


















Java IO基礎知識
IOストリームの概要
IO はすなわち Input/Output。データがコンピュータのメモリへ入力される過程を入力、逆に外部ストレージへ出力される過程を出力と呼ぶ。データ転送の過程は水の流れに似ているため IO ストリームと呼ばれる。Java の IO ストリームは入力ストリームと出力ストリームに分かれ、データの処理方法に応じてバイトストリームとキャラクタストリームに分かれる。
Java IO ストリームの40以上のクラスは、以下の4つの抽象クラスの基底クラスから派生している。
InputStream/Reader: すべての入力ストリームの基底クラス。前者はバイト入力ストリーム、後者は文字入力ストリーム。OutputStream/Writer: すべての出力ストリームの基底クラス。前者はバイト出力ストリーム、後者は文字出力ストリーム。
バイトストリーム
InputStream(バイト入力ストリーム)
InputStream は源泉(通常はファイル)からデータ(バイト情報)をメモリへ読み込むために用いられ、java.io.InputStream 抽象クラスはすべてのバイト入力ストリームの親クラス。
InputStream 常用メソッド:
read():入力ストリームの次のバイトのデータを返す。返される値は 0 から 255 の範囲。もし読み取れるバイトがない場合、コードは1を返し、ファイル終端を示す。read(byte b[]): 入力ストリームからいくつかのバイトを読み取り、配列bに格納する。配列bの長さがゼロの場合は読み取らない。利用可能なバイトが読み取れない場合は1を返す。読み取れるバイト数は最大でb.length。このメソッドはread(b, 0, b.length)と同等。read(byte b[], int off, int len):read(byte b[])メソッドを基にoff(オフセット)とlen(読み取る最大バイト数)を追加。skip(long n):入力ストリーム内の n バイトをスキップし、実際にスキップしたバイト数を返す。available():入力ストリーム内で読み取れるバイト数を返す。close():入力ストリームを閉じ、関連するシステムリソースを解放。
Java 9 以降、InputStream には新たな実用メソッドが追加された。
readAllBytes():入力ストリームの全バイトを読み取り、バイト配列を返す。readNBytes(byte[] b, int off, int len):ブロックしてlenバイトを読み取る。transferTo(OutputStream out):すべてのバイトを別の出力ストリームへ転送する。
FileInputStream は比較的よく使われるバイト入力ストリームで、ファイルパスを直接指定でき、単一バイトの読み取りも、バイト配列への読み込みも可能。
FileInputStream のコード例:
try (InputStream fis = new FileInputStream("input.txt")) { System.out.println("Number of remaining bytes:" + fis.available()); int content; long skip = fis.skip(2); System.out.println("The actual number of bytes skipped:" + skip); System.out.print("The content read from file:"); while ((content = fis.read()) != -1) { System.out.print((char) content); }} catch (IOException e) { e.printStackTrace();}ただし、一般的には直接 FileInputStream を単体で使うことはなく、通常は BufferedInputStream(バイトバッファ付き入力ストリーム)と組み合わせて使用する。
下記のようなコードは私たちのプロジェクトでよく見られます。readAllBytes() を通じて入力ストリームの全バイトを読み取り、直接 String オブジェクトへ代入する例。
// 新規 BufferedInputStream オブジェクトを作成BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));// ファイルの内容を読み取り、String オブジェクトへコピーString result = new String(bufferedInputStream.readAllBytes());System.out.println(result);DataInputStream は指定した型のデータを読み取るために使用され、単独では使用せず、他のストリームと組み合わせて使用する必要がある。
FileInputStream fileInputStream = new FileInputStream("input.txt");// fileInputStream をコンストラクタの引数として渡す必要ありDataInputStream dataInputStream = new DataInputStream(fileInputStream);// さまざまな型のデータを読み取るdataInputStream.readBoolean();dataInputStream.readInt();dataInputStream.readUTF();ObjectInputStream は入力ストリームから Java オブジェクトを読み取るため(デシリアライズ)、ObjectOutputStream はオブジェクトを出力ストリームへ書き込むため(シリアライズ)。
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data"));MyClass object = (MyClass) input.readObject();input.close();また、シリアライズ・デシリアライズのクラスは Serializable を実装する必要があり、オブジェクトの属性の中でシリアライズしたくないものには transient を付ける。
OutputStream(バイト出力ストリーム)
OutputStream はデータ(バイト情報)を宛先へ書き込むために用いられ、java.io.OutputStream 抽象クラスはすべてのバイト出力ストリームの基底クラス。
OutputStream 常用メソッド:
write(int b):指定した1バイトを出力ストリームへ書き込む。write(byte[] b[]): 配列bを出力ストリームへ書き込む。write(b, 0, b.length)に相当。write(byte[] b, int off, int len):write(byte b[])を基にoff(オフセット)とlen(読み取る最大バイト数)を追加。flush():この出力ストリームをフラッシュし、バッファリングされたすべてのバイトを書き出す。close():出力ストリームを閉じ、関連するシステムリソースを解放。
FileOutputStream は最もよく使われるバイト出力ストリームで、ファイルパスを直接指定でき、単一バイトの書き込みも、指定したバイト配列の書き込みも可能。
FileOutputStream のコード例:
try (FileOutputStream output = new FileOutputStream("output.txt")) { byte[] array = "Dreaifeyyy".getBytes(); output.write(array);} catch (IOException e) { e.printStackTrace();}FileInputStream と同様、FileOutputStream は通常も BufferedOutputStream(バイトバッファ付き出力ストリーム)と組み合わせて使用する。
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");BufferedOutputStream bos = new BufferedOutputStream(fileOutputStream)DataOutputStream は指定した型のデータを書き込むために用いられ、単独では使用せず、他のストリームと組み合わせて使用する必要がある。
// 出力ストリームFileOutputStream fileOutputStream = new FileOutputStream("out.txt");DataOutputStream dataOutputStream = new DataOutputStream(fileOutputStream);// 任意のデータ型を出力dataOutputStream.writeBoolean(true);dataOutputStream.writeByte(1);ObjectInputStream は入力ストリームから Java オブジェクトを読み取るため(ObjectInputStream、デシリアライズ)、ObjectOutputStream はオブジェクトを出力ストリームへ書き込むため(シリアライズ)。
ObjectOutputStream output = new ObjectOutputStream(new FileOutputStream("file.txt")Person person = new Person("dreaife", "eroger");output.writeObject(person);キャラクタストリーム
ファイルの読み書きやネットワークの送受信を問わず、情報の最小保存単位はバイトです。では、なぜ I/O ストリーム操作はバイトストリームとキャラクタストリームに分けられるのか。
個人的には2つの理由があると考えます:
- キャラクタストリームは Java 仮想マシンがバイトを文字へ変換する過程であり、これには時間がかかることがある。
- エンコーディングの種類がわからないと、文字化けが発生しやすい。
文字化けの問題は容易に再現できます。上記の FileInputStream のコード例の input.txt の内容を中国語に変更するだけで、元のコードを変更せずに読み取られた内容がすでに文字化けしていることが明らかになります。
したがって、I/O ストリームは直接文字を操作するインターフェースを提供するようになりました。音声ファイル、画像などのメディアファイルにはバイトストリームの方が適しており、文字を扱う場合はキャラクタストリームを使用するのが良いです。
キャラクタストリームはデフォルトで Unicode エンコードを採用しており、コンストラクタを通じてエンコードをカスタマイズできます。
ついでに、以前遭遇した筆記試験の問題:一般的な文字エンコードが占めるバイト数は? utf8:英字は 1 バイト、漢字は 3 バイト、Unicode:任意の文字はすべて 2 バイト、gbk:英字は 1 バイト、漢字は 2 バイト。
Reader(キャラクター入力ストリーム)
Reader は源泉(通常はファイル)からデータ(文字情報)をメモリへ読み込むために使用され、java.io.Reader 抽象クラスはすべての文字入力ストリームの親クラス。
Reader はテキストを読み取るために使われ、InputStream は原始バイトを読み取るために使われます。
Reader 常用メソッド:
read():入力ストリームから1文字を読み取る。read(char[] cbuf):入力ストリームからいくつかの文字を読み取り、文字配列cbufに格納する。等価なのはread(cbuf, 0, cbuf.length)。read(char[] cbuf, int off, int len):read(char[] cbuf)を基にoff(オフセット)とlen(読み取る最大文字数)を追加。skip(long n):入力ストリーム内の n 文字をスキップし、実際にスキップした文字数を返す。close():入力ストリームを閉じ、関連するシステムリソースを解放。
InputStreamReader はバイトストリームをキャラクタストリームへ変換する橋渡しで、そのサブクラスの FileReader はこの基盤の上でのファイル操作をカプセル化したもの。
// バイトストリームをキャラクタストリームへ変換する橋渡しpublic class InputStreamReader extends Reader {}// キャラクタファイルを読むためのクラスpublic class FileReader extends InputStreamReader {}FileReader のコード例:
try (FileReader fileReader = new FileReader("input.txt");) { int content; long skip = fileReader.skip(3); System.out.println("The actual number of bytes skipped:" + skip); System.out.print("The content read from file:"); while ((content = fileReader.read()) != -1) { System.out.print((char) content); }} catch (IOException e) { e.printStackTrace();}Writer(キャラクター出力ストリーム)
Writer はデータ(文字情報)を宛先へ書き込むために用いられ、java.io.Writer 抽象クラスはすべてのキャラクター出力ストリームの基底クラス。
Writer 常用メソッド:
write(int c):1文字を書き込む。write(char[] cbuf):文字配列cbufを書き込み、write(cbuf, 0, cbuf.length)に相当。write(char[] cbuf, int off, int len):write(char[] cbuf)を基にoffとlenを追加。write(String str):文字列を書き込み、write(str, 0, str.length())に相当。write(String str, int off, int len):write(String str)を基にoffとlenを追加。append(CharSequence csq):指定の文字列をWriterオブジェクトへ追加し、そのWriterを返す。append(char c):指定の文字を追加し、そのWriterを返す。flush():この出力ストリームをフラッシュし、すべてのバッファ出力文字を書き出す。close():出力ストリームを閉じ、関連するシステムリソースを解放。
OutputStreamWriter はキャラクタストリームをバイトストリームへ変換する橋渡しで、そのサブクラスの FileWriter はこの基盤の上でのファイルへのキャラクタ書き込みを提供する。
// キャラクタストリームをバイトストリームへ変換する橋渡しpublic class OutputStreamWriter extends Writer {}// キャラクタを書き込むためのファイル書き込みpublic class FileWriter extends OutputStreamWriter {}FileWriter のコード例:
try (Writer output = new FileWriter("output.txt")) { output.write("你好,我是dreaife");} catch (IOException e) { e.printStackTrace();}バイトバッファ付きストリーム
IO 操作は非常にコストが高いため、バッファ付きストリームはデータをバッファ領域へロードし、一度に複数バイトを読み書きすることで頻繁な IO 操作を回避し、ストリーム転送の効率を高めます。
バイトバッファ付きストリームはデコレータパターンを用いて、InputStream および OutputStream のサブクラスの機能を強化します。
なお、以下は BufferedInputStream(バイトバッファ付き入力ストリーム)を介して FileInputStream の機能を拡張する例。
// バイトストリームをバッファ付きストリームへ拡張BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));バッファのサイズはデフォルトで 8192 バイト。もちろん BufferedInputStream(InputStream in, int size) コンストラクタでバッファサイズを指定可能。
BufferedOutputStream(バイトバッファ付き出力ストリーム)
BufferedOutputStream はデータ(バイト情報)を宛先へ書き込む際、1バイトずつ書き込むのではなく、書き込むバイトをバッファ領域へ格納し、内部のバッファから順次書き出します。これにより IO 回数を大幅に減らし、読み書きの効率を高めます。
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("output.txt"))) { byte[] array = "dreaifeICU".getBytes(); bos.write(array);} catch (IOException e) { e.printStackTrace();}BufferedInputStream と同様、内部にもバッファがあり、そのサイズも 8192 バイトです。
キャラクタバッファストリーム
BufferedReader(キャラクターバッファ入力ストリーム)と BufferedWriter(キャラクターバッファ出力ストリーム)は、内部にバイト配列をバッファとして保持しますが、前者は主に文字情報を操作するために用いられます。
プリントストリーム
以下のコードはよく使われますね?
System.out.print("Hello!");System.out.println("Hello!");System.out は PrintStream オブジェクトを取得するためのもので、print メソッドは実際には PrintStream オブジェクトの write メソッドを呼び出します。
PrintStream はバイトプリントストリームに属し、それに対応するのが PrintWriter(キャラクタープリントストリーム)です。PrintStream は OutputStream のサブクラス、PrintWriter は Writer のサブクラス。
public class PrintStream extends FilterOutputStream implements Appendable, Closeable {}public class PrintWriter extends Writer {}ランダムアクセスストリーム
ここで解説するランダムアクセスストリームは、ファイルの任意の位置へ自由にジャンプして読み書きできる RandomAccessFile を指します。
RandomAccessFile のコンストラクタは次のとおりで、モードを指定できます。
// openAndDelete パラメータはデフォルト falseで、ファイルを開くが削除はされないpublic RandomAccessFile(File file, String mode) throws FileNotFoundException { this(file, mode, false);}// プライベートメソッドprivate RandomAccessFile(File file, String mode, boolean openAndDelete) throws FileNotFoundException{ // 省略}読み書きモードは主に次の4種類:
r:読み取り専用モード。rw: 読み書きモードrws:rwを基準として、ファイルの内容またはメタデータの変更を外部ストレージへ同期更新する。rwd:rwを基準として、ファイルの内容の変更を外部ストレージへ同期更新する。
ファイル内容はファイルに実際に保存されているデータを指し、メタデータはファイル属性(例:ファイルのサイズ、作成・変更時間など)を説明する。
RandomAccessFile には次の1つのファイルポインタがあり、次に書き込みまたは読み取りが行われるバイトの位置を表す。seek(long pos) メソッドでファイルポインタのオフセットを設定でき、ファイルの先頭から pos バイトの位置へ移動する。現在のファイルポインタの位置を知りたい場合は getFilePointer() を使う。
RandomAccessFile のコード例:
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");System.out.println("読み取り前のオフセット:" + randomAccessFile.getFilePointer() + ",現在読み取り済みの文字" + (char) randomAccessFile.read() + ",読み取り後のオフセット:" + randomAccessFile.getFilePointer());// ポインタの現在のオフセットは6randomAccessFile.seek(6);System.out.println("読み取り前のオフセット:" + randomAccessFile.getFilePointer() + ",現在読み取った文字" + (char) randomAccessFile.read() + ",読み取り後のオフセット:" + randomAccessFile.getFilePointer());// オフセット7の位置からバイトデータを書き込むrandomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});// ポインタは現在0、先頭へ戻るrandomAccessFile.seek(0);System.out.println("読み取り前のオフセット:" + randomAccessFile.getFilePointer() + ",現在読み取った文字" + (char) randomAccessFile.read() + ",読み取り後のオフセット:" + randomAccessFile.getFilePointer());RandomAccessFile の write メソッドは、書き込み位置にすでにデータがある場合、それを上書きします。
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});上記のプログラムを実行する前に input.txt の内容が ABCD だった場合、実行後は HIJK になります。
RandomAccessFile の代表的な用途の1つは、大容量ファイルの断点再開(Continue from where you left off)を実現することです。断点再開とは、ファイルのアップロードが途中で一時停止・失敗した場合でも、未アップロードの部分だけを再開してアップロードすることを指します。断片化してファイルを分割してアップロードすることが断点再開の基盤です。
RandomAccessFile の実装は FileDescriptor(ファイル記述子)と FileChannel(メモリマップドファイル)に依存します。
Java IO設計パターン
デコレーター・パターン
デコレーター(Decorator)パターン は、元のオブジェクトを変更することなく機能を拡張できます。
デコレーターは継承の代わりに組み合わせを使って元のクラスの機能を拡張します。継承関係が複雑な状況(IO のように多様なクラス継承関係がある場合)で特に有用です。
バイトストリームにとって、FilterInputStream(入力ストリームに対応)と FilterOutputStream(出力ストリームに対応)はデコレーターの核となり、それぞれ InputStream と OutputStream のサブクラスの機能を拡張します。
私たちがよく見る BufferedInputStream(バイトバッファ付き入力ストリーム)、DataInputStream などはすべて FilterInputStream のサブクラスであり、BufferedOutputStream(バイトバッファ付き出力ストリーム)、DataOutputStream などは FilterOutputStream のサブクラスです。
例として、BufferedInputStream(バイトバッファ付き入力ストリーム)を介して FileInputStream の機能を拡張することができます。
public BufferedInputStream(InputStream in) { this(in, DEFAULT_BUFFER_SIZE);}
public BufferedInputStream(InputStream in, int size) { super(in); if (size <= 0) { throw new IllegalArgumentException("Buffer size <= 0"); } buf = new byte[size];}このように、BufferedInputStream のコンストラクタの1つの引数は InputStream です。
BufferedInputStream のコード例:
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("input.txt"))) { int content; long skip = bis.skip(2); while ((content = bis.read()) != -1) { System.out.print((char) content); }} catch (IOException e) { e.printStackTrace();}この時、私たちは次のことを考えるかもしれません:なぜ直接 BufferedFileInputStream(文字バッファ付きファイル入力ストリーム)を作らないのか?
BufferedFileInputStream bfis = new BufferedFileInputStream("input.txt");InputStream のサブクラスが少なければこのようにしても問題ありません。しかし、InputStream のサブクラスは非常に多く、継承関係も複雑です。各サブクラスに対して対応するバッファ付き入力ストリームを用意するのは煩雑です。
IO ストリームに関するデコレーターの例は非常に多く、必ずしも覚える必要はありません。デコレーターの核を理解していれば、どこでデコレーターが使われているか自然と分かるようになります。
適応パターン
アダプター(Adapter Pattern) は、互換性のないクラス間の協調作業を実現するパターンです。日常生活でよく使われる電源アダプターを思い浮かべてください。
アダプターパターンには、適合される対象(Adaptee)とそれを対象へ適合させる Adapter があります。アダプターはオブジェクトアダプターとクラスアダプターに分かれます。クラスアダプターは継承関係を用い、オブジェクトアダプターは組み合わせ関係を用います。
IO ストリームのキャラクタストリームとバイトストリームのインターフェースは異なるため、互いに協調して動作させることはデコレーターではなくアダプターとして実現されます。より正確には「オブジェクトアダプター」です。アダプターを介して、バイトストリームのオブジェクトをキャラクタストリームのオブジェクトへ適合させることで、バイトストリームのオブジェクトを使って直接文字データを読み書きできます。
InputStreamReader と OutputStreamWriter は2つのアダプター(Adapter)であり、同時に、バイトストリームとキャラクタストリームの間の橋渡しでもあります。InputStreamReader は StreamDecoder(ストリームデコーダ)を使ってバイトをデコードし、バイトストリームからキャラクタストリームへの変換を実現します。 OutputStreamWriter は StreamEncoder(ストリームエンコーダ)を使って文字をエンコードし、キャラクタストリームからバイトストリームへの変換を実現します。
// InputStreamReader はアダプター、FileInputStream は被適合のクラスInputStreamReader isr = new InputStreamReader(new FileInputStream(fileName), "UTF-8");// BufferedReader が InputStreamReader の機能を拡張(デコレーター方式)BufferedReader bufferedReader = new BufferedReader(isr);java.io.InputStreamReader の一部ソースコード:
public class InputStreamReader extends Reader { //デコード用オブジェクト private final StreamDecoder sd; public InputStreamReader(InputStream in) { super(in); try { // StreamDecoder オブジェクトを取得 sd = StreamDecoder.forInputStreamReader(in, this, (String)null); } catch (UnsupportedEncodingException e) { throw new Error(e); } } // StreamDecoder オブジェクトを用いて具体的な読み取りを実装 public int read() throws IOException { return sd.read(); }}java.io.OutputStreamWriter の一部ソースコード:
public class OutputStreamWriter extends Writer { // エンコード用オブジェクト private final StreamEncoder se; public OutputStreamWriter(OutputStream out) { super(out); try { // StreamEncoder オブジェクトを取得 se = StreamEncoder.forOutputStreamWriter(out, this, (String)null); } catch (UnsupportedEncodingException e) { throw new Error(e); } } // 書き込み作業を行うために StreamEncoder オブジェクトを用いる public void write(int c) throws IOException { se.write(c); }}アダプター・パターンとデコレーター・パターンの違いは何ですか?
- デコレーター・パターンは、元のクラスの機能を動的に拡張することに重心を置き、デコレーターは元のクラスと同じ抽象クラスを継承するか同じインターフェースを実装する必要があります。また、デコレーター・パターンは元のクラスに複数のデコレーターをネストして適用することをサポートします。
- アダプター・パターンは、互換性のないインタフェースを持つクラスが一緒に動作できるようにすることを重視します。アダプター内部が適合元のクラスのメソッドを呼び出すことで、呼び出す側には透明です。例えば
StreamDecoder(ストリームデコーダ)とStreamEncoder(ストリームエンコーダ)は、それぞれInputStreamとOutputStreamを基に FileChannel オブジェクトを取得し、対応するread/writeメソッドを呼び出してバイトデータを読み書きします。
// InputStreamReader はアダプター、FileInputStream は適合元のクラスInputStreamReader isr = new InputStreamReader(new FileInputStream(fileName), "UTF-8");// BufferedReader は InputStreamReader の機能を拡張するデコレーターBufferedReader bufferedReader = new BufferedReader(isr);java.io.InputStreamReader の一部ソースコード:
public class InputStreamReader extends Reader { //デコード用のオブジェクト private final StreamDecoder sd; public InputStreamReader(InputStream in) { super(in); try { // StreamDecoder オブジェクトを取得 sd = StreamDecoder.forInputStreamReader(in, this, (String)null); } catch (UnsupportedEncodingException e) { throw new Error(e); } } // デコード用オブジェクトで具体的な読み取りを実行 public int read() throws IOException { return sd.read(); }}java.io.OutputStreamWriter の一部ソースコード:
public class OutputStreamWriter extends Writer { // エンコード用オブジェクト private final StreamEncoder se; public OutputStreamWriter(OutputStream out) { super(out); try { // StreamEncoder オブジェクトを取得 se = StreamEncoder.forOutputStreamWriter(out, this, (String)null); } catch (UnsupportedEncodingException e) { throw new Error(e); } } // 書き込み作業を行う public void write(int c) throws IOException { se.write(c); }}アダプターとデコレーターの違いは何ですか。
- デコレーターは元のクラスの機能を動的に拡張することに重心を置き、デコレーター自身が元クラスと同じ抽象クラスを継承または同じインターフェースを実装します。複数のデコレーターをネスト可能です。
- アダプターは互換性のないインターフェース同士をつなぐことを目的としています。アダプターの内部は適合元のクラスの機能を呼び出しますが、それは呼び出し元には透過的です。
さらに、FutureTask クラスはアダプター・パターンを使用しており、Executors の内部クラス RunnableAdapter の実装はアダプターとして、Runnable を Callable に適合させるために用いられます。
public FutureTask(Runnable runnable, V result) { // Executors クラスの callable メソッドを呼ぶ this.callable = Executors.callable(runnable, result); this.state = NEW;}Executors における対応するメソッドとアダプター:
// 実際には Executors の内部クラス RunnableAdapter のコンストラクタが呼ばれるpublic static <T> Callable<T> callable(Runnable task, T result) { if (task == null) throw new NullPointerException(); return new RunnableAdapter<T>(task, result);}// アダプターstatic final class RunnableAdapter<T> implements Callable<T> { final Runnable task; final T result; RunnableAdapter(Runnable task, T result) { this.task = task; this.result = result; } public T call() { task.run(); return result; }}ファクトリーパターン
ファクトリーパターンはオブジェクトを作成するためのパターンで、NIO においても多く利用されます。例えば、Files クラスの newInputStream メソッドは InputStream オブジェクトを作成します(静的ファクトリ)、Paths クラスの get メソッドは Path オブジェクトを作成します(静的ファクトリ)、ZipFileSystem クラス(sun.nio パッケージのクラス、java.nio 関連の内部実装の1つ) の getPath メソッドは Path オブジェクトを作成します(シンプルファクトリ)。
InputStream is = Files.newInputStream(Paths.get(generatorLogoPath))観察者パターン
NIO のディレクトリ監視サービスは観察者パターンを使用します。
NIO のディレクトリ監視サービスは WatchService インターフェースと Watchable インターフェースに基づきます。WatchService は観察者、Watchable は被観察者です。
Watchable インターフェースは、オブジェクトを WatchService(監視サービス)へ登録し、監視イベントを結び付けるためのメソッド register を定義します。
public interface Path extends Comparable<Path>, Iterable<Path>, Watchable{}
public interface Watchable { WatchKey register(WatchService watcher, WatchEvent.Kind<?>[] events, WatchEvent.Modifier... modifiers) throws IOException;}WatchService はファイルディレクトリの変化を監視するためのサービスです。同じ WatchService オブジェクトで複数のファイルディレクトリを監視できます。
// WatchService オブジェクトを作成WatchService watchService = FileSystems.getDefault().newWatchService();
// 監視対象のディレクトリの Path を初期化Path path = Paths.get("workingDirectory");// この path を WatchService の監視対象として登録WatchKey watchKey = path.register(watchService, StandardWatchEventKinds...);Path クラスの register メソッドの第2引数 events(監視するイベント)は可変長引数であり、複数のイベントを同時に監視可能です。
WatchKey register(WatchService watcher, WatchEvent.Kind<?>... events) throws IOException;よく使われるイベントは3種類:
StandardWatchEventKinds.ENTRY_CREATE:ファイル作成。StandardWatchEventKinds.ENTRY_DELETE:ファイル削除。StandardWatchEventKinds.ENTRY_MODIFY:ファイル変更。
register メソッドは WatchKey を返し、WatchKey を通じてファイルディレクトリ内で作成・削除・変更が行われたか、作成・削除・変更されたファイルの具体的名称が何かといった情報を取得できる。
WatchKey key;while ((key = watchService.take()) != null) { for (WatchEvent<?> event : key.pollEvents()) { // WatchEvent オブジェクトのメソッドを呼んで、イベントの具体的情報を出力するなど } key.reset();}WatchService の内部は、デーモン・スレッドを使い、定期的にポーリングする方式でファイルの変更を検出します。簡略化したソースの例は以下のとおり。
class PollingWatchService extends AbstractWatchService{ // daemon thread を用意してファイルの変更をポーリング private final ScheduledExecutorService scheduledExecutor;
PollingWatchService() { scheduledExecutor = Executors .newSingleThreadScheduledExecutor(new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread t = new Thread(r); t.setDaemon(true); return t; }}); }
void enable(Set<? extends WatchEvent.Kind<?>> events, long period) { synchronized (this) { // 監視イベントを更新 this.events = events;
// 定期的なポーリングを開始 Runnable thunk = new Runnable() { public void run() { poll(); }}; this.poller = scheduledExecutor .scheduleAtFixedRate(thunk, period, period, TimeUnit.SECONDS); } }}Java IOモデル
I/O
I/O とは?
I/O(Input/Outpu)すなわち「入力/出力」。
私たちはまず、コンピュータ構造の観点から I/O を見てみましょう。
フォン・ノイマン構成に基づくと、コンピュータ構造は5つの部分に分かれます。演算装置、制御装置、記憶装置、入力装置、出力装置。
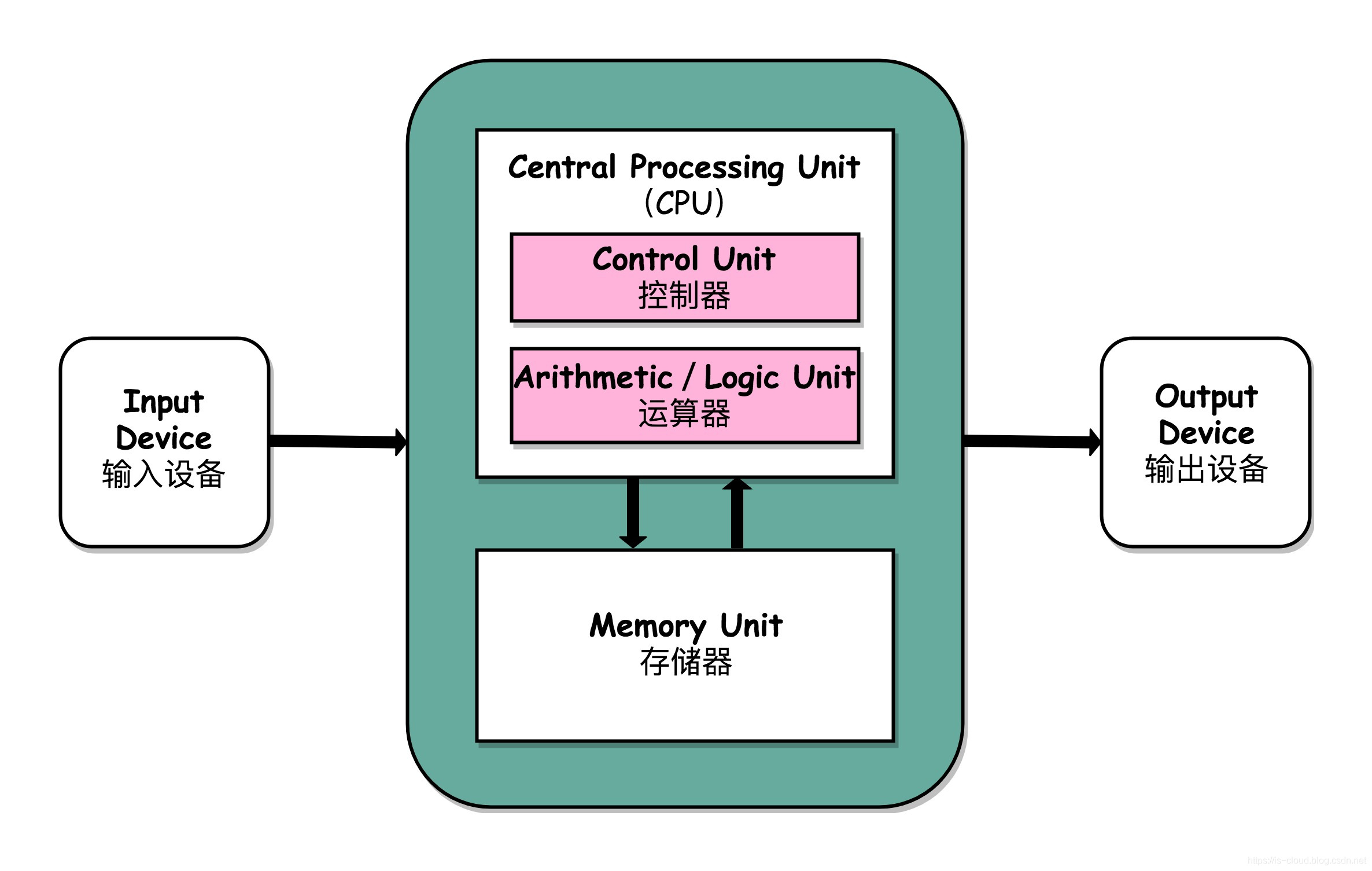
入力装置(例えばキーボード)と出力装置(例えばディスプレイ)は外部デバイスに属します。ネットワークカードやハードディスクは入力装置にも出力装置にもなることがあります。
入力装置はデータをコンピュータへ入力し、出力装置はコンピュータからのデータを受け取ります。
コンピュータ構造の観点から見ると、I/O はコンピュータシステムと外部デバイス間の通信プロセスを指します。
次に、アプリケーションの観点から I/O を解釈します。
OS の知識に基づくと:OS の安定性と安全性を確保するため、1つのプロセスのアドレス空間は**ユーザ空間(User space)とカーネル空間(Kernel space)**に分割されます。
私たちが日常に使うアプリケーションはユーザ空間で実行され、システム状態レベルのリソース操作はカーネル空間でのみ可能です。つまり、IO 操作を実行するには必ずカーネル空間の能力に依存します。
さらに、ユーザ空間のプログラムは直接カーネル空間へアクセスできません。
IO 操作を実行したいとき、権限の問題があるため、システムコールを発行して OS に手伝ってもらいます。
したがって、ユーザプロセスが IO 操作を実行する場合、システムコールを介して間接的にカーネル空間へアクセスします。
私たちは日常の開発で最も接するのは「ディスク IO(ファイルの読み書き)」と「ネットワーク IO(ネットワークの要求と応答)」です。
アプリケーションの観点から見ると、アプリケーションは OS のカーネルへ IO 呼び出し(システムコール)を発行し、カーネルが具体的な IO 操作を実行します。つまり、アプリケーションは IO 操作の呼び出しを発行するだけで、IO の実行は OS のカーネルが行います。
アプリケーションが IO 呼び出しを発行した後、2つのステップを経ます:
- カーネルが IO デバイスのデータ準備を待つ
- カーネルがデータをカーネル空間からユーザ空間へコピーする。
よくある IO モデルは?
UNIX 系のシステムには I/O モデルが5種類あります:同期ブロッキング I/O、同期ノンブロッキング I/O、I/O 多重路復用、シグナル駆動 I/O、非同期 I/O。
これらは私たちがよく耳にする5つの IO モデルです。
Java における3つの一般的な IO モデル
BIO (Blocking I/O)
BIO は同期ブロッキング IO モデルに属します。
同期ブロッキング IO モデルでは、アプリケーションが read を呼ぶと、データがユーザ空間へコピーされるまで待機します。
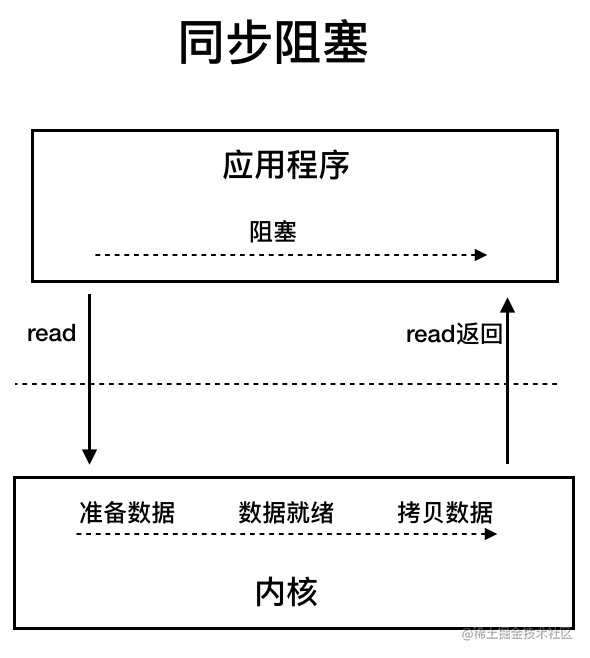
クライアント接続数が多くなければ問題ありません。しかし、十万~百万規模の接続を扱う場合、従来の BIO モデルは力不足です。したがって、より高効率な I/O 処理モデルが必要です。
NIO (Non-blocking/New I/O)
Java の NIO は Java 1.4 で導入され、java.nio パッケージに対応し、Channel、Selector、Buffer などの抽象を提供します。NIO は「I/O 多路復用モデル」と捉えることができます。多くの人は Java の NIO を「同期ノンブロッキング IO モデル」と見なすこともあります。
まずは「同期ノンブロッキング IO モデル」を見てみましょう。
(図の説明:同期ノンブロッキング IO モデルでは、アプリケーションは継続的に `read` を呼び出すが、データがカーネル空間からユーザ空間へコピーされる間、スレッドはブロックされる。)同期ノンブロッキング IO モデルでは、スレッドはデータが準備できているかをポーリングします。これには CPU リソースが多く消費されます。
しかし、この時点で IO 多路復用モデルが登場します。
IO 多路復用モデルでは、スレッドは最初に `select` 呼び出しを実行して、データ準備ができているかをカーネルへ問い合わせ、カーネルが準備完了となると、ユーザースレッドは `read` を呼び出します。`read` の過程は相変わらずブロックします。現在、IO 多路復用をサポートするシステムコールには select や epoll などがあります。select はほぼすべての OS でサポートされ、epoll は Linux 2.6 以降のカーネルで、IO の実行効率を向上させる拡張版です。
IO 多路復用モデルは、無効なシステムコールを減らすことで CPU リソースの消費を抑えます。
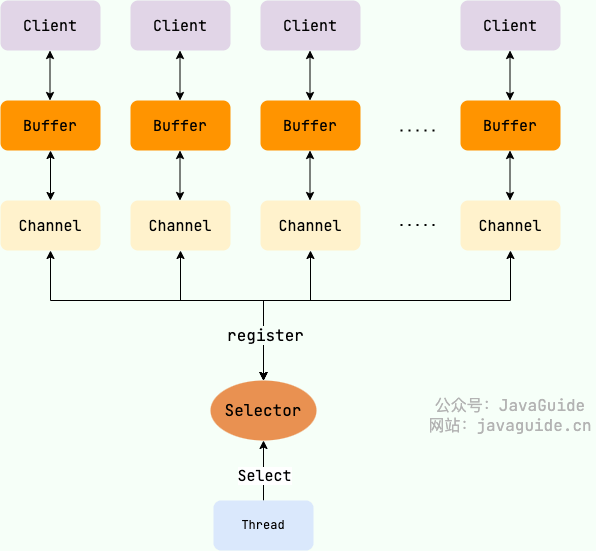
Java の NIO には「選択子(Selector)」という非常に重要な概念があり、これをマルチプレクサとも呼べます。これを用いれば、1 つのスレッドで複数のクライアント接続を管理できます。クライアントデータが到着したときだけ処理を行います。
AIO (Asynchronous I/O)
AIO とは NIO.2。Java 7 で NIO の改良版として導入された非同期 IO モデルです。
非同期 IO はイベントとコールバック機構に基づいており、アプリケーションの操作を実行した直後に戻り、バックグラウンド処理が完了すると OS が対応するスレッドに後続処理を通知します。
現在のところ AIO の適用はまだ広くありません。Netty も以前は AIO を試みましたが、Linux 系での性能向上があまり見られず、断念しました。
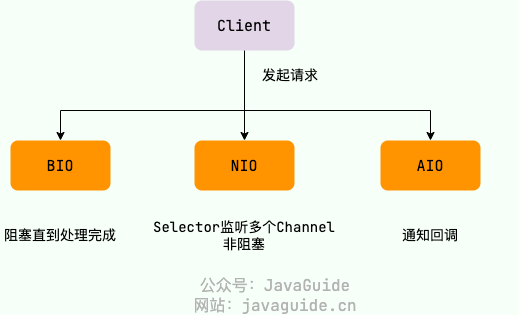
最後に、Java の BIO、NIO、AIO を簡単にまとめた図をどうぞ。
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります