






















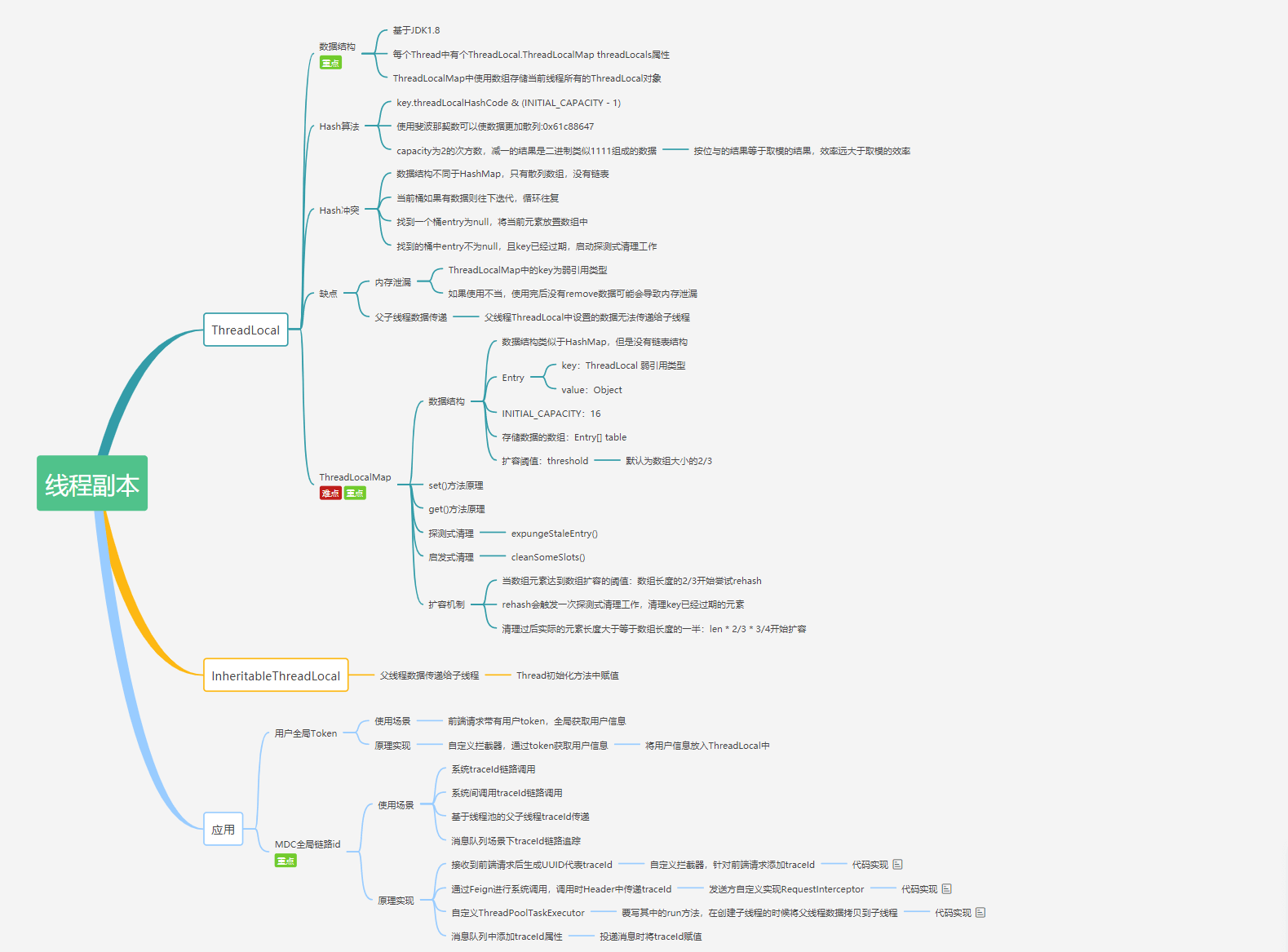
对于ThreadLocal,大家的第一反应可能是很简单呀,线程的变量副本,每个线程隔离。那这里有几个问题大家可以思考一下:
ThreadLocal的 key 是弱引用,那么在ThreadLocal.get()的时候,发生GC之后,key 是否为null?ThreadLocal中ThreadLocalMap的数据结构?ThreadLocalMap的Hash 算法?ThreadLocalMap中Hash 冲突如何解决?ThreadLocalMap的扩容机制?ThreadLocalMap中过期 key 的清理机制?探测式清理和启发式清理流程?ThreadLocalMap.set()方法实现原理?ThreadLocalMap.get()方法实现原理?- 项目中
ThreadLocal使用情况?遇到的坑? - ……
注明: 本文源码基于JDK 1.8
ThreadLocal代码演示
我们先看下ThreadLocal使用示例:
public class ThreadLocalTest { private List<String> messages = Lists.newArrayList();
public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) { holder.get().messages.add(message); }
public static List<String> clear() { List<String> messages = holder.get().messages; holder.remove();
System.out.println("size: " + holder.get().messages.size()); return messages; }
public static void main(String[] args) { ThreadLocalTest.add("testsetestse"); System.out.println(holder.get().messages); ThreadLocalTest.clear(); }}打印结果:
[testsetestse]size: 0ThreadLocal对象可以提供线程局部变量,每个线程Thread拥有一份自己的副本变量,多个线程互不干扰。
ThreadLocal的数据结构
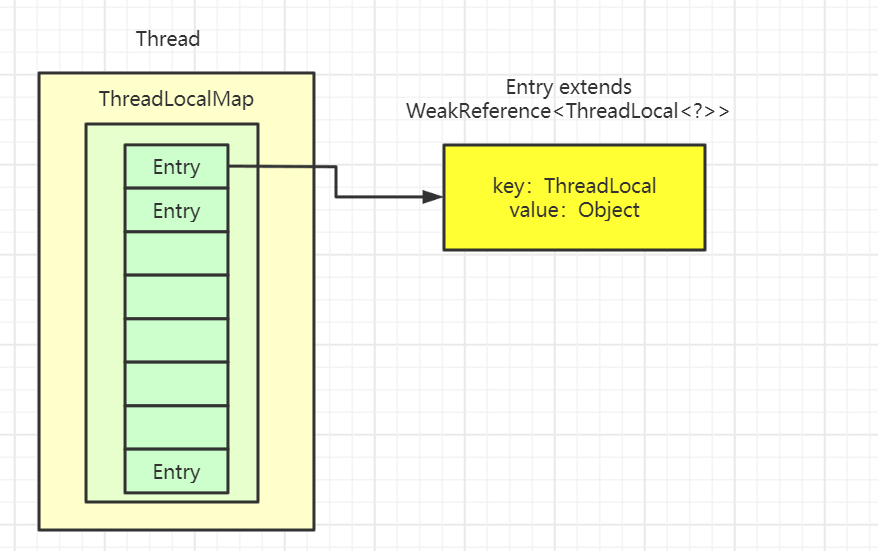
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,也就是说每个线程有一个自己的ThreadLocalMap。
ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。
每个线程在往ThreadLocal里放值的时候,都会往自己的ThreadLocalMap里存,读也是以ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
我们还要注意Entry, 它的key是ThreadLocal<?> k ,继承自WeakReference, 也就是我们常说的弱引用类型。
GC 之后 key 是否为 null?
回应开头的那个问题, ThreadLocal 的key是弱引用,那么在ThreadLocal.get()的时候,发生GC之后,key是否是null?
为了搞清楚这个问题,我们需要搞清楚Java的四种引用类型:
- 强引用:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
- 软引用:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
- 弱引用:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
- 虚引用:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
接着再来看下代码,我们使用反射的方式来看看GC后ThreadLocal中的数据情况:
public class ThreadLocalDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException { Thread t = new Thread(()->test("abc",false)); t.start(); t.join(); System.out.println("--gc后--"); Thread t2 = new Thread(() -> test("def", true)); t2.start(); t2.join(); }
private static void test(String s,boolean isGC) { try { new ThreadLocal<>().set(s); if (isGC) { System.gc(); } Thread t = Thread.currentThread(); Class<? extends Thread> clz = t.getClass(); Field field = clz.getDeclaredField("threadLocals"); field.setAccessible(true); Object ThreadLocalMap = field.get(t); Class<?> tlmClass = ThreadLocalMap.getClass(); Field tableField = tlmClass.getDeclaredField("table"); tableField.setAccessible(true); Object[] arr = (Object[]) tableField.get(ThreadLocalMap); for (Object o : arr) { if (o != null) { Class<?> entryClass = o.getClass(); Field valueField = entryClass.getDeclaredField("value"); Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent"); valueField.setAccessible(true); referenceField.setAccessible(true); System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o))); } } } catch (Exception e) { e.printStackTrace(); } }}结果如下:
弱引用key:java.lang.ThreadLocal@433619b6,值:abc弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12--gc后--弱引用key:null,值:def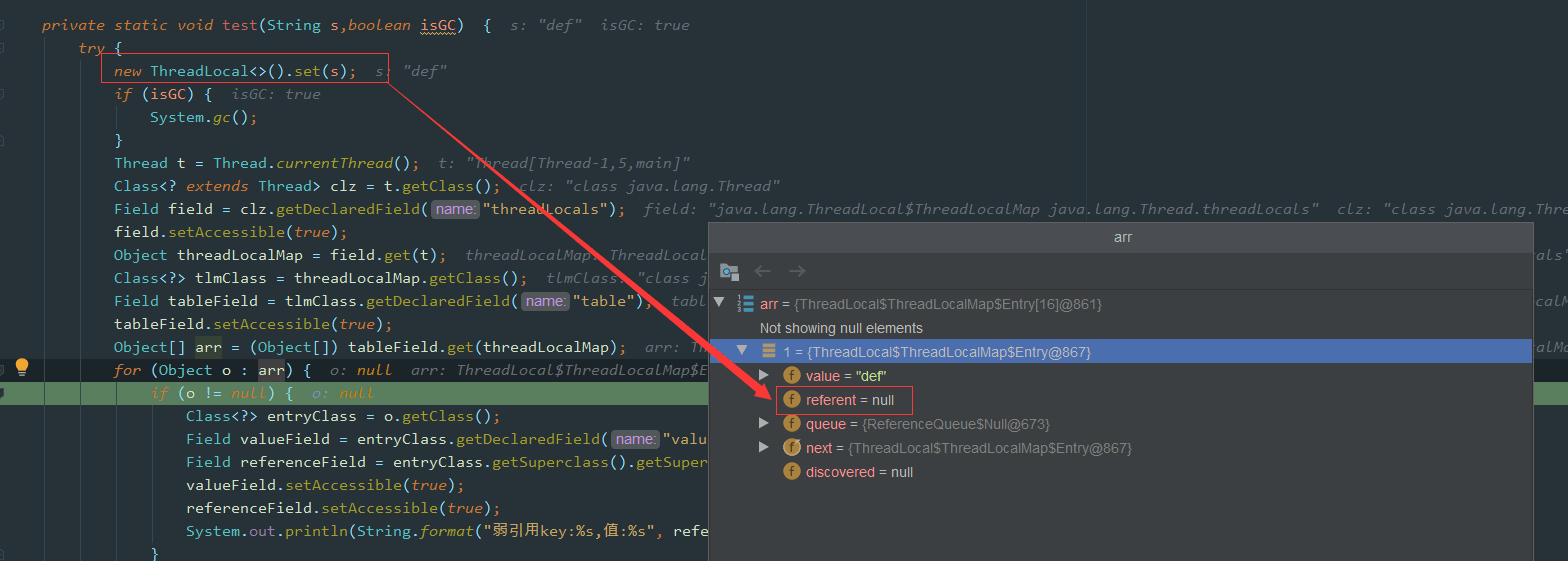
如图所示,因为这里创建的ThreadLocal并没有指向任何值,也就是没有任何引用。所以这里在GC之后,key就会被回收,我们看到上面debug中的referent=null。
这个问题刚开始看,如果没有过多思考,弱引用,还有垃圾回收,那么肯定会觉得是null。
其实是不对的,因为题目说的是在做 ThreadLocal.get() 操作,证明其实还是有强引用存在的,所以 key 并不为 null,ThreadLocal的强引用仍然是存在的。
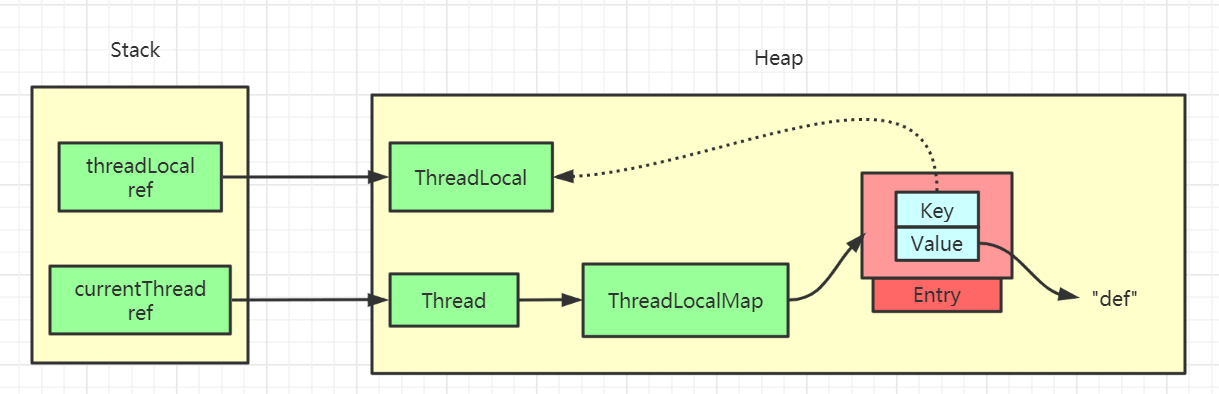
如果我们的强引用不存在的话,那么 key 就会被回收,也就是会出现我们 value 没被回收,key 被回收,导致 value 永远存在,出现内存泄漏。
ThreadLocal.set()方法源码详解
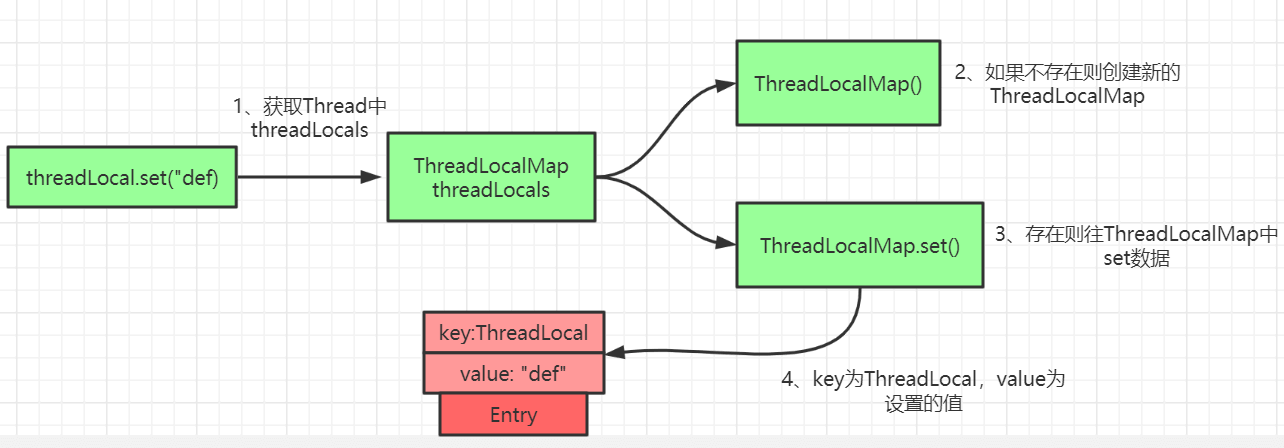
ThreadLocal中的set方法原理如上图所示,很简单,主要是判断ThreadLocalMap是否存在,然后使用ThreadLocal中的set方法进行数据处理。
代码如下:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value);}
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue);}主要的核心逻辑还是在ThreadLocalMap中的。
ThreadLocalMap Hash 算法
既然是Map结构,那么ThreadLocalMap当然也要实现自己的hash算法来解决散列表数组冲突问题。
int i = key.threadLocalHashCode & (len-1);ThreadLocalMap中hash算法很简单,这里i就是当前 key 在散列表中对应的数组下标位置。
这里最关键的就是threadLocalHashCode值的计算,ThreadLocal中有一个属性为HASH_INCREMENT = 0x61c88647
public class ThreadLocal<T> { private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
static class ThreadLocalMap { ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } }}每当创建一个ThreadLocal对象,这个ThreadLocal.nextHashCode 这个值就会增长 0x61c88647 。
这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
ThreadLocalMap Hash 冲突
注明: 下面所有示例图中,绿色块Entry代表正常数据,灰色块代表Entry的key值为null,已被垃圾回收。白色块表示Entry为null。
虽然ThreadLocalMap中使用了黄金分割数来作为hash计算因子,大大减少了Hash冲突的概率,但是仍然会存在冲突。
HashMap中解决冲突的方法是在数组上构造一个链表结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成红黑树。
而 ThreadLocalMap 中并没有链表结构,所以这里不能使用 HashMap 解决冲突的方式了。
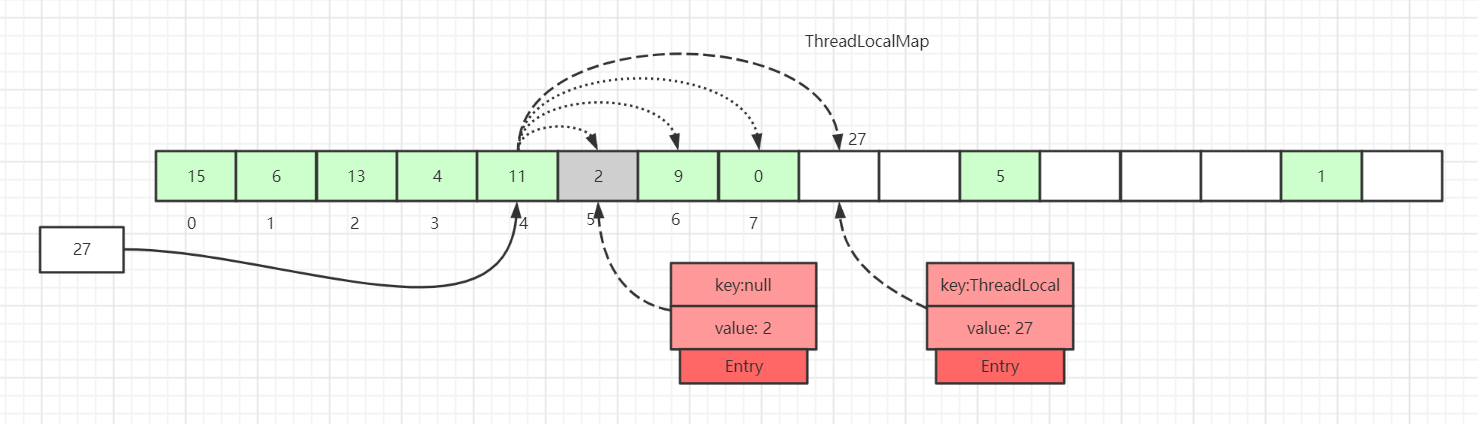
如上图所示,如果我们插入一个value=27的数据,通过 hash 计算后应该落入槽位 4 中,而槽位 4 已经有了 Entry 数据。
此时就会线性向后查找,一直找到 Entry 为 null 的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了 Entry 不为 null 且 key 值相等的情况,还有 Entry 中的 key 值为 null 的情况等等都会有不同的处理,后面会一一详细讲解。
这里还画了一个Entry中的key为null的数据(Entry=2 的灰色块数据),因为key值是弱引用类型,所以会有这种数据存在。在set过程中,如果遇到了key过期的Entry数据,实际上是会进行一轮探测式清理操作的。
ThreadLocalMap.set()详解
ThreadLocalMap.set()原理图解
看完了ThreadLocal hash 算法后,我们再来看set是如何实现的。
往ThreadLocalMap中set数据(新增或者更新数据)分为好几种情况,针对不同的情况我们画图来说明。
-
通过
hash计算后的槽位对应的Entry数据为空: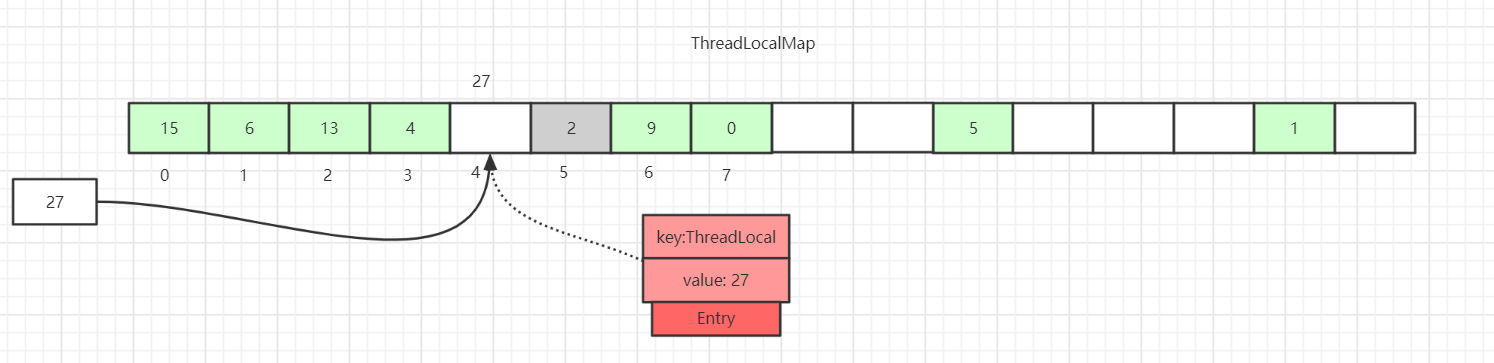
这里直接将数据放到该槽位即可。
-
槽位数据不为空,
key值与当前ThreadLocal通过hash计算获取的key值一致: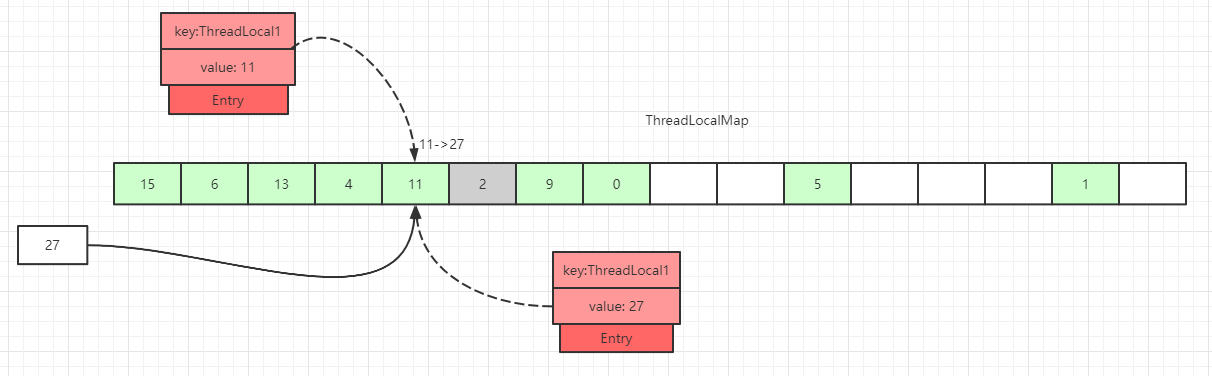
这里直接更新该槽位的数据。
-
槽位数据不为空,往后遍历过程中,在找到
Entry为null的槽位之前,没有遇到key过期的Entry: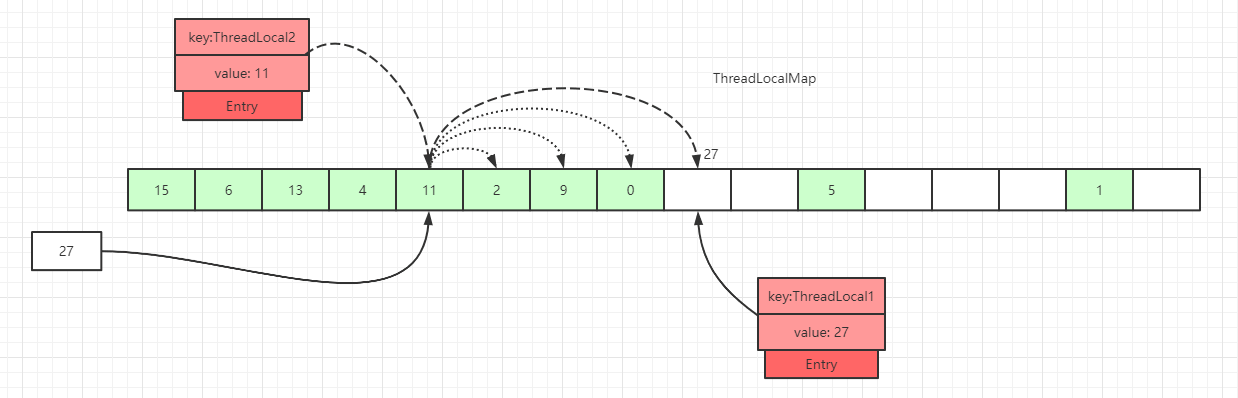
遍历散列数组,线性往后查找,如果找到
Entry为null的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了key 值相等的数据,直接更新即可。 -
槽位数据不为空,往后遍历过程中,在找到
Entry为null的槽位之前,遇到key过期的Entry,如下图,往后遍历过程中,遇到了index=7的槽位数据Entry的key=null: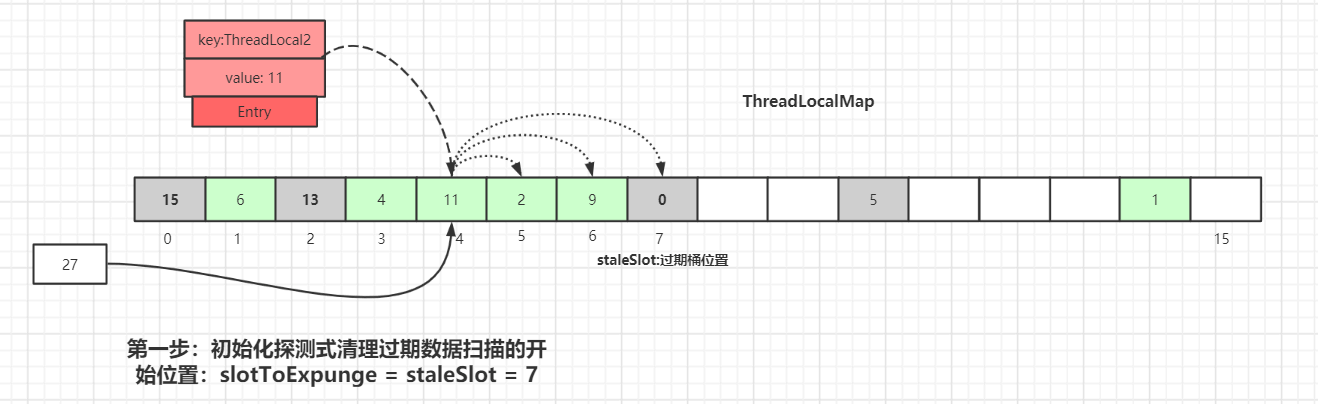
散列数组下标为 7 位置对应的
Entry数据key为null,表明此数据key值已经被垃圾回收掉了,此时就会执行replaceStaleEntry()方法,该方法含义是替换过期数据的逻辑,以index=7位起点开始遍历,进行探测式数据清理工作。初始化探测式清理过期数据扫描的开始位置:
slotToExpunge = staleSlot = 7以当前
staleSlot开始 向前迭代查找,找其他过期的数据,然后更新过期数据起始扫描下标slotToExpunge。for循环迭代,直到碰到Entry为null结束。如果找到了过期的数据,继续向前迭代,直到遇到
Entry=null的槽位才停止迭代,如下图所示,slotToExpunge 被更新为 0: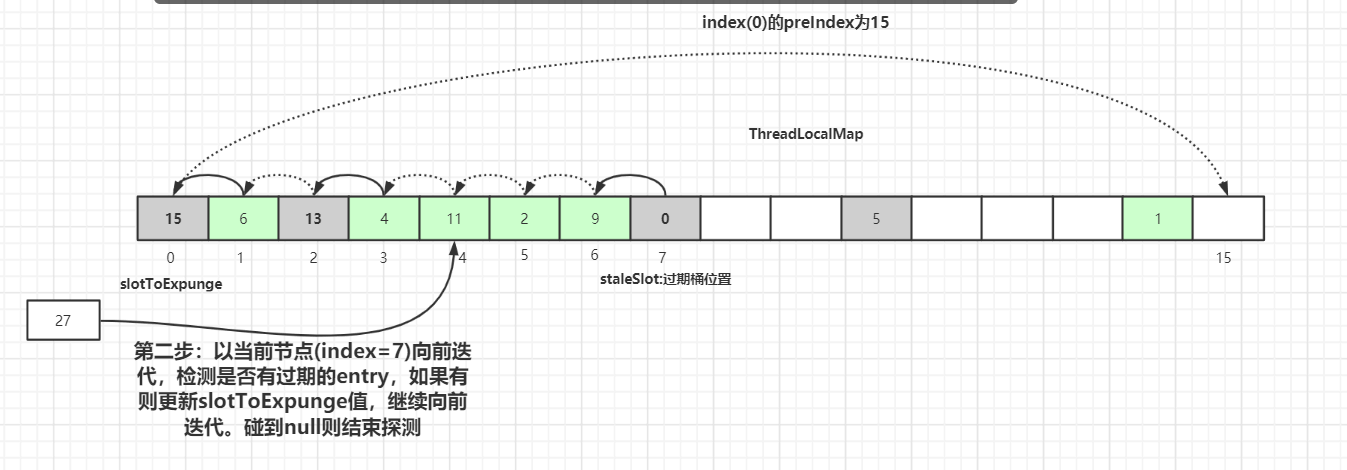
以当前节点(
index=7)向前迭代,检测是否有过期的Entry数据,如果有则更新slotToExpunge值。碰到null则结束探测。以上图为例slotToExpunge被更新为 0。上面向前迭代的操作是为了更新探测清理过期数据的起始下标
slotToExpunge的值,这个值在后面会讲解,它是用来判断当前过期槽位staleSlot之前是否还有过期元素。接着开始以
staleSlot位置(index=7)向后迭代,如果找到了相同 key 值的 Entry 数据: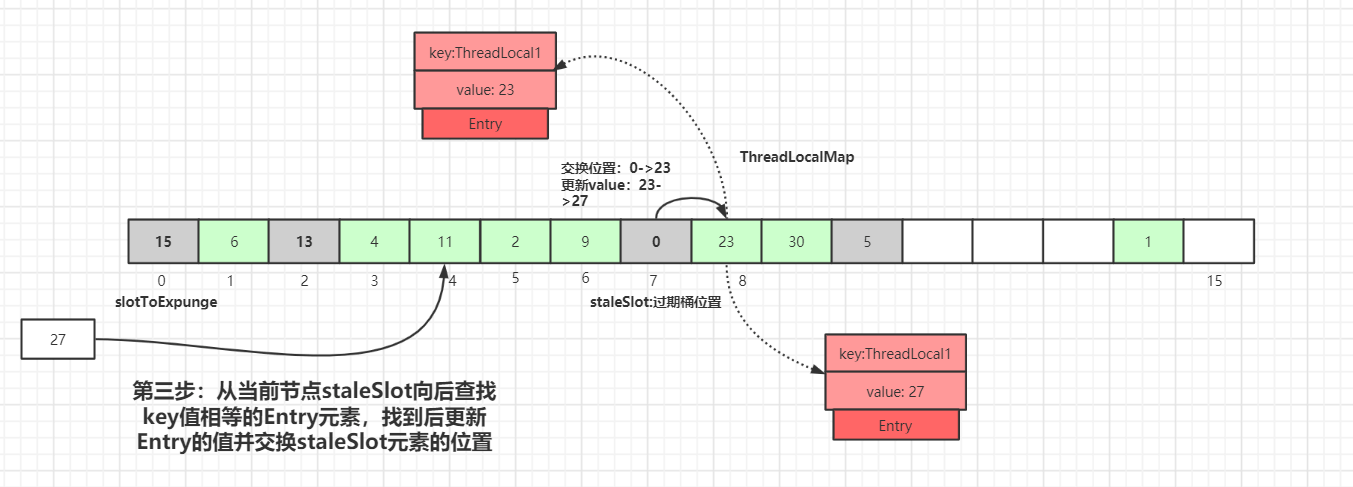
从当前节点
staleSlot向后查找key值相等的Entry元素,找到后更新Entry的值并交换staleSlot元素的位置(staleSlot位置为过期元素),更新Entry数据,然后开始进行过期Entry的清理工作,如下图所示:向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:
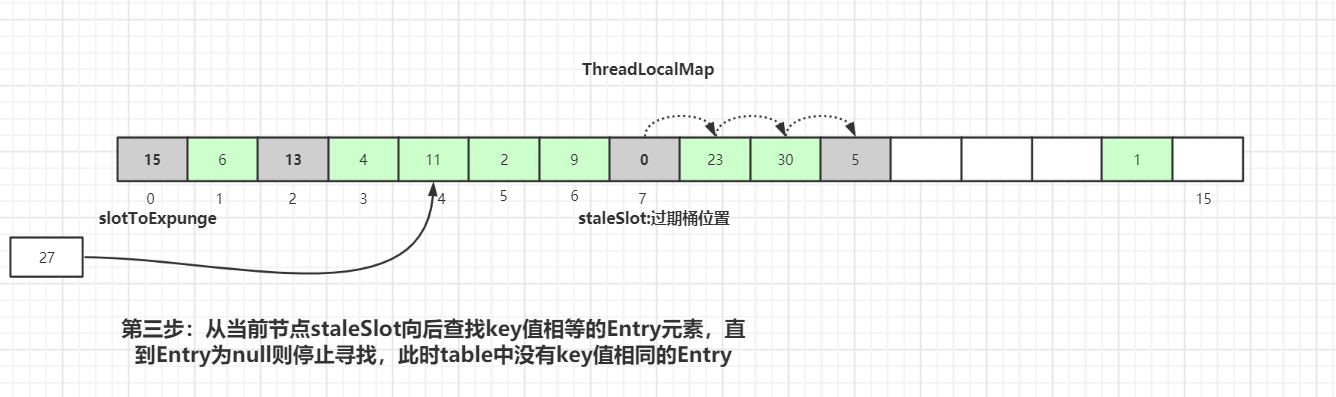
从当前节点
staleSlot向后查找key值相等的Entry元素,直到Entry为null则停止寻找。通过上图可知,此时table中没有key值相同的Entry。创建新的
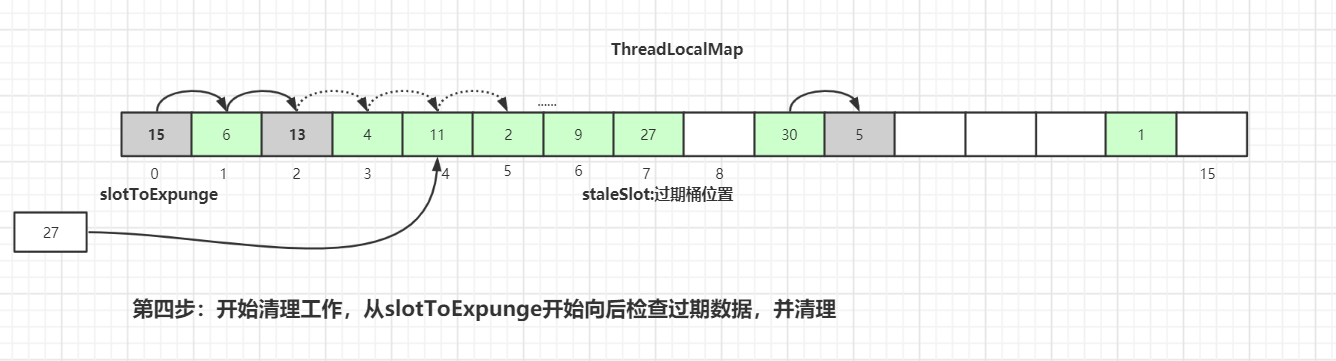
Entry,替换table[stableSlot]位置: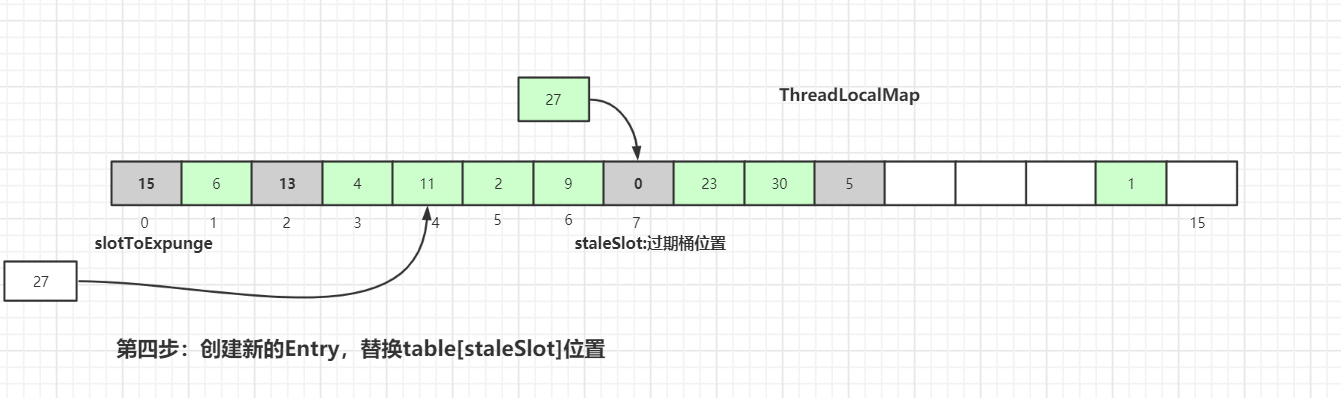
替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:
expungeStaleEntry()和cleanSomeSlots()。
ThreadLocalMap.set()源码详解
上面已经用图的方式解析了set()实现的原理,其实已经很清晰了,我们接着再看下源码:
java.lang.ThreadLocal.ThreadLocalMap.set():
private void set(ThreadLocal<?> key, Object value) { // 这里会通过key来计算在散列表中的对应位置,然后以当前key对应的桶的位置向后查找,找到可以使用的桶。 Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1);
// 接着就是执行for循环遍历,向后查找 // 遍历当前key值对应的桶中Entry数据为空,这说明散列数组这里没有数据冲突,跳出for循环,直接set数据到对应的桶中 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // 如果key值对应的桶中Entry数据不为空 ThreadLocal<?> k = e.get();
// 如果k = key,说明当前set操作是一个替换操作,做替换逻辑,直接返回 if (k == key) { e.value = value; return; }
// 如果key = null,说明当前桶位置的Entry是过期数据,执行replaceStaleEntry()方法(核心方法),然后返回 if (k == null) { replaceStaleEntry(key, value, i); return; } }
// 继续往下执行说明向后迭代的过程中遇到了entry为null的情况 // 在Entry为null的桶中创建一个新的Entry对象,执行++size操作 tab[i] = new Entry(key, value); int sz = ++size; // 调用cleanSomeSlots()做一次启发式清理工作,清理散列数组中Entry的key过期的数据 // 如果清理工作完成后,未清理到任何数据,且size超过了阈值(数组长度的2/3),进行rehash()操作 if (!cleanSomeSlots(i, sz) && sz >= threshold) // rehash()中会先进行一轮探测式清理,清理过期key,清理完成后如果**size >= threshold-threshold/4** 就会执行真正的扩容逻辑 rehash();}
private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0);}
private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1);}什么情况下桶才是可以使用的呢?
k = key说明是替换操作,可以使用- 碰到一个过期的桶,执行替换逻辑,占用过期桶
- 查找过程中,碰到桶中
Entry=null的情况,直接使用
接着重点看下replaceStaleEntry()方法,replaceStaleEntry()方法提供替换过期数据的功能,我们可以对应上面第四种情况的原理图来再回顾下,具体代码如下:
java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry():
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e;
// 表示开始探测式清理过期数据的开始下标,默认从当前的staleSlot开始 int slotToExpunge = staleSlot; // 以当前的staleSlot开始,向前迭代查找,找到没有过期的数据,直到null for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
// 如果向前找到了过期数据,更新探测清理过期数据的开始下标为 i if (e.get() == null) slotToExpunge = i;
// 从staleSlot向后查找,碰到Entry为null的桶结束 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// **碰到 k == key**,这说明这里是替换逻辑 // 替换新数据并且交换当前staleSlot位置 if (k == key) { e.value = value;
tab[i] = tab[staleSlot]; tab[staleSlot] = e;
// 如果slotToExpunge == staleSlot // 这说明replaceStaleEntry()一开始向前查找过期数据时并未找到过期的Entry数据 // 接着向后查找过程中也未发现过期数据 // 修改开始探测式清理过期数据的下标为当前循环的 index,即slotToExpunge = i if (slotToExpunge == staleSlot) slotToExpunge = i; // 调用cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)进行启发式过期数据清理 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // k == null说明当前遍历的Entry是一个过期数据 // slotToExpunge == staleSlot说明,一开始的向前查找数据并未找到过期的Entry // 更新slotToExpunge 为当前位置,这个前提是前驱节点扫描时未发现过期数据 if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // 往后迭代的过程中如果没有找到k==key的数据,且碰到Entry为null的数据,则结束当前的迭代操作 // 此时说明这里是一个添加的逻辑,将新的数据添加到table[staleSlot] 对应的slot中。 tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value);
// 判断除了staleSlot以外,还发现了其他过期的slot数据,就要开启清理数据的逻辑 if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);}ThreadLocalMap过期 key 的探测式清理流程
上面我们有提及ThreadLocalMap的两种过期key数据清理方式:探测式清理和启发式清理。
探测式清理
我们先讲下探测式清理,也就是expungeStaleEntry方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的Entry设置为null,沿途中碰到未过期的数据则将此数据rehash后重新在table数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的Entry=null的桶中,使rehash后的Entry数据距离正确的桶的位置更近一些。操作逻辑如下:
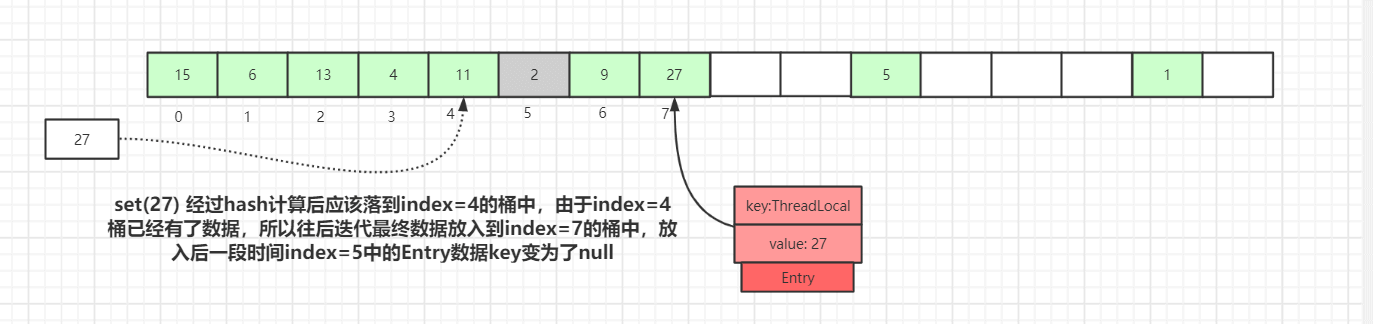
如上图,set(27) 经过 hash 计算后应该落到index=4的桶中,由于index=4桶已经有了数据,所以往后迭代最终数据放入到index=7的桶中,放入后一段时间后index=5中的Entry数据key变为了null
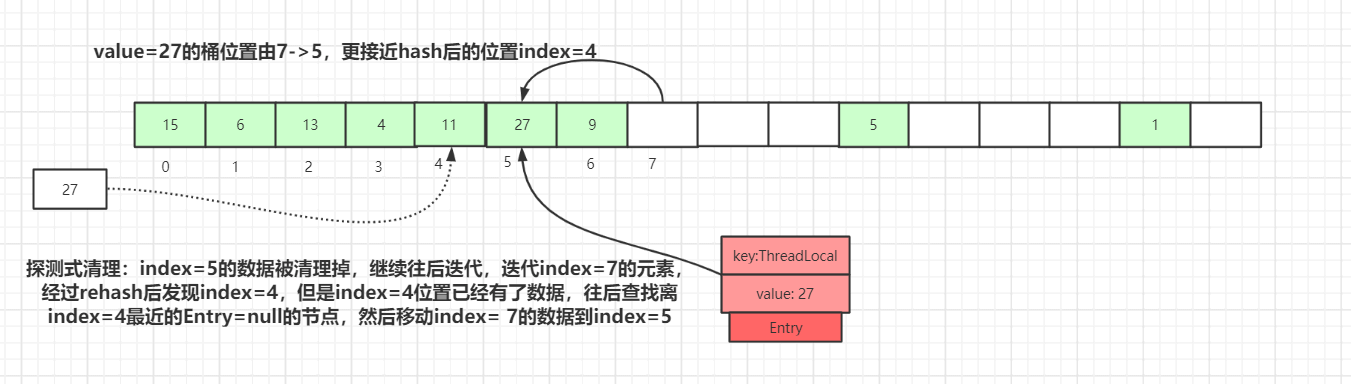
如果再有其他数据set到map中,就会触发探测式清理操作。
如上图,执行探测式清理后,index=5的数据被清理掉,继续往后迭代,到index=7的元素时,经过rehash后发现该元素正确的index=4,而此位置已经有了数据,往后查找离index=4最近的Entry=null的节点(刚被探测式清理掉的数据:index=5),找到后移动index= 7的数据到index=5中,此时桶的位置离正确的位置index=4更近了。
经过一轮探测式清理后,key过期的数据会被清理掉,没过期的数据经过rehash重定位后所处的桶位置理论上更接近i= key.hashCode & (tab.len - 1)的位置。这种优化会提高整个散列表查询性能。
接着看下expungeStaleEntry()具体流程:
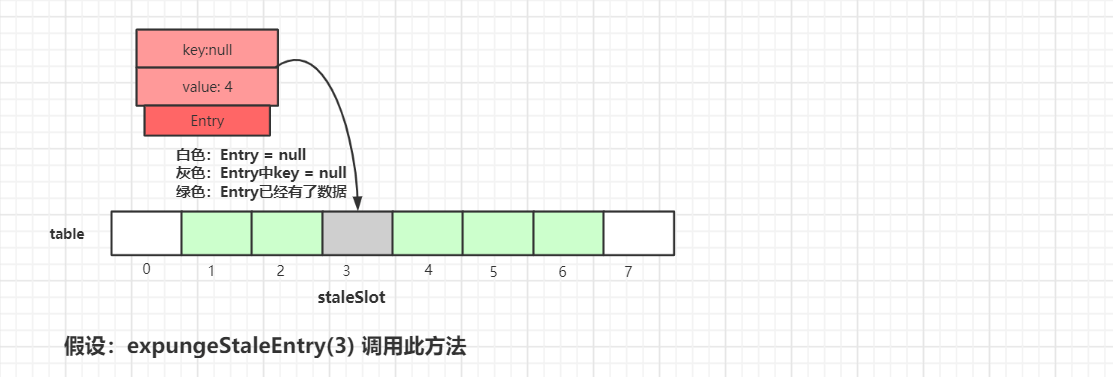
我们假设expungeStaleEntry(3) 来调用此方法,如上图所示,我们可以看到ThreadLocalMap中table的数据情况,接着执行清理操作:
-
清空当前
staleSlot位置的数据,index=3位置的Entry变成了null。然后接着往后探测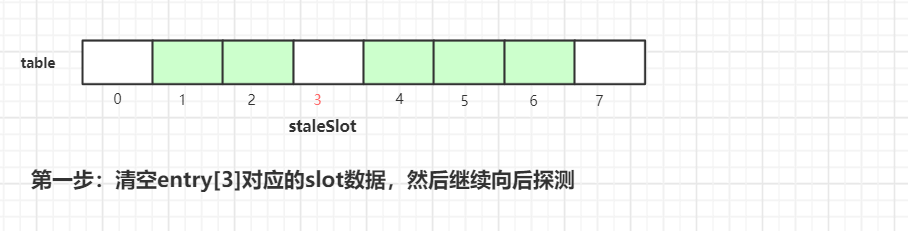
-
继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算
slot位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置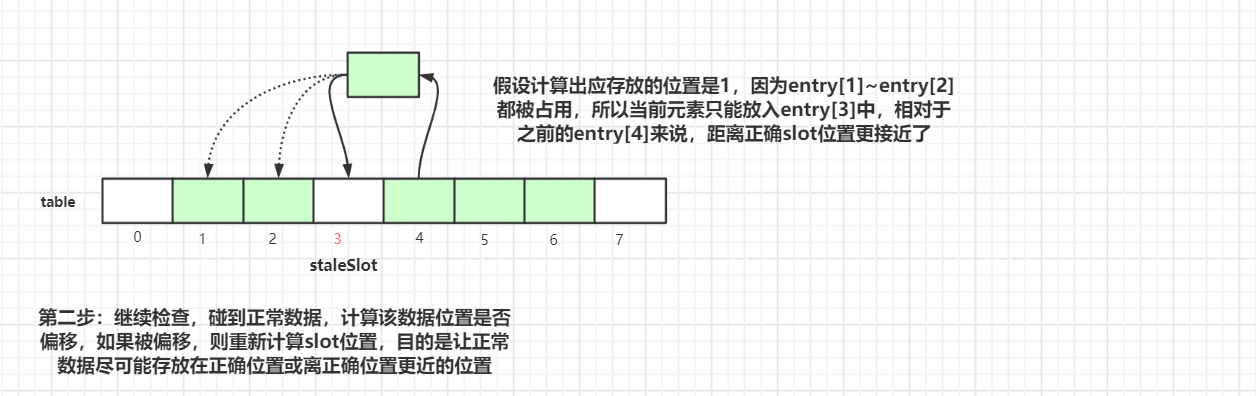
执行完第二步后,index=4 的元素挪到 index=3 的槽位中。
-
在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了
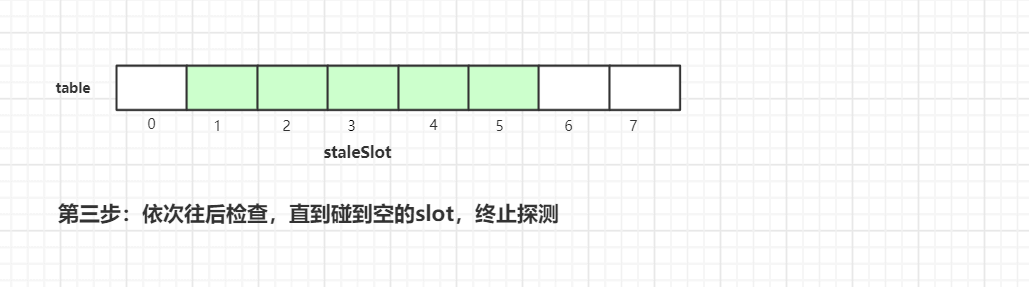
接着我们继续看看具体实现源代码:
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length;
// 将tab[staleSlot]槽位的数据清空,size-1 tab[staleSlot].value = null; tab[staleSlot] = null; size--;
Entry e; int i; // 以staleSlot位置往后迭代 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // 如果遇到k==null的过期数据,也是清空该槽位数据,然后size-- if (k == null) { e.value = null; tab[i] = null; size--; } else { // 如果key没有过期,重新计算当前key的下标位置是不是当前槽位下标位置 // 如果不是,那么说明产生了hash冲突 // 此时以新计算出来正确的槽位位置往后迭代 // 找到最近一个可以存放entry的位置 int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null;
while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i;}这里是处理正常的产生Hash冲突的数据,经过迭代后,有过Hash冲突数据的Entry位置会更靠近正确位置,这样的话,查询的时候 效率才会更高。
启发式清理流程
探测式清理是以当前Entry 往后清理,遇到值为null则结束清理,属于线性探测清理。
而启发式清理被作者定义为:Heuristically scan some cells looking for stale entries.(启发式扫描一些单元格,查找陈旧的条目)
具体代码如下:
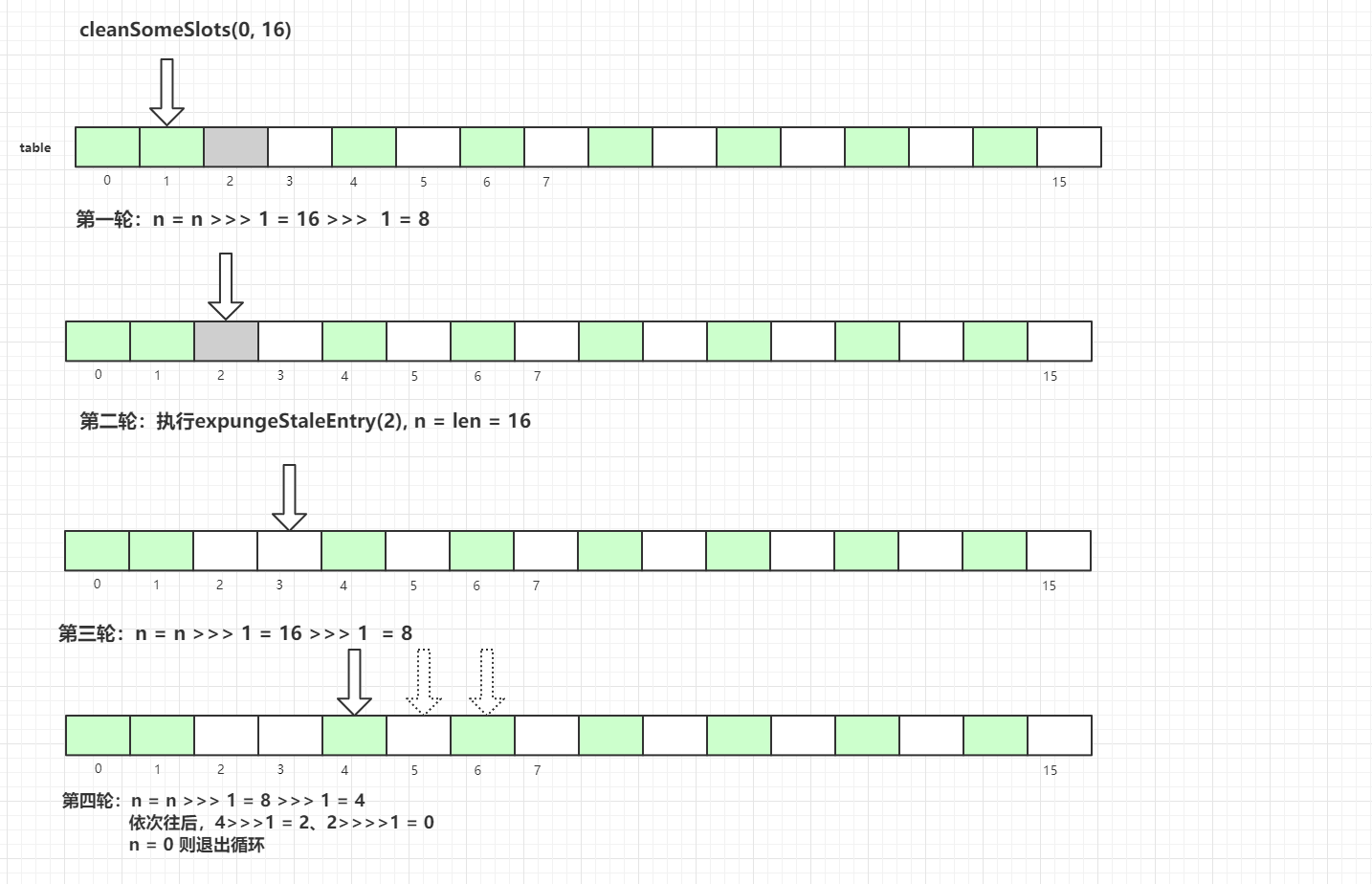
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed;}ThreadLocalMap扩容机制
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();接着看下rehash()具体实现:
private void rehash() { expungeStaleEntries();
if (size >= threshold - threshold / 4) resize();}
private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); }}- 进行探测式清理工作,从
table的起始位置往后清理 - 清理完成之后,
table中可能有一些key为null的Entry数据被清理掉。 - 此时通过判断
size >= threshold - threshold / 4也就是size >= threshold * 3/4来决定是否扩容。
我们还记得上面进行rehash()的阈值是size >= threshold,所以当面试官套路我们ThreadLocalMap扩容机制的时候 我们一定要说清楚这两个步骤。
接着看看具体的resize()方法,为了方便演示,我们以oldTab.len=8来举例:
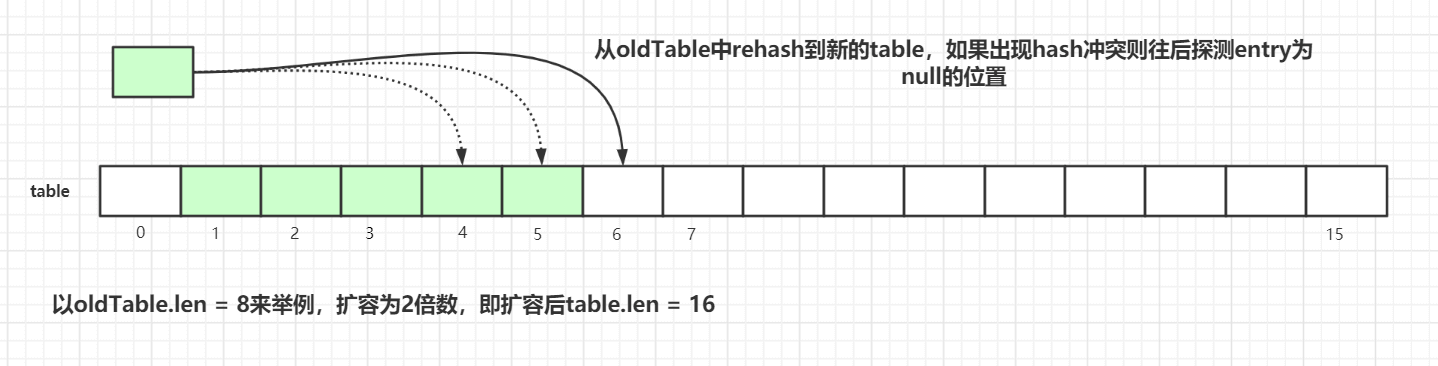
扩容后的tab的大小为oldLen * 2
- 遍历老的散列表,重新计算
hash位置,然后放到新的tab数组中 - 如果出现
hash冲突则往后寻找最近的entry为null的槽位 - 遍历完成之后,
oldTab中所有的entry数据都已经放入到新的tab中了 - 重新计算
tab下次扩容的阈值
具体代码如下:
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; int count = 0;
for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; } else { int h = k.threadLocalHashCode & (newLen - 1); while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } }
setThreshold(newLen); size = count; table = newTab;}ThreadLocalMap.get()详解
上面已经看完了set()方法的源码,其中包括set数据、清理数据、优化数据桶的位置等操作,接着看看get()操作的原理。
ThreadLocalMap.get()图解
-
通过查找
key值计算出散列表中slot位置,然后该slot位置中的Entry.key和查找的key一致,则直接返回: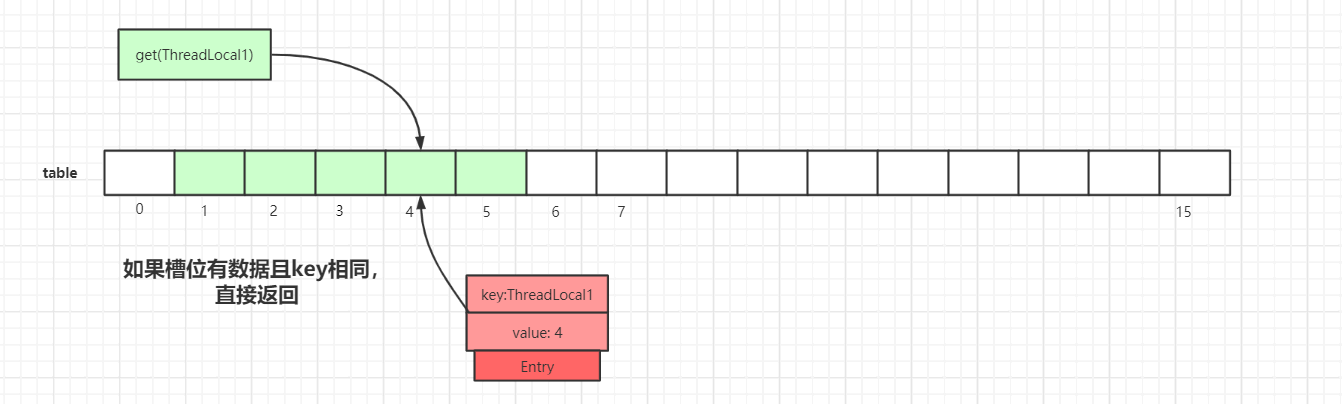
-
slot位置中的Entry.key和要查找的key不一致: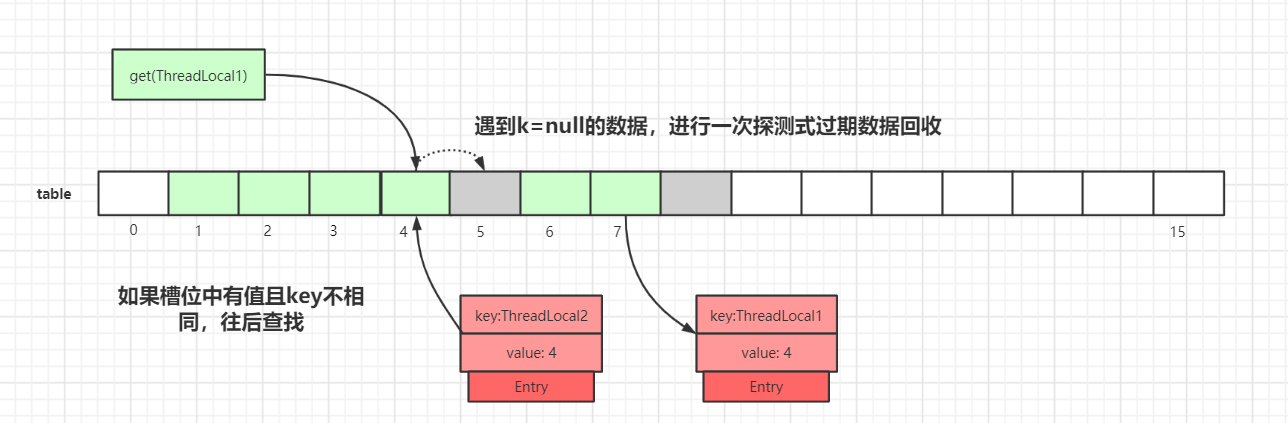
我们以
get(ThreadLocal1)为例,通过hash计算后,正确的slot位置应该是 4,而index=4的槽位已经有了数据,且key值不等于ThreadLocal1,所以需要继续往后迭代查找。迭代到
index=5的数据时,此时Entry.key=null,触发一次探测式数据回收操作,执行expungeStaleEntry()方法,执行完后,index 5,8的数据都会被回收,而index 6,7的数据都会前移。index 6,7前移之后,继续从index=5往后迭代,于是就在index=6找到了key值相等的Entry数据,如下图所示: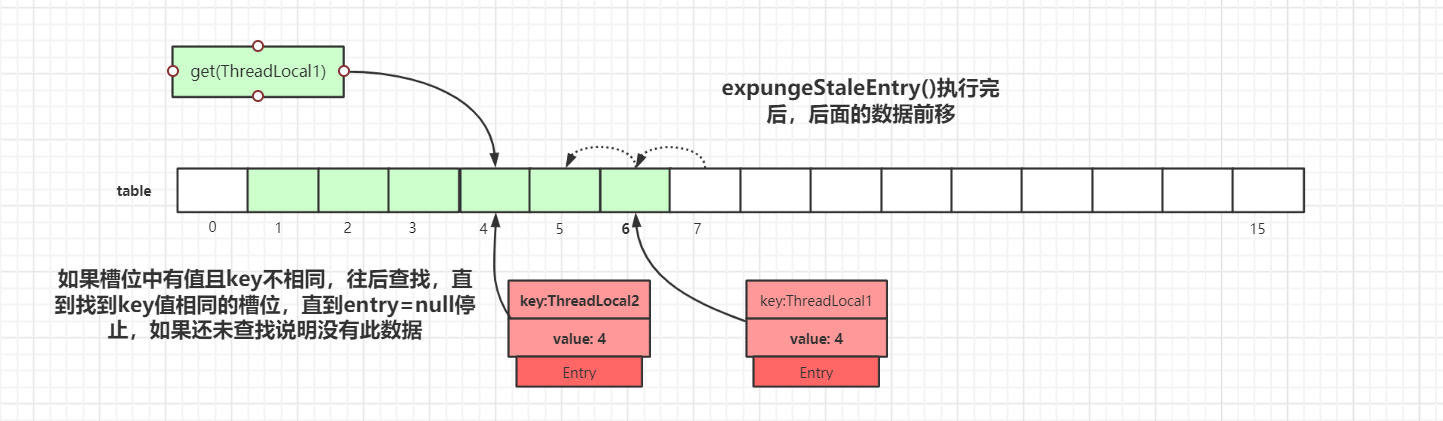
ThreadLocalMap.get()源码详解
java.lang.ThreadLocal.ThreadLocalMap.getEntry():
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e);}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null;}InheritableThreadLocal
我们使用ThreadLocal的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
为了解决这个问题,JDK 中还有一个InheritableThreadLocal类,我们来看一个例子:
public class InheritableThreadLocalDemo { public static void main(String[] args) { ThreadLocal<String> ThreadLocal = new ThreadLocal<>(); ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>(); ThreadLocal.set("父类数据:threadLocal"); inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
new Thread(new Runnable() { @Override public void run() { System.out.println("子线程获取父类ThreadLocal数据:" + ThreadLocal.get()); System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get()); } }).start(); }}打印结果:
子线程获取父类ThreadLocal数据:null子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal实现原理是子线程是通过在父线程中通过调用new Thread()方法来创建子线程,Thread#init方法在Thread的构造方法中被调用。在init方法中拷贝父线程数据到子线程中:
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { if (name == null) { throw new NullPointerException("name cannot be null"); }
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); this.stackSize = stackSize; tid = nextThreadID();}但InheritableThreadLocal仍然有缺陷,一般我们做异步化处理都是使用的线程池,而InheritableThreadLocal是在new Thread中的init()方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个TransmittableThreadLocal组件就可以解决这个问题,这里就不再延伸,感兴趣的可自行查阅资料。
ThreadLocal项目中使用实战
ThreadLocal使用场景
我们现在项目中日志记录用的是ELK+Logstash,最后在Kibana中进行展示和检索。
现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过 traceId 来关联,但是不同项目之间如何传递 traceId 呢?
这里我们使用 org.slf4j.MDC 来实现此功能,内部就是通过 ThreadLocal 来实现的,具体实现如下:
当前端发送请求到服务 A时,服务 A会生成一个类似UUID的traceId字符串,将此字符串放入当前线程的ThreadLocal中,在调用服务 B的时候,将traceId写入到请求的Header中,服务 B在接收请求时会先判断请求的Header中是否有traceId,如果存在则写入自己线程的ThreadLocal中。
requestId即为我们各个系统链路关联的traceId,系统间互相调用,通过这个requestId即可找到对应链路,这里还有会有一些其他场景:
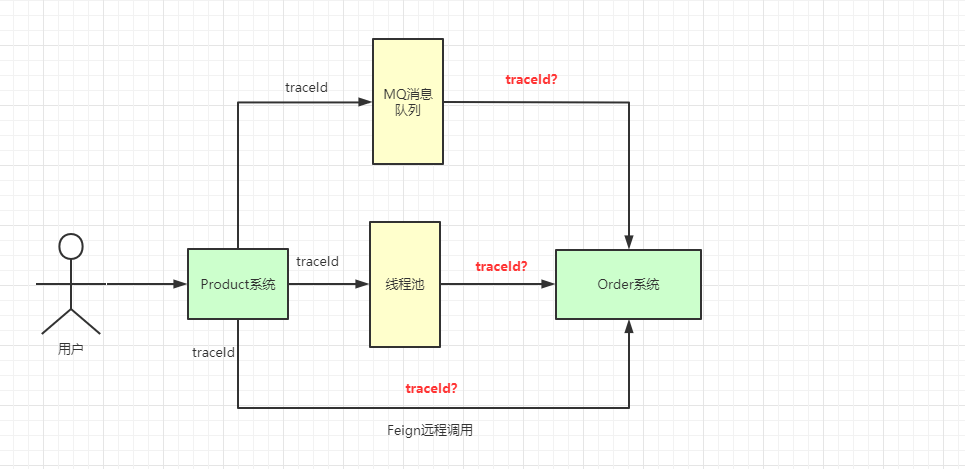
针对于这些场景,我们都可以有相应的解决方案,如下所示
Feign 远程调用解决方案
服务发送请求:
@Component@Slf4jpublic class FeignInvokeInterceptor implements RequestInterceptor {
@Override public void apply(RequestTemplate template) { String requestId = MDC.get("requestId"); if (StringUtils.isNotBlank(requestId)) { template.header("requestId", requestId); } }}服务接收请求:
@Slf4j@Componentpublic class LogInterceptor extends HandlerInterceptorAdapter {
@Override public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) { MDC.remove("requestId"); }
@Override public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) { }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY); if (StringUtils.isBlank(requestId)) { requestId = UUID.randomUUID().toString().replace("-", ""); } MDC.put("requestId", requestId); return true; }}线程池异步调用,requestId 传递
因为MDC是基于ThreadLocal去实现的,异步过程中,子线程并没有办法获取到父线程ThreadLocal存储的数据,所以这里可以自定义线程池执行器,修改其中的run()方法:
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
@Override public void execute(Runnable runnable) { Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> run(runnable, context)); }
@Override private void run(Runnable runnable, Map<String, String> context) { if (context != null) { MDC.setContextMap(context); } try { runnable.run(); } finally { MDC.remove(); } }}使用 MQ 发送消息给第三方系统
在 MQ 发送的消息体中自定义属性requestId,接收方消费消息后,自己解析requestId使用即可。
For ThreadLocal, people’s first reaction might be that it’s simply a per-thread variable copy, with each thread isolated. Here are a few questions you can think about:
- The key of
ThreadLocalis a weak reference. So when callingThreadLocal.get(), after a GC event, is the key null? - What is the data structure of
ThreadLocalMapinsideThreadLocal? - What is the hash algorithm of
ThreadLocalMap? - How are hash collisions resolved in
ThreadLocalMap? - What is the growth mechanism of
ThreadLocalMap? - What is the cleanup mechanism for expired keys in
ThreadLocalMap? The probing cleanup and heuristic cleanup processes? - How does
ThreadLocalMap.set()implement its logic? - How does
ThreadLocalMap.get()implement its logic? - How is
ThreadLocalused in the project? Any caveats? - …
Note: This article’s source code is based on JDK 1.8
ThreadLocal Code Demonstration
We’ll first look at a usage example of ThreadLocal:
public class ThreadLocalTest { private List<String> messages = Lists.newArrayList();
public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) { holder.get().messages.add(message); }
public static List<String> clear() { List<String> messages = holder.get().messages; holder.remove();
System.out.println("size: " + holder.get().messages.size()); return messages; }
public static void main(String[] args) { ThreadLocalTest.add("testsetestse"); System.out.println(holder.get().messages); ThreadLocalTest.clear(); }}Output:
[testsetestse]size: 0ThreadLocal objects can provide thread-local variables; each Thread owns its own copy of the variable, and multiple threads do not interfere with each other.
The data structure of ThreadLocal
The Thread class has an instance variable of type ThreadLocal.ThreadLocalMap named threadLocals, meaning each thread has its own ThreadLocalMap.
ThreadLocalMap has its own independent implementation. Its key can be viewed as the ThreadLocal, and the value is the value stored in the map (in fact, the key is not the ThreadLocal itself, but a weak reference to it).
Whenever a thread puts a value into a ThreadLocal, it stores it in its own ThreadLocalMap; reads also use the ThreadLocal as the reference and search for the corresponding key within its own map, achieving thread isolation.
ThreadLocalMap is somewhat like a HashMap in structure, but while a HashMap is implemented as an array plus linked lists, ThreadLocalMap does not use a linked-list structure.
We should also note that the Entry’s key is ThreadLocal<?> k, which inherits from WeakReference, i.e., it is a weak reference type.
After GC, is the key null?
Addressing the opening question: the key of ThreadLocal is a weak reference. So after a GC event in a ThreadLocal.get() operation, is the key null?
To resolve this, we need to understand Java’s four reference types:
- Strong reference: Objects created with
neware normally strong references. As long as a strong reference exists, the garbage collector will not reclaim the object, even under memory pressure. - Soft reference: Objects referenced via
SoftReferenceare soft references; the referred object is reclaimed when memory is about to overflow. - Weak reference: Objects referenced via
WeakReferenceare weak references; when a GC occurs, if the object is only softly/weakly reachable via weak references, it will be collected. - Phantom reference: The weakest form; in Java, defined via
PhantomReference. The only purpose is to enqueue notifications that an object is about to be reclaimed.
Now looking at the code, we use reflection to inspect the data in GC’d state:
public class ThreadLocalDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException { Thread t = new Thread(()->test("abc",false)); t.start(); t.join(); System.out.println("--gc后--"); Thread t2 = new Thread(() -> test("def", true)); t2.start(); t2.join(); }
private static void test(String s,boolean isGC) { try { new ThreadLocal<>().set(s); if (isGC) { System.gc(); } Thread t = Thread.currentThread(); Class<? extends Thread> clz = t.getClass(); Field field = clz.getDeclaredField("threadLocals"); field.setAccessible(true); Object ThreadLocalMap = field.get(t); Class<?> tlmClass = ThreadLocalMap.getClass(); Field tableField = tlmClass.getDeclaredField("table"); tableField.setAccessible(true); Object[] arr = (Object[]) tableField.get(ThreadLocalMap); for (Object o : arr) { if (o != null) { Class<?> entryClass = o.getClass(); Field valueField = entryClass.getDeclaredField("value"); Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent"); valueField.setAccessible(true); referenceField.setAccessible(true); System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o))); } } } catch (Exception e) { e.printStackTrace(); } }}Output:
弱引用key:java.lang.ThreadLocal@433619b6,值:abc弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12--gc后--弱引用key:null,值:defAs shown, because the ThreadLocal created here does not point to any value yet (i.e., there are no references), the key will be collected after GC, and in the above debug, the referent is null.
If you look at this topic without deeper thought—just considering weak references and garbage collection—it might seem like the key is null.
In fact, that’s not correct, because the scenario described is during a ThreadLocal.get() operation, which proves that there is still a strong reference present, so the key is not null; the strong reference to the ThreadLocal still exists.
If our strong reference did not exist, the key would be collected, which would cause the value to remain and the key to be collected, leading to a memory leak.
The detailed source of ThreadLocal.set()
The principle of the set method in ThreadLocal is as shown in the figure above. It’s simple: mainly checks whether the ThreadLocalMap exists, then uses the set method in ThreadLocal to handle the data.
Code:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value);}
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue);}The core logic is still in ThreadLocalMap.
The hash algorithm of ThreadLocalMap
Since it’s a Map structure, ThreadLocalMap must implement its own hash algorithm to resolve collisions in the hash table array.
int i = key.threadLocalHashCode & (len-1);The hash algorithm in ThreadLocalMap is straightforward. Here, i is the index in the hash table that the current key maps to.
The key point is the calculation of the threadLocalHashCode value. ThreadLocal has a field with the value HASH_INCREMENT = 0x61c88647.
public class ThreadLocal<T> { private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
static class ThreadLocalMap { ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } }}Whenever a ThreadLocal object is created, the value ThreadLocal.nextHashCode increases by 0x61c88647.
This value is special: it is related to the golden ratio. The hash increment being this number yields a very uniform distribution.
ThreadLocalMap hash collisions
Note: In all the sample diagrams below, green blocks representing Entry denote normal data, gray blocks denote Entries whose key value is null (garbage collected), and white blocks denote null entries.
Although ThreadLocalMap uses the golden ratio as the hash factor to greatly reduce collision probability, collisions can still occur.
In a HashMap collisions are resolved by constructing a linked-list structure on the array; conflicting data are attached to the list. If the list grows too long, it may be converted into a red-black tree.
But ThreadLocalMap does not use a linked-list structure, so the HashMap strategy for collisions cannot be used here.
As shown above, if we insert a data with value=27, after hashing it should land in slot 4, but slot 4 already holds an Entry.
At this point, a linear forward probe occurs until a slot with Entry equal to null is found, and the current element is placed there. Of course, during iteration there are other cases, such as encountering an Entry with a non-null key and an equal key value, or an Entry with a null key, etc., each with different handling that will be described in detail later.
We also illustrate an Entry with a null key (a gray block for Entry=2). Because the key is a weak reference, such data can exist. In the set process, if an Entry with an expired key is encountered, a probing cleanup operation will actually be performed.
The detailed explanation of ThreadLocalMap.set()
Diagrammatic explanation of ThreadLocalMap.set()
After understanding the hash algorithm, let’s see how set is implemented.
Setting data in ThreadLocalMap (new or updated) falls into several situations; for each situation, we illustrate with diagrams.
-
The slot computed by the hash points to an empty
Entry:Here we simply place the data into that slot.
-
The slot contains data, and the key equals the current
ThreadLocal’s hashed key:Here we directly update the data in that slot.
-
The slot contains data, and while traversing forward, before finding a slot with
Entryequal to null, we have not encountered an expired key:We traverse the hash array linearly; if we find a slot with
Entryequal to null, we put the data there; or, during traversal, if we encounter data with the same key value, we update it directly. -
The slot contains data, and while traversing forward, before finding a slot with
Entryequal to null, we encounter an expired keyEntryas shown: theEntryat index 7 haskey=null:The hash table index 7 has an
Entrywhosekeyisnull, indicating that this data’s key value has been garbage collected. In this case thereplaceStaleEntry()method is invoked, which handles the logic of replacing expired data. Starting from index 7, it performs a probing cleanup.The initialization of the probing cleanup start position is:
slotToExpunge = staleSlot = 7Starting from the current
staleSlot, we iterate backward to find other expired data, updating the starting scan indexslotToExpunge. The loop ends when it hits anEntrythat isnull.If expired data is found, we continue forward; if we encounter data with the same key value, we update that
Entry’s data and swap thestaleSlotelement with thatEntry(thestaleSlotposition becomes an expired element). After updating theEntrydata, we begin cleaning up expired entries, as shown:If during the backward iteration we do not find an expired data, the forward iteration may not find a matching key; in that case, a new
Entryis created and replaces thetable[staleSlot]position:After replacement, cleanup of expired elements is performed via two methods:
expungeStaleEntry()andcleanSomeSlots().
The source of ThreadLocalMap.set()
The above diagrams already illustrate the principle of set(); the actual code is as follows:
private void set(ThreadLocal<?> key, Object value) { // Determine the slot using the key and then linearly search forward to find a usable bucket. Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1);
// Iterate forward for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // If the bucket’s Entry for the key is not null ThreadLocal<?> k = e.get();
// If k equals key, this is a replacement operation; update and return if (k == key) { e.value = value; return; }
// If k == null, this is an expired entry; perform replaceStaleEntry() and return if (k == null) { replaceStaleEntry(key, value, i); return; } }
// If we get here, we found a null slot after iterating // Create a new Entry in this slot and increment size tab[i] = new Entry(key, value); int sz = ++size; // Perform a heuristic cleanup of expired data // If no cleanup occurred and size exceeds the threshold, perform a rehash if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();}
private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0);}
private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1);}When is a bucket usable?
- The key equals the current key: replacement is allowed.
- When encountering an expired bucket, perform replacement to occupy the expired bucket.
- While traversing, when encountering an
EntrywithEntry=null, use it.
Next, focus on the replaceStaleEntry() method, which provides the logic to replace expired data. We can map this to the fourth scenario’s principle diagram. The code is:
java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry() …private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e;
// Start of probing cleanup: begin from the current staleSlot int slotToExpunge = staleSlot; // Walk backward from the current staleSlot, until we encounter null for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
// If an expired entry is found, update the start of probing cleanup if (e.get() == null) slotToExpunge = i;
// Walk forward from staleSlot; until we encounter a null Entry for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// If we meet the same key, this is a replacement // Replace the data and swap the staleSlot element if (k == key) { e.value = value;
tab[i] = tab[staleSlot]; tab[staleSlot] = e;
// If the initial probe didn’t find stale data // set the new starting expunge index to i if (slotToExpunge == staleSlot) slotToExpunge = i; // Clean up with a heuristic cleanup cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // If key is null, and slotToExpunge == staleSlot // update slotToExpunge to i if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // If no matching key is found, add a new entry at staleSlot tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value);
// If there were other expired slots, start cleanup if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);}The probing cleanup flow for expired keys in ThreadLocalMap
We mentioned two ways to clean expired keys in ThreadLocalMap: probing cleanup and heuristic cleanup.
Probing cleanup
Probing cleanup is performed by the expungeStaleEntry method. It traverses the hash array from a starting position forward, clearing expired entries, and rehashing encountered non-expired entries to nearer-than-cur-slot positions if needed. The logic is as follows:
As shown, after set(27), the hashed position would be index 4, but index 4 already contains data. It then iterates forward to eventually place at index 7. After some time, the key at index 5 becomes null due to expiration.
If additional data is set into the map, probing cleanup is triggered.
After probing cleanup, the data at index 5 is cleared, the iteration continues, and after rehashing, the element at index 7 ends up at index 4. The nearest null slot is used to place the data that has been probed, making positions closer to the correct index.
One probing cleanup pass clears expired keys; after rehashing, non-expired entries are placed closer to their correct bucket positions, improving lookup performance.
Next, we examine the exact implementation of the cleanup process:
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length;
// Clear the stale slot and decrease size tab[staleSlot].value = null; tab[staleSlot] = null; size--;
Entry e; int i; // Iterate forward from the staleSlot for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // If the key has expired if (k == null) { e.value = null; tab[i] = null; size--; } else { // If the key hasn’t expired, recalculate its index int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null;
while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i;}This handles the normal cases where a hash collision occurred; after probing, entries are moved to closer positions, improving lookup efficiency.
Heuristic cleanup flow
Probing cleanup is a linear probe cleanup from the current entry forward until a null is encountered.
Heuristic cleanup, defined by the author as: Heuristically scan some cells looking for stale entries.
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed;}The growth mechanism of ThreadLocalMap
In ThreadLocalMap.set(), after performing heuristic cleanup, if nothing was cleaned and the size has reached the threshold (len * 2/3), it triggers a rehash:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();Next, the implementation of rehash() is as follows:
private void rehash() { expungeStaleEntries();
if (size >= threshold - threshold / 4) resize();}
private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); }}- Perform probing cleanup across the table from the start.
- After cleanup, there may be entries with
nullkeys; this is removed byexpungeStaleEntries(). - Then, based on the condition
size >= threshold - threshold / 4(i.e.,size >= 3/4 of threshold), decide whether to expand.
When asked about the expansion mechanism, it’s important to mention these two steps.
Next, the actual resize() method (for demonstration, consider an example where oldTab.len = 8):
The new table size is oldLen * 2.
- Traverse the old hash table, recompute hash positions, and place entries into the new table.
- If a hash conflict occurs, pick the nearest slot whose
Entryisnull. - After traversal, all entries from the old table have been moved into the new one.
- Recompute the next expansion threshold for the new table.
Code:
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; int count = 0;
for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; } else { int h = k.threadLocalHashCode & (newLen - 1); while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } }
setThreshold(newLen); size = count; table = newTab;}ThreadLocalMap.get() Detailed Explanation
We’ve just covered set(); now let’s examine how get() works.
Diagram of ThreadLocalMap.get()
-
Compute the slot from the key; if the
Entry.keyin that slot matches the searched key, return it: -
If the
Entry.keyin the slot does not match the searched key:
We take get(ThreadLocal1) as an example. After hashing, the correct slot would be 4, but index 4 already has data whose key is not ThreadLocal1, so we need to continue iterating.
When we reach index 5, the Entry.key is null. This triggers a probing cleanup operation via expungeStaleEntry(). After cleanup, data at index 5 and 8 are cleared, and data at indices 6 and 7 move forward. After moving forward, we resume from index 5 and continue to index 6, where we find the entry whose key matches, as shown:
The source of ThreadLocalMap.get() code
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e);}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null;}InheritableThreadLocal
When using ThreadLocal, in asynchronous scenarios you cannot share the parent thread’s copy of data with child threads.
To solve this, there is InheritableThreadLocal in the JDK. Consider the following example:
public class InheritableThreadLocalDemo { public static void main(String[] args) { ThreadLocal<String> ThreadLocal = new ThreadLocal<>(); ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>(); ThreadLocal.set("Parent data: threadLocal"); inheritableThreadLocal.set("Parent data: inheritableThreadLocal");
new Thread(new Runnable() { @Override public void run() { System.out.println("Child thread obtains parent ThreadLocal data: " + ThreadLocal.get()); System.out.println("Child thread obtains parent inheritableThreadLocal data: " + inheritableThreadLocal.get()); } }).start(); }}Output:
Child thread obtains parent ThreadLocal data:nullChild thread obtains parent inheritableThreadLocal data:Parent data: inheritableThreadLocalThe principle is that when a child thread is created by the parent thread via new Thread(), the Thread#init method is invoked during the thread’s construction. In the init method, the parent thread’s data is copied to the child thread:
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { if (name == null) { throw new NullPointerException("name cannot be null"); }
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); this.stackSize = stackSize; tid = nextThreadID();}But InheritableThreadLocal still has limitations. In practice, asynchronous processing often uses thread pools, and InheritableThreadLocal assigns values in the child thread’s init() method, while thread pools reuse threads, which can cause issues.
Of course, there are solutions. Alibaba open-sourced a TransmittableThreadLocal component to solve this problem. I won’t go into it further here; you can explore it if you’re interested.
Practical usage of ThreadLocal in projects
Use cases for ThreadLocal
In our project, we use ELK+Logstash for logging, and Kibana for viewing and searching.
All services are typically exposed in a distributed system; cross-service calls can be linked with a traceId. But how is the traceId passed across different projects?
We use org.slf4j.MDC to implement this, which internally relies on ThreadLocal. The implementation is as follows:
When a request hits Service A, Service A generates a string traceId similar to a UUID and places it in the current thread’s ThreadLocal. When calling Service B, the traceId is written into the request’s headers. Service B, on receiving the request, first checks if the header contains traceId, and if present, writes it into its own thread’s ThreadLocal.
requestId is the cross-system trace identifier; inter-service calls use it to locate the corresponding path. There are also other scenarios:
For these scenarios, there are corresponding solutions, as shown below.
Feign remote invocation solution
Service sending request:
@Component@Slf4jpublic class FeignInvokeInterceptor implements RequestInterceptor {
@Override public void apply(RequestTemplate template) { String requestId = MDC.get("requestId"); if (StringUtils.isNotBlank(requestId)) { template.header("requestId", requestId); } }}Service receiving request:
@Slf4j@Componentpublic class LogInterceptor extends HandlerInterceptorAdapter {
@Override public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) { MDC.remove("requestId"); }
@Override public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) { }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY); if (StringUtils.isBlank(requestId)) { requestId = UUID.randomUUID().toString().replace("-", ""); } MDC.put("requestId", requestId); return true; }}Thread pool asynchronous invocation, passing requestId
Because MDC is based on ThreadLocal, in asynchronous operations, child threads cannot access the parent thread’s ThreadLocal data. You can customize the thread pool executor and modify its run() method:
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
@Override public void execute(Runnable runnable) { Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> run(runnable, context)); }
@Override private void run(Runnable runnable, Map<String, String> context) { if (context != null) { MDC.setContextMap(context); } try { runnable.run(); } finally { MDC.remove(); } }}Use MQ to send messages to a third-party system
In the MQ message body, add a custom property requestId. The receiver consumes the message and can parse the requestId for use.
ThreadLocal に関して、みなさんの最初の反応はとてもシンプルだと思います。スレッドの変数の副本で、各スレッドは分離されています。では、ここでいくつか考えるべき問題を挙げてみましょう:
- ThreadLocal の key は弱参照です。では ThreadLocal.get() のとき、 GC が発生した後、 key は null になりますか?
- ThreadLocalMap のデータ構造は?
- ThreadLocalMap のハッシュアルゴリズムは?
- ThreadLocalMap のハッシュ衝突はどう解決される?
- ThreadLocalMap の拡張機構は?
- ThreadLocalMap の過期キーのクリーンアップ機構は? 探索型クリーニングとヒューリスティッククリーニングのフローは?
- ThreadLocalMap.set() の実装原理?
- ThreadLocalMap.get() の実装原理?
- プロジェクトでの ThreadLocal の使用状況?直面した落とし穴は?
- ……
注記: 本文のソースコードは JDK 1.8 に基づいています
ThreadLocalコード演示
まずは ThreadLocal の使用例を見てみましょう:
public class ThreadLocalTest { private List<String> messages = Lists.newArrayList();
public static final ThreadLocal<ThreadLocalTest> holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) { holder.get().messages.add(message); }
public static List<String> clear() { List<String> messages = holder.get().messages; holder.remove();
System.out.println("size: " + holder.get().messages.size()); return messages; }
public static void main(String[] args) { ThreadLocalTest.add("testsetestse"); System.out.println(holder.get().messages); ThreadLocalTest.clear(); }}出力結果:
[testsetestse]size: 0ThreadLocal オブジェクトはスレッドローカル変数を提供します。各スレッドは自分自身の副本変数を持ち、複数のスレッドは互いに干渉しません。
ThreadLocal のデータ構造
Thread クラスには型が ThreadLocal.ThreadLocalMap のインスタンス変数 threadLocals があり、つまり各スレッドは自分自身の ThreadLocalMap を持っています。
ThreadLocalMap は独自実装を持っており、その key を ThreadLocal と見なし、value はコード中に格納される値です(実際には key は ThreadLocal 本体ではなく、それの弱参照です)。
各スレッドが ThreadLocal に値を格納するときは自分の ThreadLocalMap に格納します。読み取りも ThreadLocal をキーとして自分の map の中で対応する key を探すことで、スレッドごとの隔離を実現します。
ThreadLocalMap は HashMap のような構造をしているものの、HashMap が配列+リストで実装されているのに対して、ThreadLocalMap にはリスト構造はありません。
また Entry の key は ThreadLocal<?> k で、WeakReference を継承しており、つまり弱参照タイプであることに留意します。
GC 後に key は null になるか?
冒頭の問題への回答として、ThreadLocal の key は弱参照です。では ThreadLocal.get() を実行し、GC が発生した後、key は null になるのでしょうか?
この問題を理解するには、Java の4種類の参照型を知る必要があります:
- 強参照:通常私たちが new で作るオブジェクト。強参照が存在する限り GC は回収しません。
- ソフト参照 SoftReference:メモリが不足する時に回収される可能性がある参照。
- 弱参照 WeakReference:GC が発生すると、弱参照だけに指されているオブジェクトは回収されます。
- 虚引用 PhantomReference:最も弱い参照で、ファントム参照は死亡通知をキューに受け取る用途だけのもの。
コードを反射で見て、GC 後の ThreadLocal のデータ状況を確認してみます:
public class ThreadLocalDemo {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException { Thread t = new Thread(()->test("abc",false)); t.start(); t.join(); System.out.println("--gc后--"); Thread t2 = new Thread(() -> test("def", true)); t2.start(); t2.join(); }
private static void test(String s,boolean isGC) { try { new ThreadLocal<>().set(s); if (isGC) { System.gc(); } Thread t = Thread.currentThread(); Class<? extends Thread> clz = t.getClass(); Field field = clz.getDeclaredField("threadLocals"); field.setAccessible(true); Object ThreadLocalMap = field.get(t); Class<?> tlmClass = ThreadLocalMap.getClass(); Field tableField = tlmClass.getDeclaredField("table"); tableField.setAccessible(true); Object[] arr = (Object[]) tableField.get(ThreadLocalMap); for (Object o : arr) { if (o != null) { Class<?> entryClass = o.getClass(); Field valueField = entryClass.getDeclaredField("value"); Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent"); valueField.setAccessible(true); referenceField.setAccessible(true); System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o))); } } } catch (Exception e) { e.printStackTrace(); } }}結果は以下のとおり:
弱引用key:java.lang.ThreadLocal@433619b6,値:abc弱引用key:java.lang.ThreadLocal@418a15e3,値:java.lang.ref.SoftReference@bf97a12--gc后--弱引用key:null,值:def図のとおり、ここでは作成した ThreadLocal がいずれも値を指していない、すなわち参照がない状態です。そのため GC 後、key は回収され、デバッグの referent=null が見えます。
この問題を最初に見たとき、弱参照とガベージコレクションだけを思い浮かべると、確かに null になると考えがちですが、実際には ThreadLocal.get() 操作を行っている場合には強参照がまだ存在するため、key は null にはなりません。強参照が存在する限り、key は回収されず、value も存続します。もし強参照が存在しなければ、key は回収され、結果的にメモリリークが発生する恐れがあります。
ThreadLocal.set() のソースコード解説
ThreadLocal の set メソッドの原理は上の図のとおりです。基本は ThreadLocalMap が存在するかどうかの判定と、ThreadLocal の set によるデータ処理です。
コードは以下のとおり:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value);}
void createMap(Thread t, T firstValue) { t.threadLocals = new ThreadLocalMap(this, firstValue);}核心は ThreadLocalMap 側のロジックにあります。
ThreadLocalMap のハッシュアルゴリズム
Map 構造である以上、ThreadLocalMap もハッシュテーブルの衝突を解決する独自のアルゴリズムを持ちます。
int i = key.threadLocalHashCode & (len-1);ThreadLocalMap のハッシュアルゴリズムはとてもシンプルで、ここの i が現在のキーがハッシュテーブル内で対応する配列のインデックス位置です。
ここで最も重要なのは、threadLocalHashCode の値の計算です。ThreadLocal には HASH_INCREMENT = 0x61c88647 という属性があります。
public class ThreadLocal<T> { private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
static class ThreadLocalMap { ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); } }}ThreadLocal オブジェクトを新たに作成するたびに、ThreadLocal.nextHashCode の値は 0x61c88647 増加します。
この値は非常に特別で、フィボナッチ数、いわゆる黄金比です。ハッシュの増分としてこの数を用いると、ハッシュの分布が非常に均一になります。
ThreadLocalMap のハッシュ衝突
注記: 以下のすべての図では、緑色のブロック Entry は通常データ、灰色のブロックは Entry の key が null になりゴミ箱化済み、白色のブロックは Entry 自体が null です。
ThreadLocalMap では黄金比をハッシュ計算因子として用いて衝突の確率を大きく低減していますが、それでも衝突は発生します。
HashMap では衝突を解決する手法として、配列上にリンクリスト構造を作成します。衝突データはリストに付けられ、リストの長さが一定以上になると赤黒木に変換されます。
一方、ThreadLocalMap にはリンクリスト構造がありません。したがって衝突を HashMap の解法で扱うことはできません。
上図のように、値を 27 として挿入した場合、ハッシュ計算後にはスロット 4 に入るはずですが、すでにスロット 4 にはエントリが存在します。
この時点で直線的に後方へ探索して、Entry が null のスロットを見つけるまで探査を続け、現在の要素をそのスロットに格納します。もちろん、反復の途中で他にも、Entry が null ではない場合や、キーの値が等しい場合、あるいは Entry のキーが null の場合など、さまざまなケースの処理があります。後述で詳しく説明します。
また、キーが null のデータ(Entry=2 の灰色のブロック)も描かれています。これはキーが弱参照型であるために起こるデータです。set の過程で、キーが過期の Entry データに遭遇すると、実際には一度の探査型クリーニングが行われます。
ThreadLocalMap.set() の詳解
ThreadLocalMap.set() の原理図解
ThreadLocal のハッシュアルゴリズムを見た後、set がどのように実装されているかを見ていきます。
ThreadLocalMap にデータを設定(新規 or 更新)する場合、いくつかのケースに分かれ、それぞれ図で解説します。
-
ハッシュで計算されたスロットの
Entryデータが空このスロットにそのままデータを格納します。
-
スロットのデータが空でなく、
keyが現在のThreadLocalがハッシュ計算で得たkeyと一致このスロットのデータを直接更新します。
-
スロットのデータが空でなく、後方へ走査中に
Entryが null になる前に、過去にkeyが過期のEntryが現れなかった場合ハッシュ配列を走査し、線形に後方へ探査します。
Entryが null のスロットを見つけた場合にデータを格納します。途中、Entryのキーが等しいケースや、Entryのキーが null のケースなど、さまざまな分岐があります。 -
スロットのデータが空でなく、後方へ走査中に、過期の
Entryに遭遇した場合。下図のように、index=7のスロットのEntryのkeyが null となっているケースハッシュ配列のインデックス 7 にある
Entryのkeyが null のため、このデータのkeyは GC によって回収済みであることを示します。この時点でreplaceStaleEntry()メソッドを実行します。replaceStaleEntry()は「期限切れデータを置換する」ロジックで、開始点を index=7 から探査を実行します。初期化:
slotToExpunge = staleSlot = 7現在の
staleSlotから前方へ走査して、他の期限切れデータを探し、過期データの開始スキャン位置slotToExpungeを更新します。forループはEntryが null になるまで、前方へ進みます。もし過期データが見つかれば、前方へ進み続け、
Entryが null になるまで探索を続け、探索開始位置を更新します。例えば上図ではslotToExpungeが 0 に更新されます。続いて
staleSlotの位置( index=7 )から後方へ走査し、同じキー値を持つEntryデータを見つけた場合は、値を更新して、staleSlotのエントリと交換します。これにより過期エントリをクリーニングします。後方を走査して同じキーを持つ
Entryが見つからなかった場合は、新しいEntryを作成してtable[staleSlot]を置換します。置換完了後も、過期要素のクリーニングを行います。主に
expungeStaleEntry()とcleanSomeSlots()の二つのメソッドが用いられます。
ThreadLocalMap の過期キーの探査型クリーニングの流れ
上記では、ThreadLocalMap の過期キーのクリーニングには「探索型クリーニング」と「ヒューリスティッククリーニング」の二つの方法があると説明しました。
探索型クリーニング
探索型クリーニング、すなわち expungeStaleEntry メソッドを見ていきます。ハッシュテーブル配列を前方へ走査して過期データをクリーニングします。過期データの Entry を null に設定します。途中で未過期データに遭遇した場合、それを再ハッシュして再配置します。もし再配置先がすでにデータを含んでいる場合は、過去のデータを現在の位置に近い「Entry=null」の桶へ移動します。これにより、再ハッシュ後の Entry データが正しい桶の位置に近づくようになります。操作の流れは以下のとおりです:
上図のように、set(27) はハッシュ計算後に index=4 の桶に落ちるはずですが、 index=4 には既にデータがあるため、後方へ走査して最終的に index=7 の桶に格納されます。格納直後、index=5 のデータのキーが null に変わります。
他のデータがさらに map に set されると、探索型クリーニングが発生します。
上図のように探索型クリーニングを実行すると、 index=5 のデータがクリアされ、さらに後方へ進んで index=7 の要素を見つけ、再ハッシュ後にこの要素は実際には index=4 に正しく落ちていることが分かります。しかしこの場所には既にデータがあるため、index=4 に最も近い「キーが null のエントリ」を探し、 index=5 に index=7 のデータを移動します。これにより、正しい位置 index=4 により近く配置されます。
この探索型クリーニングを一巡行うと、過期キーのデータはクリアされ、過期でないデータは再ハッシュ後により正しい位置に近づくため、全体の検索性能が向上します。
expungeStaleEntry() の具体的な実装は以下のとおりです:
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length;
// staleSlot のデータをクリアして size をデクリメント tab[staleSlot].value = null; tab[staleSlot] = null; size--;
Entry e; int i; // staleSlot を起点に後方へ走査 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // キーが null の場合はクリア if (k == null) { e.value = null; tab[i] = null; size--; } else { // キーが過去でない場合、ハッシュの新しい位置を計算して再配置 int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null;
while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i;}ここでは過去データの「通常の衝突データ」を処理します。反復の末尾に近い位置へと再配置が進むため、検索の効率が高まります。
ヒューリスティッククリーニング
探索型クリーニングの後に、作者が定義したヒューリスティッククリーニングが行われます。
具体的なコードは以下です:
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed;}ThreadLocalMap の拡張機構
ThreadLocalMap.set() の末尾で、ヒューリスティッククリーニングを行ってもデータがクリアされず、かつ現在のハッシュテーブルの Entry の数が拡張閾値( len * 2 / 3 )に達した場合、rehash() を実行します。
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();rehash() の具体的実装は以下の通り:
private void rehash() { expungeStaleEntries();
if (size >= threshold - threshold / 4) resize();}
private void expungeStaleEntries() { Entry[] tab = table; int len = tab.length; for (int j = 0; j < len; j++) { Entry e = tab[j]; if (e != null && e.get() == null) expungeStaleEntry(j); }}- 探索型クリーニングを実行し、テーブル全体の過期データをクリアします。
- クリア後、
tableにキーが null のEntryが残っている可能性があるため、それをexpungeStaleEntryで整理します。 - さらに、
size >= threshold - threshold / 4、すなわちsize >= threshold * 3/4で拡張するかを判断します。
なお、rehash() の閾値は元々 size >= threshold です。面接でこの拡張機構を尋ねられたときには、この二段階の説明を必ず含めてください。
続いて resize() の実装。デモの都合上、oldTab.len=8 を例にします:
拡張後の tab のサイズは oldLen * 2 です。
- 古いハッシュ表を走査し、再計算したハッシュ位置に新しい
tab配列へ格納します。 - 衝突が発生した場合は、最近の
entryが null となるスロットを探して格納します。 - 走査完了後、古い
oldTabの全てのエントリデータを新しいtabに移します。 - 次回の拡張の閾値を再計算します。
private void resize() { Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; Entry[] newTab = new Entry[newLen]; int count = 0;
for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; } else { int h = k.threadLocalHashCode & (newLen - 1); while (newTab[h] != null) h = nextIndex(h, newLen); newTab[h] = e; count++; } } }
setThreshold(newLen); size = count; table = newTab;}ThreadLocalMap.get() 詳解
上記で set() の挙動を見ましたので、次は get() の仕組みを見ていきます。
ThreadLocalMap.get() の図解
-
キーの値を探索してハッシュからスロット位置を求め、そこに格納されている
Entry.keyが検索したkeyと一致すれば返します。 -
スロットの
Entry.keyが検索したkeyと一致しない場合:
例えば get(ThreadLocal1) を例にとると、ハッシュ計算後の正しいスロット位置は 4 ですが、 index=4 のスロットにはデータがあり、キーが ThreadLocal1 と等しくありません。そのため後方へと反復して探します。
index=5 へ到達した時、Entry.key が null になり、探査がトリガーされます。expungeStaleEntry() を実行すると、 index=5,8 のデータが回収され、 index=6,7 のデータは前へ移動します。移動後、再度 index=5 から後方へ反復を継ぎ、 index=6 でキーが等しい Entry を見つけます。
このようにして目的の Entry を見つけることができます。
ThreadLocalMap.get() のソースコード詳細
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); Entry e = table[i]; if (e != null && e.get() == key) return e; else return getEntryAfterMiss(key, i, e);}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length;
while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null;}InheritableThreadLocal
ThreadLocal を使うと、非同期の場面では親スレッドで作成したスレッドローカルデータを子スレッドに共有できません。
この問題を解決するために JDK には InheritableThreadLocal が用意されています。例を見てみましょう:
public class InheritableThreadLocalDemo { public static void main(String[] args) { ThreadLocal<String> ThreadLocal = new ThreadLocal<>(); ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>(); ThreadLocal.set("父クラスのデータ:threadLocal"); inheritableThreadLocal.set("父クラスのデータ:inheritableThreadLocal");
new Thread(new Runnable() { @Override public void run() { System.out.println("子スレッドでの父スレッドの ThreadLocal データ:" + ThreadLocal.get()); System.out.println("子スレッドでの父スレッドの inheritableThreadLocal データ:" + inheritableThreadLocal.get()); } }).start(); }}出力結果:
子スレッドでの父スレッドの ThreadLocal データ:null子スレッドでの父スレッドの inheritableThreadLocal データ:父クラスのデータ:inheritableThreadLocal実装原理として、子スレッドは父スレッドの Thread の init の際にデータをコピーします。Thread#init は Thread のコンストラクタ内で呼び出され、inheritThreadLocals が有効な場合、親スレッドのデータを子スレッドへコピーします。
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc, boolean inheritThreadLocals) { if (name == null) { throw new NullPointerException("name cannot be null"); }
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); this.stackSize = stackSize; tid = nextThreadID();}ただし InheritableThreadLocal には欠点があり、通常は非同期処理にはスレッドプールを用います。スレッドプールはスレッドを再利用するため、InheritableThreadLocal の伝搬は期待通りにはいきません。そのため Alibaba が公開している TransmittableThreadLocal というコンポーネントが解決策として提案されています。ここでは詳述を省きます。興味があれば調べてみてください。
ThreadLocal の実運用活用
ThreadLocal の使用シーン
私たちは現在のプロジェクトでログの記録に ELK+Logstash を利用し、最終的には Kibana で表示・検索を行っています。
分散システムが外部へサービスを提供する現状、プロジェクト間の呼び出し関係を traceId で結び付けることができます。しかし、異なるプロジェクト間で traceId をどう伝えるかが課題です。
ここでは org.slf4j.MDC を用いてこの機能を実現します。内部的には ThreadLocal によって実現されます。具体的な実装は以下のとおりです:
端末からサービス A へリクエストを送ると、サービス A は traceId という UUID 風の文字列を生成し、現在のスレッドの ThreadLocal にこの文字列を格納します。サービス B へ依頼する際には、traceId をリクエストのヘッダに書き込み、サービス B は受信時にヘッダに traceId があるかを判定し、存在すれば自分のスレッドの ThreadLocal に書き込みます。
requestId は各システムのチェーンを関連付けるキーです。システム間の呼び出しはこの requestId によって対応するチェーンを辿ることができます。その他にもいくつかのシーンがあります。
これらのシーンに対して、以下のような解決策があります。
Feign リモート呼び出しの解決策
サービスがリクエストを送る場合:
@Component@Slf4jpublic class FeignInvokeInterceptor implements RequestInterceptor {
@Override public void apply(RequestTemplate template) { String requestId = MDC.get("requestId"); if (StringUtils.isNotBlank(requestId)) { template.header("requestId", requestId); } }}サービスがリクエストを受け取る場合:
@Slf4j@Componentpublic class LogInterceptor extends HandlerInterceptorAdapter {
@Override public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) { MDC.remove("requestId"); }
@Override public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) { }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY); if (StringUtils.isBlank(requestId)) { requestId = UUID.randomUUID().toString().replace("-", ""); } MDC.put("requestId", requestId); return true; }}スレッドプールを用いた非同期呼び出しでの requestId の伝搬
MDC は ThreadLocal に基づいています。そのため、非同期処理の子スレッドは親スレッドの ThreadLocal データを取得できません。そこで、カスタムのスレッドプール実行器を用意し、run() メソッドを次のように変更します。
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
@Override public void execute(Runnable runnable) { Map<String, String> context = MDC.getCopyOfContextMap(); super.execute(() -> run(runnable, context)); }
@Override private void run(Runnable runnable, Map<String, String> context) { if (context != null) { MDC.setContextMap(context); } try { runnable.run(); } finally { MDC.remove(); } }}MQ を用いて第三者システムへメッセージを送る
MQ で送信するメッセージ体にカスタム属性 requestId を含めておき、受信側でそれを解析して使用します。
部分信息可能已经过时