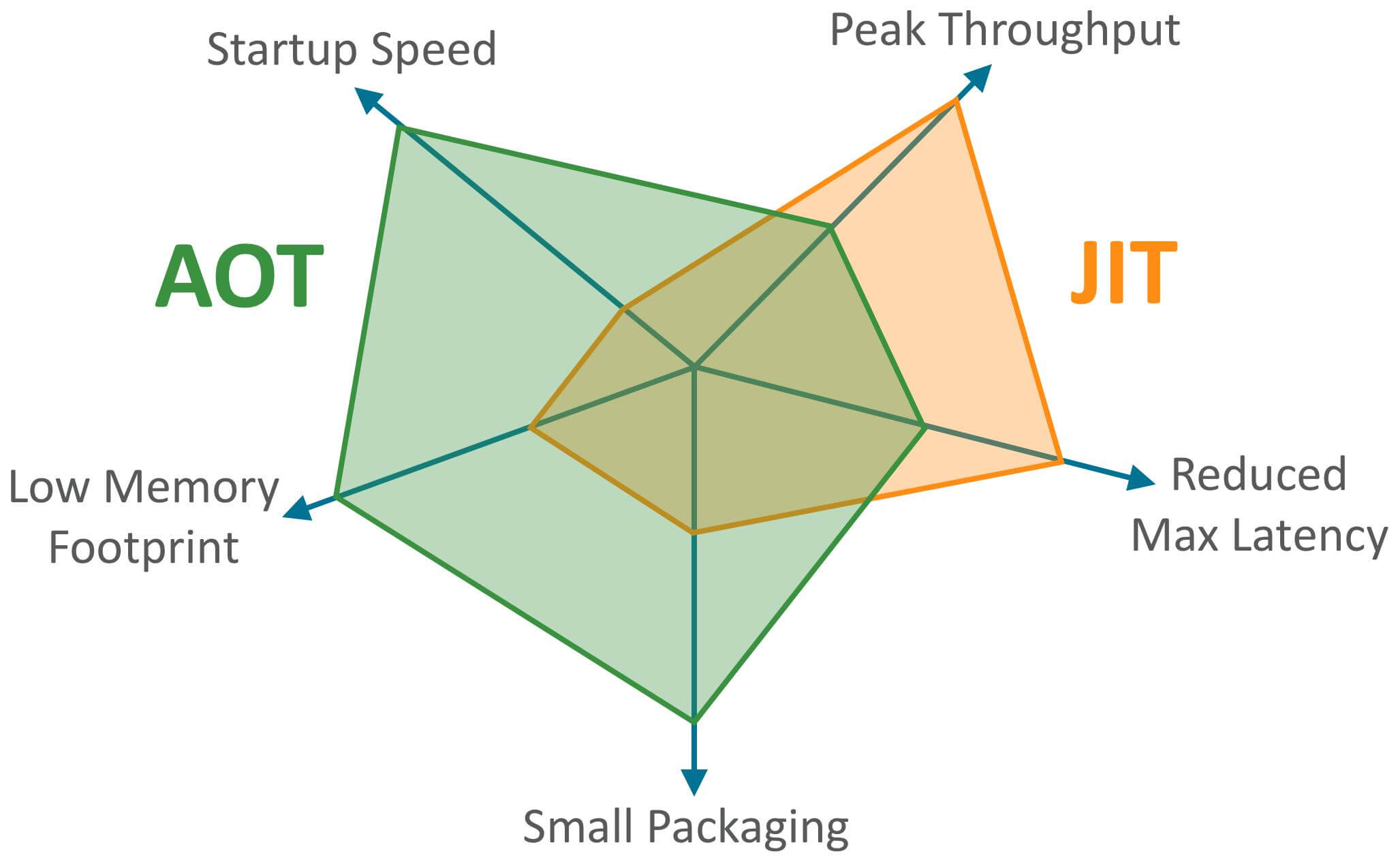
AOT の主な利点は起動時間、メモリ消費、パッケージサイズ。JIT の主な利点は、より高い極限処理能力を持ち、最大遅延を低減できる点です。
AOT に関連して GraalVM について触れるべきです。GraalVM は高性能な JDK(完全な JDK ディストリビューション)で、Java および他の JVM 言語、JavaScript、Python などの非 JVM 言語を実行できます。GraalVM は AOT コンパイルだけでなく JIT コンパイルも提供します。興味がある人は GraalVM の公式ドキュメントを確認してください:https://www.graalvm.org/latest/docs/。
AOT には多くの利点があるが、なぜ全部を AOT で実行しないのか?
前述の JIT と AOT の比較を見て分かるように、両方には利点があります。AOT は現在のクラウドネイティブ環境には適しており、マイクロサービスのサポートにも適しています。しかし、AOT コンパイルは Java の動的機能(反射、動的プロキシ、動的ロード、JNI など)を一部サポートできません。一方、多くのフレームワークやライブラリ(例:Spring、CGLIB など)はこれらの機能を使っています。すべてを AOT にすると、これらのフレームワークやライブラリを利用できなくなる可能性があり、適切な適応と最適化が必要になります。例えば、CGLIB のダイナミックプロキシは ASM 技術を使用していますが、AOT の場合 ASM のような技術を事前に実装できなくなる可能性があります。動的機能をサポートするためには、JIT 即時コンパイラを選択するのが現実的です。
Oracle JDK vs OpenJDK
この問題に触れる前に OpenJDK を使ったことがない人もいるかもしれません。
最初に、2006 年に SUN が Java をオープンソース化し OpenJDK が生まれました。2009 年に Oracle が Sun を買収し、OpenJDK を基に Oracle JDK を作りました。Oracle JDK はオープンソースではなく、初期の数バージョン(Java 8 〜 Java 11)は OpenJDK に対していくつか独自機能やツールを追加していました。
次に、Java 7 の場合、OpenJDK と Oracle JDK は非常に近い関係です。Oracle JDK は OpenJDK 7 をベースに構築され、いくつかの小さな機能を追加し、Oracle のエンジニアが保守に参加しています。
簡単にまとめると、Oracle JDK と OpenJDK の違いは以下のとおりです。
- 开源か否か:OpenJDK は完全にオープンソース、Oracle JDK は OpenJDK をベースにした実装で、完全にはオープンではない。OpenJDK のオープンソースプロジェクトは https://github.com/openjdk/jdk
- 無料かどうか:Oracle JDK には無料の版があるが、一般的には期間制限がある。JDK8u221 以前はアップデートを止めなければ無期限で無料。OpenJDK は完全に無料。
- 機能性:Oracle JDK は OpenJDK をベースに独自の機能やツールを追加していたが、Java 11 以降は機能はほぼ同等。
- 安定性:OpenJDK は LTS サービスを提供しない。一方 Oracle JDK はおおよそ3年ごとに LTS 版を提供して長期サポートを行う。
- ライセンス:Oracle JDK は BCL/OTN、OpenJDK は GPL v2。
それでは、なぜ Oracle JDK が良いのに OpenJDK もあるのか?
- OpenJDK はオープンソースであり、必要に応じて改変・最適化が可能(例:Alibaba が OpenJDK をベースに Dragonwell8 を開発)。
- OpenJDK は商用無料。
- OpenJDK の更新頻度は速い。Oracle JDK は通常6か月ごと、新しいバージョンを公開するのに対し、OpenJDK は通常3か月ごと。
Oracle JDK と OpenJDK の選択はどうするべきか?
OpenJDK または OpenJDK ベースのディストリビューションを選ぶことを推奨します。例えば AWS の Amazon Corretto、Alibaba の Alibaba Dragonwell など。
拡張情報:
- BCL(Oracle Binary Code License Agreement):JDK の使用は可能だが、改変不可。
- OTN(Oracle Technology Network License Agreement):11 以降の新しい JDK はこの契約を使用。私的には利用可能だが商用には費用が必要。
Java と C++ の違い?
- Java はポインタを直接使ってメモリへアクセスする機能を提供せず、メモリの安全性が高い
- Java のクラスは単一継承、C++ は多重継承をサポート
- Java のクラスは多重継承ができないが、インタフェースは多重継承可能
- Java には自動メモリ管理(GC)あり、手動解放は不要
- C++ はメソッドのオーバーロードと演算子のオーバーロードを同時にサポートするが、Java はメソッドのオーバーロードのみをサポート(演算子のオーバーロードは設計思想に反する面がある)
基本文法
注釈にはどのような形式があるか?
Java には三種類のコメントがあります。
- 単一行コメント:
//で行末まで - 複数行コメント:
/*で開始、*/で終了 - ドキュメント注釈:
/**で開始、*/で終了。中身はコメントですが、javadocツールで一定のドキュメントを生成できます
よく使われるのは単一行コメントとドキュメント注釈で、複数行コメントは実務での使用は比較的少ない。
コードを書く際、コード量が少ない場合は自分やチームの他のメンバーがコードを理解しやすいですが、プロジェクト構造が複雑になるとコメントが必要になります。コメントは実行されません(コンパイラがコンパイル前にコード内のすべてのコメントを削除し、バイトコードにはコメントは含まれません)。コメントはプログラマー自身のための説明書であり、コード間のロジック関係を読み解く手助けになります。したがって、プログラムを書く際にコメントを付けるのは非常に良い習慣です。
コードのコメントは、詳細すぎるのが良いとは限りません。実際には良いコード自体がコメントの役割を果たすことが多く、規範的で美しく整えられたコードが不必要なコメントを減らします。
表現力が十分なプログラミング言語なら、コメントを過度に使う必要はなく、コードで語るべきです。
識別子とキーワードの違いは?
プログラムを作成する際、多くの名前を付ける必要があるため、識別子という概念が生まれます。識別子とは単なる「名前」です。
いくつかの識別子には、Java 言語が特別な意味を与えられており、特定の場所でのみ使用できるものがあります。これらは「キーワード」です。要するに、キーワードは特別な意味を持つ識別子です。
Java 言語のキーワードには何がある?
- クラスタイプのキーワードおよびアクセス制御 private/protected/public
- クラス、メソッド、変数の修飾子 abstract/class/extends/final/implements/interface/native/new/static/strictfp/synchronized/transient/volatile/enum
- プログラムの制御 break/continue/return/do/while/if/else/for/instanceof/switch/case/default/assert
- 例外処理 try/catch/throw/throws/finally
- パッケージ関連 import/package
- 基本型 boolean/byte/char/double/float/int/long/short
- 引用 super/this/void
- 予約語 goto/const
Tips: すべて小文字のキーワードで、IDEでは特殊な色で表示されます。
default は特別なキーワードで、プログラム制御、クラス/メソッド/変数の修飾子、アクセス制御のいずれにも属します。
- プログラム制御では、switch でどのケースにも該当しない場合に default を使ってデフォルトの分岐を作成できます。
- クラス、メソッド、変数の修飾子では、JDK8 以降、デフォルトメソッドが導入され、default キーワードでデフォルト実装を定義できます。
- アクセス制御では、あるメソッドの修飾子が一切付いていなければデフォルト修飾子が自動的に与えられますが、この修飾子を付けるとエラーになります。
注意:true、false、null はキーワードのように見えますが、リテラルであり、識別子としては使用できません。
自増自減演算子
コードを書く過程で、整数型の変数を 1 増やす、あるいは 1 減らす必要がある状況はよくあります。Java はこのような表現に用いる特殊な演算子を提供します。自増演算子(++)と自減演算子(--)です。
++ と -- 演算子は、変数の前に置くと「前置演算子」となり、先に増減してから代入します。変数の後ろに置くと「後置演算子」となり、先に代入してから増減します。
シフト演算子
シフト演算子は最も基本的な演算子の一つで、ほぼ全ての言語に含まれる演算子です。シフト演算では、被演算データを二進法の数として扱い、左または右へ一定のビット数だけ動かします。シフト演算子はフレームワークや JDK 自身のソースにも多く使われており、HashMap(JDK1.8)の hash メソッドのソースコードにも用いられています。
static final int hash(Object key) { int h; // key.hashCode(): ハッシュ値(hashcode)を返す // ^: ビットエクスクルーシブOR // >>>: 符号ビットを無視した右シフト return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }Java には三種類のシフト演算子があります。
<<:左シフト演算子。num << 1 は num × 2 に相当>>:算術右シフト演算子。num >> 1 は num ÷ 2 に相当>>>:論理右シフト演算子。符号ビットを無視して、空位を 0 で補う
Java のコード内で <<、>>、>>> を用いて生成される命令コードは実行効率が高くなります。最も基本的なシフト演算子を理解することは、コードでの利用だけでなく、ソースコードのシフト演算子を含む箇所の理解にも役立ちます。
ただし、double、float の二進表現は特別な点があるため、シフト操作には使えません。実際のシフト操作は int または long 型のみを対象としており、short、byte、char の各型をシフトする前には、まず int に変換されてから操作されます。
シフトのビット数が、値が占めるビット数を超えるとどうなるか?int の左/右シフトのビット数が 32 以上の場合は、まず剰余(%)をとってから左/右シフトを行います。つまり、左/右に 32 ビット動かすと実質的には何も起きない(32%32=0)、42 ビットの場合は 10 ビット分左/右シフトしたことになります(42%32=10)。long 型では 64 ビットなので、剰余の基数は 64 になります。
continue、break、return の違いは?
ループ構造において、ループ条件が成り立たない、または繰り返し回数が満了した場合にはループは通常終了します。しかし、ループの途中で特定の条件が満たされた場合に、ループの実行を事前に終了させたいことがあります。これには以下のキーワードを使用します。
- continue:現在のこのループの反復をスキップして、次の反復へ進む
- break:ループ全体を抜けて、ループの後の文へ進む
- return:現在のメソッドを抜けて、そのメソッドの実行を終了する。
- return;:値を返さない関数の場合
- return value;:特定の値を返す、戻り値がある関数の場合
基礎データ型
Java には 8 種の基本データ型があり、以下のとおりです。
- 6 種の数値型:
- 4 種の整数型:byte、short、int、long
- 2 種の浮動小数点型:float、double
- 1 種の文字型:char
- 1 種のブール型:boolean
この 8 種の基本データ型のデフォルト値と占有スペースは以下のとおりです。
| 基本タイプ | 桁数 | バイト | デフォルト値 | 値の範囲 |
|---|---|---|---|---|
| byte | 8 | 1 | 0 | -128 ~ 127 |
| short | 16 | 2 | 0 | -32768(-2^15) ~ 32767(2^15 - 1) |
| int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
| long | 64 | 8 | 0L | -9223372036854775808(-2^63) ~ 9223372036854775807(2^63 -1) |
| char | 16 | 2 | ’u0000’ | 0 ~ 65535(2^16 - 1) |
| float | 32 | 4 | 0f | 1.4E-45 ~ 3.4028235E38 |
| double | 64 | 8 | 0d | 4.9E-324 ~ 1.7976931348623157E308 |
| boolean | 1 | false | true、false |
ご覧のとおり、byte、short、int、long が表現できる最大の正数はすべて 1 減っています。これは、二進符号化表現(補数表現)では最高位が符号を表すため(0 は正、1 は負)、数値部分は残りのビットで表現されるためです。最大の正数を表すには、最高位以外の全ビットを 1 にする必要があります。もしこれに 1 を加えるとオーバーフローして負数になります。
boolean の場合、公式ドキュメントでは値域が明確には定義されていません。JVM の実装依存で 1 ビット相当の使用を想定しますが、実際には効率を考慮して扱われます。
また、Java の各基本型のサイズは、マシンのアーキテクチャの違いによって変わりません。この不変性が、Java が多くの他の言語より移植性が高い理由の一つです。
注意:
- Java で long 型の数値を扱う場合は、末尾に L を付ける必要があります。付けないと int として解釈されます。
char a = 'h'は char、String a = "hello"は String。
この 8 種類の基本データ型には、それぞれ以下のラッパークラスが対応します:Byte、Short、Integer、Long、Float、Double、Character、Boolean。
基本タイプとラッパー型の違い?
- 用途:定数やローカル変数を除き、パラメータやオブジェクトの属性など、基本型を直接用いる機会は少なく、ラッパー型はジェネリクスに使えるが、基本型は使えない。
- ストレージ:基本データ型の局所変数は JVM のスタックの局所変数領域に、基本データ型のメンバ変数(static でない場合)はヒープに格納される。ラッパー型はオブジェクト型であり、ほとんどすべてオブジェクトはヒープに存在します。
- 占有領域:ラッパー型(オブジェクト型)は基本データ型よりも多くの領域を占有する傾向がある。
- デフォルト値:メンバ変数のラッパー型は値を設定されていない場合は null、基本型にはデフォルト値があり null ではない。
- 比較:基本データ型は
==で値を比較します。ラッパー型はオブジェクトの参照を比較します。整数型のラッパー同士の値比較は常にequals()を使用します。
なぜ「ほとんどのオブジェクトはヒープ上にある」と言われるのかというと、HotSpot VM の JIT 最適化の影響で、オブジェクトが外部へ逃げ出さない場合はスタック上に割り当てることでパフォーマンスを向上させるため、ヒープ上の割り当てを避ける最適化(スカラー置換など)を行うことがあるためです。
注意:基本データ型がスタックに格納されるというのはよくある誤解です。基本データ型の格納場所は作用域と宣言方法に依存します。局所変数ならスタック、メンバ変数ならヒープに格納されます。
ラッパー型のキャッシュ機構を理解していますか?
Java の基本データ型のラッパー型の大半は、パフォーマンスを向上させるためのキャッシュ機構を利用します。
Byte、Short、Integer、Long の 4 つのラッパークラスは、デフォルトで [-128, 127] の範囲の値のキャッシュを持ち、Character は [0,127] の値のキャッシュを持ち、Boolean は True/False を直接返します。
範囲を超える場合は新しいオブジェクトが生成されます。キャッシュの範囲の大きさは、パフォーマンスとリソースのバランスによって決まります。
Float、Double の 2 つの浮動小数点数のラッパーにはキャッシュ機構は実装されていません。
覚えておくべきこと:すべての整数型ラッパーオブジェクト間の値の比較は equals() を使用して比較します。

自動箱詰めと自動的なアンボックス(オートボクシングとアンボクシング)を理解していますか?原理は?
- ボックシング(Boxing):基本型を、それに対応する参照型で包むこと
- アンボックス(Unboxing):ラッパー型を基本データ型に変換すること
Integer i = 10; // ボックス化int n = i; // アンボックスバイトコードから見ると、ボックシングは実際にはラッパークラスの valueOf() メソッドを呼び出して行われ、アンボックスは xxxValue() メソッドを呼び出して行われます。従って、
Integer i = 10はInteger i = Integer.valueOf(10)と等価int n = iはint n = i.intValue()と等価
頻繁なボックス化/アンボックス化はシステムのパフォーマンスに重大な影響を与える可能性があるため、不要な変換は避けるべきです。
浮動小数点数の演算精度の問題をどう解決するか?
BigDecimal は浮動小数点数の演算を正確に行い、精度を失いません。実務的には、小数点の正確な演算が必要なケース(例えば金額の計算など)では通常 BigDecimal を使用します。
BigDecimal a = new BigDecimal("1.0");BigDecimal b = new BigDecimal("0.9");BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.1 */System.out.println(y); /* 0.1 */System.out.println(Objects.equals(x, y)); /* true */long より大きい整数をどう表すか?
基本的な数値型には、それぞれ表現範囲があり、それを超えると値のオーバーフローのリスクがあります。
Java では、64 ビットの long が最大の整数型です。
long l = Long.MAX_VALUE;System.out.println(l + 1); // -9223372036854775808System.out.println(l + 1 == Long.MIN_VALUE); // trueBigInteger は内部で int[] 配列を用いて任意の大きさの整数を格納します。
通常の整数型の演算に比べ、BigInteger の演算は相対的に低速になります。
変数
メンバー変数とローカル変数の違いは?
- 形式:メンバー変数はクラスに属し、ローカル変数はコードブロックまたはメソッド内で定義される変数またはメソッドの引数。メンバー変数は
public、private、staticなどの修飾子を付けることができますが、ローカル変数にはアクセス修饰子やstaticは適用できません。ただし、finalは両方に付けることができます。 - 保存場所:メンバー変数が
static修飾されている場合はクラスに属し、そうでなければインスタンスに属します。オブジェクトはヒープに存在しますが、ローカル変数はスタックに存在します。 - 生存期間:メンバー変数はオブジェクトの一部として存在し、オブジェクトの作成と同時に存在します。ローカル変数はメソッドの呼び出し時に自動的に生成され、メソッドの呼び出しが終了すると消滅します。
- デフォルト値:メンバー変数には初期値が自動的に設定されます(
final修飾子のメンバー変数を除く)。ローカル変数にはデフォルト値は自動設定されません。
なぜメンバー変数にはデフォルト値があるのですか?
- もしデフォルト値が無ければ、変数にはランダムな値(メモリ上の未初期化値)が格納され、読み取ると不確定な動作になる可能性があるためです。
- デフォルト値には manual(手動)と自動の二つの設定手段があります。手動で値が設定されていない場合、自動でデフォルト値が設定されます。リフレクションを用いてランタイム時に設定することは可能ですが、ローカル変数には自動的なデフォルト値はありません。
- コンパイラの観点からは、ローカル変数は未初期化だと判断しやすく、エラーになります。一方、メンバー変数は実行時に値が代入される可能性があるため、誤報を避けるために自動初期化を採用します。
静的変数にはどんな役割があるか?
静的変数は static 修飾子で宣言された変数です。クラスのすべてのインスタンスで共有され、クラスがいくつオブジェクトを作成しても同じ静的変数を共有します。つまり、静的変数は一度だけメモリに割り当てられ、複数のオブジェクトを作っても同じ値を共有します。
静的変数はクラス名を用いてアクセスします(例えば StaticVariableExample.staticVar)。
public class StaticVariableExample { // 静的変数 public static int staticVar = 0;}通常、静的変数は final キーワードを付けて定数として扱います。
字符型常量と字符串常量の違いは?
- 形式: 字符型常量はシングルクォート、文字列常量はダブルクォートで定義します。
- 含意: 字符型常量は整数値( ASCII 値)として式に参加可能。文字列常量はメモリ上のある位置を指すアドレス値を表します。
- 占有メモリサイズ: 字符型常量は 2 バイト、文字列常量は複数バイト以上を要します。
注意:Java の char は 2 バイトを占有します。
文字型の定数と文字列定数の例:
public class StringExample { // 文字型定数 public static final char LETTER_A = 'A';
// 文字列定数 public static final String GREETING_MESSAGE = "Hello, world!"; public static void main(String[] args) { System.out.println("字符型常量占用的字节数为:"+Character.BYTES); // 2 System.out.println("字符串常量占用的字节数为:"+GREETING_MESSAGE.getBytes().length); // 13 }}メソッド
メソッドの戻り値とは? メソッドにはどんな型があるのか?
メソッドの戻り値 は、メソッド本体のコードが実行された結果として得られる値のことです(そのメソッドが結果を返す可能性がある場合)。戻り値の役割は、結果を受け取り、それを他の操作に利用できるようにすることです。
以下のように、戻り値とパラメータの型によってメソッドを分類できます。
- 引数なし・戻り値なしのメソッド
public void f1() { //......}// 下面のメソッドも戻り値なし、return を用いていますpublic void f(int a) { if (...) { // メソッドの実行を終了、以降の出力文は実行されない return; } System.out.println(a);}- 引数あり・戻り値なしのメソッド
public void f2(Parameter 1, ..., Parameter n) { //......}- 引数なし・戻り値ありのメソッド
public int f3() { //...... return x;}- 引数あり・戻り値ありのメソッド
public int f4(int a, int b) { return a * b;}静的メソッドはなぜ非静的メンバーを呼べないのか?
これは JVM の知識と深く関係します。主な理由は以下のとおりです。
- 静的メソッドはクラスに属します。クラスをロードした時点でメモリが割り当てられ、クラス名を介して直接アクセスできます。一方、非静的メンバーはインスタンスに属し、オブジェクトがインスタンス化された後にしか存在しません。従って、クラスのインスタンスが存在しない状態で非静的メンバーへアクセスするのは不正です。
- クラスの非静的メンバーが存在しないときに静的メソッドはすでに存在します。このとき、まだメモリ上に存在しない非静的メンバーを呼び出すことは不正です。
public class Example { // 定義された文字型定数 public static final char LETTER_A = 'A';
// 定義された文字列定数 public static final String GREETING_MESSAGE = "Hello, world!";
public static void main(String[] args) { // 文字型定数の値を出力 System.out.println("字符型常量的值为:" + LETTER_A);
// 文字列定数の値を出力 System.out.println("字符串常量的值为:" + GREETING_MESSAGE); }}静的メソッドとインスタンスメソッドの違いは?
1、呼び出し方
外部から静的メソッドを呼ぶ際には、クラス名.メソッド名 の方法、あるいは オブジェクト.メソッド名 の方法を使えますが、インスタンスメソッドは後者の方法のみです。つまり、静的メソッドはオブジェクトを生成せずとも呼び出せます。
ただし、静的メソッドを呼ぶ際に オブジェクト.メソッド名 の形式を使うのは避けるべきです。静的メソッドは特定のオブジェクトに属するものではなく、クラス自体に属します。
したがって、静的メソッドの呼び出しには通常、クラス名.メソッド名 の形式を用いることを推奨します。
public class Person { public void method() { //...... }
public static void staicMethod(){ //...... } public static void main(String[] args) { Person person = new Person(); // インスタンスメソッドの呼び出し person.method(); // 静的メソッドの呼び出し Person.staicMethod(); }}2、クラスメンバーへのアクセス制限の有無
静的メソッドが同じクラスのメンバーへアクセスする際には、静的メンバー(静的変数・静的メソッド)に限定され、インスタンスメンバーにはアクセスできません。一方、インスタンスメソッドはこの制限を受けません。
重載とオーバーライドの違いは?
重複(オーバーロード)は、同じクラス内で引数の型・数・順序が異なる同名メソッドが複数存在する状態を指します。戻り値や修飾子は異なっていても良い。
オーバーライド(オーバーライド / override)は、サブクラスが父クラスから継承した同名・同引数リストのメソッドを、子クラスで再実装することを指します。
オーバーロード
同じクラス内(または親クラスと子クラス間)で、メソッド名が同一で、パラメータの型・数・順序が異なる場合、戻り値の型やアクセス修飾子は異なっても良い。
「Java 核心技術」などの解説によれば、同名のメソッドで引数が異なる場合にオーバーロードが発生します。
オーバーライド
オーバーライドは実行時に発生します。子クラスが父クラスの許容されるアクセス修飾子の方法を使い、同名・同引数リストのメソッドを再実装します。
- メソッド名と引数リストは同一、サブクラスのメソッドの戻り値の型は父クラスの戻り値より小さい、あるいは等しい。例外範囲は父クラスより小さいか等しい。アクセス修飾子は父クラスより大きいか等しい。
- 親クラスのメソッドのアクセス修飾子が
private、final、staticの場合、子クラスはそのメソッドをオーバーライドできません。ただし、staticのメソッドは再宣言可能です。 - コンストラクタはオーバーライドできません。
まとめ:オーバーライドは子クラスが親クラスのメソッドを再実装すること。外部の見た目は変えず、内部の挙動を変更できます。
| 区別点 | オーバーロードされたメソッド | オーバーライドされたメソッド |
|---|---|---|
| 発生範囲 | 同一クラス | 子クラス |
| パラメータリスト | 変更必須 | 変更してはいけない |
| 戻り値 | 変更可能 | 子クラスの戻り値は父クラスの戻り値より小さいか等しい |
| 例外 | 変更可能 | 子クラスの宣言された例外は父クラスより小さいか等しい |
| アクセス修飾子 | 変更可能 | より厳しくはならない(緩和は可) |
| 発生時期 | コンパイル時 | 実行時 |
メソッドのオーバーライドは「两同两小一大」原則に従う
- 「两同」=メソッド名が同じ、仮引数リストが同じ
- 「两小」=サブクラスの戻り値の型は、親クラスの戻り値より小さいか等しい。サブクラスの例外は、親クラスの宣言された例外より小さいか等しい
- 「一大」=サブクラスのアクセス権限は、親クラスのアクセス権より大きいか等しい
- 戻り値が void や基本データ型のときは、リターン時の戻り値を変更できません。ただし、戻り値が参照型の場合、リターン時にその参照型のサブクラスを返すことができます。
可変長パラメータ(varargs)とは?
Java 5 以降、Java は可変長パラメータを定義できるようになりました。可変長パラメータは、呼び出し時に長さ不定の引数を渡すことを許容するものです。例えば以下の printVariable メソッドは、0 個以上の引数を受け取ることができます。
public static void method1(String... args) {//......}また、可変長パラメータは関数の「最後の引数」のみとして扱われます。それより前には他の引数が任意です。
public static void method2(String arg1, String... args) {//......}メソッドのオーバーロードが複数ある場合、固定引数のメソッドと可変長引数のどちらを優先してマッチさせるべきか?
固定引数の方を優先してマッチします。固定引数の方がマッチ度が高いためです。
また、Java の可変長引数はコンパイル後には実際には配列として表現されます。
オブジェクト指向の基礎
オブジェクト指向と手続き型の違い
主な違いは、問題解決のアプローチです。
- 手続き型は、問題を解決するための処理を一連のメソッドに分解し、それらを順次実行することで問題を解決します。
- オブジェクト指向は、まず対象となる「オブジェクト」を抽象化し、それを操作する方法を用いて問題を解決します。
また、オブジェクト指向で開発されたプログラムは、保守性・再利用性・拡張性が高い傾向にあります。
オブジェクトを作成するにはどの演算子を使う?オブジェクト実体とオブジェクト参照の違いは?
new 演算子を使います。new はオブジェクトのインスタンスを作成します(オブジェクトのインスタンスはヒープメモリに配置されます)。オブジェクト参照は、インスタンスを指す参照で、スタックメモリに格納されます。
- 1つのオブジェクト参照は 0 個または 1 個のオブジェクトを指すことができます。
- 1 つのオブジェクトは n 個の参照を指すことができます。
オブジェクトの等価性と参照の等価性の違い
- オブジェクトの等価性(equals)と、参照の等価性(==)は、用途が異なります。
- 基本データ型は値を比較しますが、参照データ型は通常、
==は「参照の同一性」を、equals()は「内容の等価性」を比較します。
注意:
equals()は Object クラスに定義されています。基本データ型の変数には適用できません。
もしクラスがコンストラクタを宣言していなければ、このプログラムは正しく動作しますか?
コンストラクタはオブジェクトの初期化を行う特殊なメソッドです。クラスがコンストラクタを宣言していなくても、デフォルトの(引数なしの)コンストラクタが自動的に追加されます。ただし、クラスに自分でコンストラクタを追加した場合、デフォルトのコンストラクタは自動的には追加されません。
コンストラクタの特徴は?オーバーライドできるか?
コンストラクタの特徴は以下のとおりです。
- 名前はクラス名と同じ
- 戻り値はなく、void を宣言できません
- クラスのオブジェクトを生成する際に自動的に実行され、明示的に呼び出す必要はありません
コンストラクタはオーバーライド(上書き)できませんが、オーバーロードは可能です。したがって、クラスには複数のコンストラクタが存在することがあります。
オブジェクト指向の三大特性
-
カプセル化
オブジェクトの状態情報(すなわち属性)を内部に隠し、外部のオブジェクトが直接内部情報へアクセスできないようにします。必要に応じて外部から属性へアクセスするためのメソッドを提供します。外部からアクセスさせたくない場合は、外部へアクセスさせるメソッドを提供しなくてもよいです。
-
継承
既存のクラスの定義を基盤として新しいクラスを作成し、データや機能を追加したり、親クラスの機能を活用したりできます。継承を用いることで新しいクラスを素早く作成でき、コードの再利用性を高め、開発効率を向上させます。
- サブクラスは親クラスのオブジェクトのすべての属性とメソッドを持ちます(ただし、親クラスの private 属性やメソッドにはサブクラスは直接アクセスできません)。
- サブクラスは自分の属性とメソッドを持つことができ、親クラスを拡張できます。
- サブクラスは自分の方法で親クラスのメソッドを実装します(後述の説明を参照)。
-
多態性
多態性は、親クラスの参照を用いて子クラスのインスタンスを指すことができる、という性質です。
多態性の特徴:
- オブジェクトの型と参照型は、継承(クラス)/実装(インターフェース)の関係を持つ
- 参照型の変数が呼び出すメソッドは、実行時にどのクラスのものが実行されるか決定される
- 多態性では「子クラスにしか存在し、親クラスには存在しない」メソッドを呼び出すことはできません
- 子クラスが親クラスのメソッドをオーバーライドした場合、実際に実行されるのは子クラスのオーバーライドされたメソッドです。子クラスが親クラスのメソッドをオーバーライドしていなければ、親クラスのメソッドが実行されます。
インターフェースと抽象クラスの共通点と相違点
共通点:
- どちらもインスタンス化できません。
- どちらも抽象メソッドを含むことができます。
- どちらもデフォルト実装のメソッドを持つことができます(Java 8 以降は
defaultキーワードを使ってインターフェース内にデフォルトメソッドを定義可能)。
相違点:
- インターフェースは主にクラスの振る舞いを規定します。抽象クラスはコードの再利用を主眼とし、所属関係を強調します。
- クラスは一つのクラスしか継承できませんが、複数のインターフェースを実装できます。
- インターフェースのメンバーは基本的に public static final の型でなければならず、変更不可で初期値を必ず持つ必要があります。一方、抽象クラスのメンバーはデフォルト修飾子(package-private)となり、子クラスで再定義・再代入が可能です。
深いコピーと浅いコピーの違い、何が参照コピーなのか?
- 浅いコピー:新しいオブジェクトをヒープ上に作成しますが、元のオブジェクトが参照型の属性を持つ場合、その内部オブジェクトへの参照をコピーします。つまり、コピー後のオブジェクトと元のオブジェクトは内部オブジェクトを共有します。
- 深いコピー:オブジェクト全体を完全にコピーします。内部オブジェクトも含めてすべてを複製します。
Object
Object クラスの一般的なメソッドは何ですか?
Object クラスはすべてのクラスの親クラスです。主に以下の 11 個のメソッドを提供します。
/** * native 方法。現在の実行時オブジェクトの Class オブジェクトを返します。final 修飾子が付与されているため、サブクラスでのオーバーライドは不可。 */public final native Class<?> getClass()/** * native 方法。オブジェクトのハッシュコードを返します。主にハッシュテーブルで使用されます。 */public native int hashCode()/** * 2 つのオブジェクトのメモリ上のアドレスが等しいかを比較します。String クラスはこのメソッドをオーバーライドして、文字列の値が等しいかを比較します。 */public boolean equals(Object obj)/** * native 方法。現在のオブジェクトのコピーを作成して返します。 */protected native Object clone() throws CloneNotSupportedException/** * クラス名とインスタンスのハッシュコードを 16 進数で表した文字列を返します。すべてのサブクラスはこのメソッドをオーバーライドすることが推奨されています。 */public String toString()/** * native 方法であり、オーバーライドできません。このオブジェクトのモニター上で待機しているスレッドを通知します(モニターはロックの概念に相当します)。待機しているスレッドが複数いる場合、ランダムに1つのスレッドだけを通知します。 */public final native void notify()/** * native 方法であり、オーバーライドできません。notify と異なり、モニター上で待機している全スレッドを通知します。 */public final native void notifyAll()/** * native 方法であり、オーバーライドできません。スレッドの実行を停止します。注意:sleep はロックを解放しませんが、wait は解放します。timeout は待機時間です。 */public final native void wait(long timeout) throws InterruptedException/** * nanos パラメータを追加した待機時間。追加の時間(ナノ秒単位、範囲は 0-999999)が含まれます。したがって、超時の時間には nanos を加算する必要があります。 */public final void wait(long timeout, int nanos) throws InterruptedException/** * 先の 2 つの wait メソッドと同様、無限に待機するバージョン */public final void wait() throws InterruptedException/** * インスタンスがガベージコレクションで回収される際に呼ばれる操作 */protected void finalize() throws Throwable { }== と equals() の違い
== は基本データ型と参照データ型で役割が異なります。
- 基本データ型では、値を比較します。
- 参照データ型では、オブジェクトのメモリ上のアドレスを比較します。
Java は値渡しが基本のため、
==は基本データ型・参照データ型のどちらを比較しても、本質的には値を比較します。ただし、参照データ型の場合、比較される値はオブジェクトの参照です。
equals() は基本データ型には使用できず、オブジェクト同士の等価性を判断するために使用します。equals() は Object クラスに元々備わっており、すべてのクラスはこのメソッドを継承します。
Object クラスの equals() メソッド:
public boolean equals(Object obj) { return (this == obj);}equals() の使用には以下のような状況があります。
- クラスが equals() をオーバーライドしていない場合:equals() で比較すると、
==で比較した場合と同じ結果になります。デフォルトのObjectクラスの equals() が使用されます。 - クラスが equals() をオーバーライドしている場合:通常は属性の等価性を比較するようにオーバーライドします。属性がすべて等しければ true を返します。
String オブジェクトを作成する際、仮想機械は定数プールに既に同じ値のオブジェクトが存在するかを検索し、存在すればその参照を現在の参照として返します。存在しなければ定数プールに新たに String オブジェクトを作成します。
hashCode() の使い道は?
hashCode() はハッシュコード(int 整数)を取得します。ハッシュコードの役割は、ハッシュ表内のインデックス位置を特定することです。
hashCode() は JDK の Object クラスに定義されています。従って Java の任意のクラスには hashCode() が存在します。なお、Object の hashCode() はネイティブメソッドです。
注記:このメソッドは Oracle OpenJDK8 では「Marsaglia の xor-shift による乱数生成のためのスレッドローカル状態を使用して実装」されており、「アドレス」や「アドレス変換」ではありません。VM によって生成方法は異なります(第5の方法としてアドレスを返すものもあるようです)。詳細は公式ソース参照。
ハッシュテーブルはキーと値のペアを格納します。キーの素早い検索にはハッシュコードを活用します。
なぜ hashCode が必要なのか?
「HashSet が重複をどう検出するか」を例として説明します。
オブジェクトを HashSet に追加するとき、HashSet はまずオブジェクトの hashCode を計算して追加位置を決定します。また、同じ HashSet にすでに追加されている他のオブジェクトの hashCode と比較します。もし一致する hashCode が見つからなければ、重複はないと仮定します。
しかし、同じ hashCode を持つオブジェクトが見つかった場合には、equals() を呼び出して、hashCode が等しいオブジェクトが実際に同じかどうかを確認します。もし同じなら、追加は成功しません。違う場合は別の位置へ再ハッシュします。
これにより、equals の比較回数を大幅に減らし、実行速度を大きく向上させます。
実は、hashCode() と equals() はともに「二つのオブジェクトが等しいかどうか」を比較する機能を提供します。
なぜ JDK はこの二つのメソッドを同時に提供するのか?
HashMap、HashSet などのコレクタでは、hashCode の存在により要素が所属するコレクター内での探索効率が向上します。
同一の hashCode が複数のオブジェクトに対して一致する場合には、equals() が再度呼び出されて真偽が判断されます。hashCode は探索コストを大幅に低減します。
なぜ hashCode のみを提供しないのか?
同じ hashCode を持つ二つのオブジェクトが必ずしも等しいとは限らないからです。
同じ hashCode を持っていても必ず等しいとは限らない理由は?
ハッシュ関数の性質として、衝突が発生する可能性があります。ハッシュ関数の実装が悪いと衝突が増えますが、データの値域の分布にも依存します。
- もし two オブジェクトの hashCode が等しくても、equals() が true を返さない場合があります(ハッシュ衝突)。
- hashCode が等しく、かつ equals() が true を返す場合にのみ、二つのオブジェクトは等しいと判断します。
- hashCode が等しくても、equals() が false を返す場合は等しくありません。
equals() をオーバーライドする際には hashCode() もオーバーライドするべき理由?
等価なオブジェクトは同じ hashCode を返すべきだからです。すなわち、equals() で等しいと判断した場合、それらの hashCode も同じでなければなりません。
equals() をオーバーライドして also hashCode() をオーバーライドしないと、equal なオブジェクトでも hashCode が異なる場合が生じ、ハッシュベースのコレクションが期待通りに動作しなくなります。
- equals() が true を返す二つのオブジェクトは、hashCode() も同じ値を返すべき
- hashCode() が同じでも、必ずしも equals() が true を返すとは限らない(ハッシュ衝突)
- hashCode() が異なる場合は、等しくないことが確定します
String
String、StringBuffer、StringBuilder の違いは?
- 可変性
- String は不変(immutable)です。
- StringBuilder と StringBuffer は AbstractStringBuilder を介して実装されており、内部で文字列を変更可能です。
- スレッド安全性
- String は不変のためスレッドセーフです。
- StringBuffer は同期を取るためスレッドセーフ、StringBuilder は同期を取らず非同期的に動作するためスレッドセーフではありません。
- パフォーマンス
- String の変更は毎回新しい String オブジェクトを生成します。
- StringBuffer は内部で自分自身を変更しますが、常にスレッドセーフである分、やや遅くなる場合があります。
- StringBuilder は StringBuffer より高速ですが、スレッドセーフではありません。
結論として、少量のデータの操作には String を、単一スレッドでの大量データ操作には StringBuilder を、複数スレッドで大量データ操作には StringBuffer を使います。
String が不可変である理由?
String クラスは文字列を内部的に保持するために final 修飾子の配列を使い、クラス自体が最終的であり、継承されません。また、内部のデータが変更されないよう、修改のためのメソッドは公開されていません。これにより、セキュリティと整合性が保たれます。
- 文字列を保持する配列は
finalで private、かつ変更メソッドが公開されていません - String クラスは
finalなので継承可能な変更ができません - Java 9 以降、String、StringBuilder、StringBuffer は内部表現として byte 配列を使用するようになりました
新しい実装では、文字列には Latin-1 と UTF-16 の 2 つのエンコーディングが用意され、文字が Latin-1 の範囲内であれば Latin-1 が使用され、そうでなければ UTF-16 が使用されます。Latin-1Encoding では、1 バイトが 1 文字、UTF-16 では 2 バイトになる点に注意してください。漢字など Latin-1 では表現できない文字が含まれる場合は、UTF-16 が使われます。
文字列連結には「+」か StringBuilder か?
Java 言語自体は演算子のオーバーロードをサポートしていませんが、「+」と「+=” は String クラス専用としてオーバーロードされています。文字列オブジェクトの連結は実際には StringBuilder の append() を呼び出して実現され、連結後に toString() で新しい String オブジェクトを得ます。
ただし、ループ内で「+」を用いた文字列連結を行うと、巨大な問題が生じます。コンパイラは単一の StringBuilder を再利用せず、過剰な数の StringBuilder オブジェクトを生成してしまう可能性があります。
ただし、JDK9 以降ではこの問題は改善され、文字列連結は動的メソッド makeConcatWithConstants() を使って実現されるようになりました。+ 演算子による連結は、多用される場合には実行時の最適化に依存します。
String#equals() と Object#equals() の違いは?
String の equals() は文字列の値の等価性を比較するようにオーバーライドされています。Object の equals() はオブジェクトの参照(アドレス)を比較します。
文字列リテラルプールの役割は?
文字列リテラルプールは、文字列の性能とメモリ削減のための JVM 専用の領域です。既にプールに存在している同一のリテラル文字列の参照を再利用します。
// ヒープ上に "ab" のオブジェクトを作成// 文字列リテラルプールに "ab" の参照を保存String aa = "ab";// 文字列リテラルプール内の "ab" の参照を直接返すString bb = "ab";System.out.println(aa==bb);// trueString s1 = new String(“abc”); はいくつの文字列オブジェクトを生成しますか?
1 または 2 個の文字列オブジェクトが生成されます。
- 文字列リテラルプールに “abc” の参照が存在しない場合、ヒープ上に 2 個の String オブジェクトが生成されます。1 つはプールに格納され、もう1つはその参照が aa に格納されます。
- すでにプールに “abc” の参照がある場合、ヒープ上には 1 個の String オブジェクトだけが生成されます。
String#intern の作用は?
String.intern() は native(ネイティブ)メソッドで、指定された String オブジェクトの参照を文字列リテラルプールに保持する作用を持ちます。以下の 2 通りのケースに分かれます。
- 文字列リテラルプールに対応する文字列オブジェクトの参照が保存されていれば、その参照を直接返します。
- 文字列リテラルプールに対応する文字列オブジェクトの参照が保存されていなければ、定数プールに参照を作成して返します。
// ヒープ上に "Java" の String オブジェクトを作成// 文字列オブジェクト "Java" の参照を文字列リテラルプールに保存String s1 = "Java";// s1 の参照を intern() で取得String s2 = s1.intern();// ヒープ上に別の String オブジェクトを作成String s3 = new String("Java");// s3 を intern() で intern プールへString s4 = s3.intern();// s1 と s2 は同じオブジェクトを指すSystem.out.println(s1 == s2); // true// s3 と s4 はヒープ上で別のオブジェクトを指すSystem.out.println(s3 == s4); // false// s1 と s4 は同じオブジェクトを指すSystem.out.println(s1 == s4); // trueString 型の変数と定数を用いた「+」演算はどうなる?
コンパイル時に値が確定している文字列(定数文字列)は、JVM が文字列リテラルプールへ格納します。定数連結によって得られた文字列リテラルは、コンパイル時にすでに定数プールへ格納されます。Java コンパイラ(javac)は、定数フォールディング(Constant Folding)と呼ばれる最適化を行います。これにより、定数式の値を最適化して最終コードへ埋め込みます。
// 例: String str3 = "str" + "ing";この場合、コンパイラは最終的に String str3 = "string"; に最適化します。
すべての定数がフォールディングされるわけではなく、コンパイラがプログラムのコンパイル時に値を確定できる場合に限ります。
オブジェクト参照と「+」の文字列連結は、実際には StringBuilder の append() を呼び出して実現され、連結後に toString() が呼ばれて新しい String オブジェクトが生成されます。
final 修飾された String はコンパイル時に定数として扱われ、値を決定できる場合には定数として扱われます。実行時に厳密な値が分かる場合には、最適化の効果が薄れます。
異常(例外)
Java の例外クラスの階層図の概要
Exception と Error の違いは?
Java の例外の共通祖先は Throwable クラスです。Throwable には主に次の 2 つのサブクラスがあります。
- Exception:プログラム自身で処理可能な例外。捕捉して処理できる。Checked Exception(チェックされる例外)と Unchecked Exception(チェックされない例外)に分けられます。
- Error:プログラムが処理できないエラー。捕捉して処理することは推奨されません。例として Virtual MachineError、OutOfMemoryError、NoClassDefFoundError など。
Checked Exception と Unchecked Exception の違いは?
Checked Exception、Java コードのコンパイル時に、チェックされる例外が catch されない、あるいは throws で処理されていない場合はコンパイルを通過できません。
RuntimeException 及びその子クラスは非チェック例外です。非チェック例外は、例外処理を行わなくてもコンパイルを通過します。
- Checked Exception:IO 関連の例外、ClassNotFoundException、SQLException など
- Unchecked Exception:NullPointerException、IllegalArgumentException、NumberFormatException、ArrayIndexOutOfBoundsException、ClassCastException、ArithmeticException、SecurityException、UnsupportedOperationException など
Throwable クラスの主なメソッドは?
- String getMessage(): 発生時の簡易メッセージを返す
- String toString(): 発生時の詳細情報を返す
- String getLocalizedMessage(): ローカライズされた情報を返す。サブクラスがこのメソッドをオーバーライドすることでローカライズ可能。サブクラスがオーバーしていなければ getMessage() の結果と同じ
- void printStackTrace(): コンソールへ Throwable が包んだ例外情報を出力する
try-catch-finally の使い方は?
- try ブロック:例外を捕捉するために使用します。続く catch ブロックを 0 個以上接続できます。catch ブロックが無い場合は必ず finally ブロックを伴います。
- catch ブロック:try が捕捉した例外を処理します。
- finally ブロック:例外が発生したかどうかに関係なく、finally ブロックの中の文は必ず実行されます。try ブロックや catch ブロックで return 文が実行される場合、finally ブロックの実行が完了した後でメソッドが終了します。
注意:finally ブロック内で return を使わないでください。
try ブロックと finally ブロックの両方に return がある場合、try ブロックの return は無視されます。これは、try の戻り値を一時的なローカル変数に保存しておき、finally の return が実行されたとき、その変数の値が finally の return 値へと置き換えられるためです。
finally ブロックのコードは必ず実行されるのか?
必ずではありません。特定のケースでは finally ブロックのコードは実行されません。
- 例えば、実行中の JVM が終了する場合
- あるいは、次の 2 つの特殊なケースでは finally が実行されません:
- スレッドの死
- CPU の停止
try-with-resources を try-catch-finally の代わりに使う方法は?
- 適用範囲(リソースの定義):
java.lang.AutoCloseableまたはjava.io.Closeableを実装しているオブジェクト - リソースのクローズ順序と finally の実行順序:try-with-resources 文内のリソースは、宣言時に自動的にクローズされます。どの catch あるいは finally ブロックよりも先にリソースのクローズが行われます。
Java には、InputStream、OutputStream、Scanner、PrintWriter などのリソースがあり、それらは通常 close() メソッドを呼び出して閉じる必要があります。従来は try-catch-finally で対応します。
もちろん複数のリソースを同時に管理する場合、try-with-resources を使うと実装が非常に簡単になります。複数のリソースをセミコロンで区切って宣言することも可能です。
异常の使用上の注意点
- 異常(例外)を静的変数として定義しない。例外を手動で投げるたびに、新しい例外オブジェクトを生成して投げる必要があります。
- 例外情報には意味のあるメッセージを含めるべきです。
- より具体的な例外を投げることが望ましい。例えば、文字列の数値変換エラーなら NumberFormatException を投げるべきです(IllegalArgumentException のサブクラス)。
- ログを出力した後に例外を投げるべきではありません(両方を同じコードロジック内で併用しない)。
ジェネリクス
ジェネリックとは? その役割は?
Java のジェネリクスは JDK 5 で導入された新機能で、ジェネリック型パラメータを用いることで、コードの可読性と安全性を高めることができます。
コンパイラはジェネリックの型を検査でき、指定した型を通じて渡されるオブジェクトの型を限定できます。例えば ArrayList<Person> persons = new ArrayList<Person>() のように書けば、この ArrayList には Person オブジェクトしか格納できず、別の型を渡すとコンパイルエラーになります。
ArrayList<E> extends AbstractList<E>さらに、原生の List の戻り値は Object となり、キャストが必要ですが、ジェネリクスを用いるとコンパイラが自動的に型変換を行います。
ジェネリックの使用方法にはどんなものがある?
ジェネリックには一般的に以下の三つの使用形があります:ジェネリッククラス、ジェネリックインターフェース、ジェネリックメソッド。
- ジェネリッククラス
// T は任意の識別子としてよく使われる。一般には T、E、K、V などの形を取る// ジェネリッククラスをインスタンス化する際には T の具体的な型を指定する必要があるpublic class Generic<T>{
private T key;
public Generic(T key) { this.key = key; }
public T getKey(){ return key; }}- ジェネリックインターフェース
public interface Generator<T> { public T next();}- ジェネリックメソッド
public static < E > void printArray( E[] inputArray ) { for ( E element : inputArray ){ System.out.printf( "%s ", element ); } System.out.println();}注意: public static < E > void printArray( E[] inputArray ) は一般に静的ジェネリックメソッドと呼ばれます。Java ではジェネリックは単なるプレースホルダであり、実際に型を指定して初めて使用できます。
クラスをインスタンス化して実際に型を渡す必要があります。静的メソッドはクラスのインスタンス化より先にロードされるため、クラス上で宣言されているジェネリックを直接使用することはできません。独自に宣言した<E>のみを使います。
プロジェクトでジェネリックはどこで使われているのか?
- 共通返却結果を扱う
CommonResult<T>など、パラメータ T によって返却データ型を動的に指定 - Excel 処理クラス
ExcelUtil<T>のデータ型を動的に指定 - コレクションツールの構築(Collections の sort、binarySearch などの実装)
リフレクション
リフレクションとは?
フレームワークの基盤を研究した経験がある人なら、リフレクションはよく耳にする概念です。リフレクションは、実行時にクラスの情報を分析し、クラスの中のメソッドを実行する能力を与えます。リフレクションを用いると、任意のクラスの属性やメソッドを取得し、それらを呼び出すことができます。
リフレクションの長所と欠点
長所:コードを柔軟にし、さまざまなフレームワークに対して「即座に使用可能」な機能を提供します。
欠点:実行時の分析能力を高める一方、安全性の問題が増える可能性があります。例えば、ジェネリックの安全性を実行時に無視してしまう、といったケースがあります。また、リフレクションの性能はやや劣る場合がありますが、フレームワークにとっては大きな問題にはなりません。
リフレクションの適用シーン
多くの場面でビジネスロジックを記述している私たちのコードは、実際にはフレームワークの直接的な使用場面には接しません。しかし、フレームワークを使うことで、リフレクションの力を活用できます。Spring、Spring Boot、MyBatis などの多くのフレームワークでリフレクションは大量に使われています。
これらのフレームワークでは動的プロキシを多用しますが、動的プロキシの実現はリフレクションに依存しています。
以下は JDK を用いた動的プロキシのサンプルです。ここでは Method クラスを使って指定のメソッドを呼び出しています。
public class DebugInvocationHandler implements InvocationHandler { /** * 代理クラスの実在オブジェクト */ private final Object target;
public DebugInvocationHandler(Object target) { this.target = target; }
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException { System.out.println("before method " + method.getName()); Object result = method.invoke(target, args); System.out.println("after method " + method.getName()); return result; }}また、Java の強力な機能の一つであるアノテーションの実現もリフレクションに依存しています。
なぜ Spring を使うと @Component アノテーションだけでクラスを Spring Bean に宣言できるのか?@Value アノテーションで設定ファイルの値を取得できるのか?どう機能しているのか?なども、リフレクションを用いてクラス、属性、メソッド、パラメータのアノテーションを解析し、処理を施すことで実現しています。
注釈
注釈とは?
Annotation(注釈)は Java 5 以降に導入された新機能で、特殊なコメントのようなものとして扱われ、クラス・メソッド・変数などを修飾して、コンパイル時や実行時にプログラムへ情報を提供します。
注釈は本質的には Annotation を継承した特別なインターフェースです:
@Target(ElementType.METHOD)@Retention(RetentionPolicy.SOURCE)public @interface Override {
}
public interface Override extends Annotation{
}JDK には @Override や @Deprecated などの組み込み注釈が多数用意されています。同様に私達は独自の注釈を作成することもできます。
注釈の解析方法はいくつある?
注釈は解析されて初めて有効になります。主な解析方法は二つです。
- コンパイル時の直接スキャン:コンパイラは Java コードをコンパイルする際に対応する注釈をスキャンして処理します(例えば、
@Overrideが付与されたメソッドが親クラスのメソッドをオーバーライドしているかをコンパイル時に検査します)。 - 実行時のリフレクション処理:Spring の
@Value、@Componentなどの注釈は、リフレクションを用いて処理されます。
SPI
オブジェクト指向設計の原則の中で、モジュール間は通常、インターフェースを基盤としてプログラミングします。呼び出し側のモジュールは、被呼び出し側の内部の実装に気づかずに済むことが望ましいため、実装を差し替える場合にはコードの修正が必要になります。動的にアプリケーションの実行に応じて特定の実装を選択して装着する仕組みが必要です。Java の SPI はそのような仕組みを提供します。SPI は、あるインターフェースに対してサービス実装を探索する仕組みです。これは IoC 的な考え方に似ており、装着(インスタレーション)の制御をプログラムの外部へ移します。
SPI とは?
SPI は Service Provider Interface の略で、「サービス提供者のインターフェース」と読みます。API のように、サービス提供者や拡張フレームワークの開発者が使用するための専用のインターフェースです。
SPI はサービスのインターフェースと具体的なサービス実装を分離し、呼び出し側と実装提供者をデカップリングします。これにより、実装を変更・置換しても呼び出し側のコードを変更する必要がなくなります。
Spring、データベースのドライバ、ロギングインターフェース、Dubbo の拡張など、Java の多くのフレームワークで SPI が使われています。
SPI と API の違いは?
SPI と API はどちらも「インターフェース」に関連しますが、意味は混同されがちです。
モジュール間は通常、インターフェースを介して通信します。サービス呼び出し側とサービス実装側の間に「インターフェース」を挿入することで、実装と呼び出しを分離します。これを API と呼ぶことがあります。
- API は、呼び出し側が利用できる直接機能を提供する「外部の契約」としてのインターフェース。実装は呼び出し側に隠蔽され、実装の変更は呼び出し側に影響を与えません。
- SPI は、呼び出し側が利用する「インターフェース」自体を規定します。そして、様々な実装がこの規定されたルールに従って実装を提供します。呼び出し方は同じですが、実装は異なるものを提供できます。
SPI の実装—ServiceLoader
Java の SPI の実現は、クラス読み込み時に JAR の META-INF/services 配下のファイルを探索します。ファイルには対象のインターフェースの完全修飾名と、それを実装するクラスの完全修飾名を列挙します。実装クラスが検出されると、反射を用いてインスタンス化し、リストに格納します。
この仕組みを利用した例として、サービスの実装を一覧として取得できるサンプルが挙げられます。ServiceLoader の概念は、多くのフレームワークで使われており、Spring や Dubbo などの拡張にも共通するモチーフです。
シリアライゼーションとデシリアライゼーション
シリアライズとは? デシリアライズとは?
Java では、オブジェクトを永続化したり、ネットワーク経由で転送したりする際にシリアライズを使います。
- シリアライズ:データ構造やオブジェクトをバイナリのバイトストリームへ変換すること
- デシリアライズ:シリアライズされたバイトストリームをデータ構造やオブジェクトへ再構築すること
Java のようなオブジェクト指向言語において、シリアライズはオブジェクト(クラス)のインスタンスを対象として行われます。C++ のような半オブジェクト指向言語では、構造体(struct)はデータ構造を、class はオブジェクトを表します。
以下はシリアライズ/デシリアライズの代表的な用途です。
- ネットワーク経由の送信(RPC など)を行う前にオブジェクトをシリアライズして送信し、受信側でデシリアライズする
- ファイルにオブジェクトを保存する前にシリアライズし、ファイルから読み取る際にデシリアライズする
- データベース(Redis など)へ保存する前にシリアライズする。キャッシュから復元する際にはデシリアライズする
- メモリへ格納する前にシリアライズする。メモリから取り出す際にはデシリアライズする
シリアライズの主目的は、オブジェクトをネットワークで伝送可能にしたり、ファイル/データベース/メモリへ保存することです。
シリアライズプロトコルは TCP/IP のどの層に対応するのか?
ネットワーク通信の双方は、同じプロトコルを用いる必要があります。TCP/IP 四層モデルの各層のうち、シリアライズプロトコルはどの層に該当するのでしょうか?
上図のとおり、OSI 七層モデルのアプリケーション層・表示層・セッション層は、TCP/IP 四層モデルのアプリケーション層に対応するため、シリアライズプロトコルは TCP/IP アプリケーション層の一部と見なされます。
デシリアライズしたくないフィールドはどうする?
デシリアライズしたくない変数には transient キーワードを使います。
transient の作用は、インスタンス内の宣言された変数をシリアライズの対象から除外することです。デシリアライズ時には transient 修飾子が付いた変数の値は初期値へ戻ります。
transient についての注意点:
- transient は変数の修飾子であり、クラスやメソッドには付けられません。
- デシリアライズ後、transient 修飾子が付いた変数の値はデフォルト値になります。例えば int の場合はデシリアライズ後は 0。
- static 変数は Object に属さないため、transient 修飾子が付いていても付いていなくてもシリアライズされません。
よく使われるシリアライズプロトコルは?
JDK による標準のシリアライズは一般的には推奨されません。パフォーマンスが低く、セキュリティ上の問題があるためです。一般に使われるのは Hessian、Kryo、Protobuf、ProtoStuff などのバイナリ形式のシリアライズです。
JSON や XML のようなテキストベースのシリアライズは可読性は高いですが、性能はあまり良くなく、通常は選択肢として避けられます。
なぜ JDK による標準シリアライズは推奨されないのか?
以下の理由が挙げられます。
- 脚の跨る言語での相互運用性がなく、他の言語で実装されたサービスと連携する場合に制約になる
- シリアライズ後のバイト配列のサイズが大きく、転送コストが増大する
- セキュリティ上の課題がある。シリアライズとデシリアライズ自体には問題はないが、入力デシリアライズデータが利用者により制御可能である場合、悪意のある入力を用いて予期せぬオブジェクトを生成・実行される可能性がある
I/O
Java I/O の流れは理解していますか?
I/O(Input/Output)は、入力と出力を指します。データが計算機のメモリへ入ることを「入力」、外部ストレージ(データベース、ファイル、リモートホスト)へデータを出すことを「出力」と呼びます。データ転送は水の流れのようなものなので、IO 流と呼ばれます。Java には入力ストリームと出力ストリームがあり、データの処理方式によって、バイトストリームとキャラクタストリームに分かれます。
Java の IO 流は、40 以上のクラスが以下の 4 つの抽象クラス基底から派生しています。
- InputStream/Reader:すべての入力ストリームの基底クラス。前者はバイト入力ストリーム、後者は文字入力ストリーム。
- OutputStream/Writer:すべての出力ストリームの基底クラス。前者はバイト出力ストリーム、後者は文字出力ストリーム。
I/O 流をバイトストリームとキャラクタストリームに分ける理由は?
本質は、ファイルの読み書きやネットワークの送受信に関係なく、情報の最小単位はバイトです。それなのに、I/O 流操作をバイトストリームとキャラクタストリームに分けるのは何故でしょうか。
主な理由は次の二点です。
- キャラクタストリームは、バイトを文字に変換する過程を含み、これは時間がかかります。
- 文字コードが分からない場合、バイトストリームの処理で文字化けが発生しやすいです。
Java I/O におけるデザインパターン
デコレーター・パターン
デコレーター(Decorator)パターンは、元のオブジェクトの機能を変更せずに拡張します。継承の代わりに組み合わせを用いて、原始クラスの機能を拡張します。IO におけるデコレーターとしては FilterInputStream(入力ストリーム)と FilterOutputStream(出力ストリーム)が核心であり、サブクラスの機能を拡張するための共通親は InputStream と OutputStream です。
デコレーターは原始クラスをネストして複数のデコレーターを適用できる点が重要です。
アダプター・パターン
アダプター(Adapter)・パターンは、互換性のないインタフェースを協調させるための設計です。IO 流では、文字ストリームとバイトストリームの異なるインタフェースを、アダプターを通じて協働させることができます。InputStreamReader と OutputStreamWriter は、バイトストリームと文字ストリームの橋渡しをするアダプターです。InputStreamReader は bytes を文字へデコードするデコーダを利用し、OutputStreamWriter は文字をエンコードしてバイトストリームへ変換します。
ファクトリ・パターン
NIO など、多くの場面でファクトリ・パターンが使われます。例えば Files.newInputStream、Paths.get、ZipFileSystem.getPath など、静的ファクトリが多数使われます。
観察者・パターン
NIO のファイル監視サービスは観察者パターンを利用します。
WatchService は監視対象の変更を知らせる Observer、Watchable は被観察対象です。
- 監視イベントとしては、
ENTRY_CREATE、ENTRY_DELETE、ENTRY_MODIFYなどがあります。 registerメソッドは、WatchKey オブジェクトを返し、イベントの情報を取得可能です。
WatchService の内部は daemon thread(デーモン・スレッド)を使い、ポーリングによりファイルの変化を検知します。
BIO、NIO、AIO の違い
- BIO(従来のブロックI/O)
- NIO(新しく非ブロック I/O)
- AIO(非同期 I/O)
…(図表を参照)
シンタックス・シンタックス・シュガー(構文糖衣)
シンタックスシュガーとは?
構文糖衣(Syntactic sugar)とは、プログラミング言語がプログラマーの開発を容易にするために設計した、機能には影響を与えない特別な構文のことです。実際と同等の機能を果たすコードでも、構文糖衣を用いるとより単純で読みやすくなります。
例として、Java の for-each はよく使われる構文糖衣です。その原理は、通常の for ループとイテレータに基づいています。
String[] strs = {"JavaGuide", "公众号:JavaGuide", "博客:<https://javaguide.cn/>"};for (String s : strs) { System.out.println(s);}ただし、JVM 自体は構文糖衣を直接認識しません。Java の構文糖衣が正しく実行されるには、コンパイラが desugar(糖衣を解く)される必要があります。つまり、ソースコードを JVM が理解できる基本構文に変換します。com.sun.tools.javac.main.JavaCompiler のソースを見れば、compile() の中に desugar() という処理があり、これが糖衣の解決を実装しています。
Java における代表的な構文糖衣は?
Java のよく使われる構文糖衣には、ジェネリクス、オートボクシング/アンボクシング、可変長引数、列挙型、内部クラス、拡張 for ループ、try-with-resources、ラムダ式などがあります。
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります