


















pandas
pandasの紹介
Pandas は、Python プログラミング言語をベースにしたオープンソースのデータ分析・データ処理ライブラリです。
Pandas は、使いやすいデータ構造とデータ分析ツールを提供し、特に表形式データ(Excel の表に似たデータなど)の処理に適しています。
Pandas はデータサイエンスおよび分析分野で広く使われているツールの一つで、さまざまなデータソースからデータを容易に取り込み、データを効率的に操作・分析できるようにします。
Pandas は主に2つの新しいデータ構造を導入しました:DataFrame と Series
- Series: 一次元配列またはリストと似ており、一組のデータとそれに関連するデータラベル(インデックス)で構成されます。Series は DataFrame の列のようにも、単独の1次元データ構造としても扱えます。
- DataFrame: 二次元の表のようなもので、Pandas の中で最も重要なデータ構造です。DataFrame は複数の Series を列方向に並べてできた表で、行インデックスと列インデックスの両方を持つため、行と列の選択、フィルタ、結合などを容易に行えます。
Pandas は豊富な機能を提供します。以下を含みます:
- データクリーニング:欠損データ、重複データなどの処理。
- データ変換:データの形状・構造・形式を変更。
- データ分析:統計分析、集計、グルーピングなど。
- データの可視化:Matplotlib や Seaborn などのライブラリと統合してデータの可視化を行うことができます。
pandasのインストール
-
Pythonのインストール
公式サイトからダウンロード/ Docker でのインストール
-
pandasのインストール
pip install pandas動作確認:
2024-01-02 22:26:35の出力(例)
import pandas as pdpd.__version__pandas series
構造
- インデックス: 各 Series にはインデックスがあり、整数・文字列・日付などの型になり得ます。明示的にインデックスを指定しない場合、Pandasはデフォルトの整数インデックスを自動作成します。
- データ型: Series は異なるデータ型の要素を格納できます。整数、浮動小数点数、文字列など。
pandas.Series( data, index, dtype, name, copy)
## data:一組のデータ(ndarray 型)。## index:データのインデックスラベル。指定しなければ 0 から始まるデフォルト。## dtype:データ型。デフォルトは自動判定。## name:名前を設定。## copy:データをコピー。デフォルトは False。実例
-
Series の使用
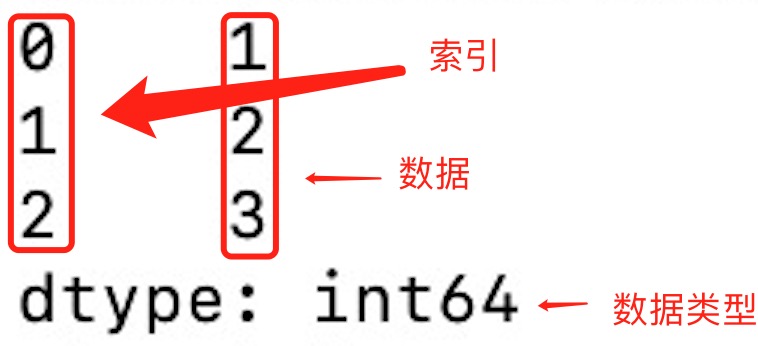
import pandas as pda = [1, 2, 3]myvar = pd.Series(a)print(myvar)print(myvar[1])出力は:
-
pd.Series でインデックスを設定
import pandas as pda = ["Google", "Runoob", "Wiki"]myvar = pd.Series(a, index = ["x", "y", "z"])print(myvar)print(myvar["y"]) -
辞書から作成
import pandas as pdsites = {1: "Google", 2: "Runoob", 3: "Wiki"}myvar = pd.Series(sites)print(myvar)myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )print(myvar)myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )print(myvar)
基本操作
-
基本操作
## 値の取得value = series[2] ## インデックスが 2 の値を取得## 複数の値を取得subset = series[1:4] ## インデックスが 1 から 3 の値を取得## カスタムインデックスを使用value = series_with_index['b'] ## インデックスが 'b' の値を取得## インデックスと値の対応関係for index, value in series_with_index.items():print(f"Index: {index}, Value: {value}") -
基本運算
## 算術運算result = series * 2 ## 全要素を 2 倍## フィルタリングfiltered_series = series[series > 2] ## 2 より大きい要素を選択## 数学関数import numpy as npresult = np.sqrt(series) ## 各要素の平方根を取る -
属性とメソッド
## インデックスの取得index = series_with_index.index## 値配列の取得values = series_with_index.values## 記述統計情報の取得stats = series_with_index.describe()## 最大値・最小値のインデックス取得max_index = series_with_index.idxmax()min_index = series_with_index.idxmin() -
注意事項
- Series のデータは有序です。
- Series はインデックス付きの1次元配列と見なすことができます。
- インデックスは一意である必要はありません。
- データはスカラー、リスト、NumPy配列などで構いません。
pandas dataframe
dataframe構造
- 列と行: DataFrame は複数の列で構成され、それぞれの列には名前があり、1つの Series として見ることができます。同時に、DataFrame には行インデックスがあり、各行を識別します。
- 二次元構造: DataFrame は行と列を持つ二次元の表で、複数の Series オブジェクトからなる辞書のように見ることもできます。
- 列のデータ型: 異なる列は異なるデータ型を含むことができます。例えば整数、浮動小数、文字列など。
pandas.DataFrame( data, index, columns, dtype, copy)
# data:一組のデータ(ndarray、series、map、lists、dict 型)。# index:インデックス値、行ラベルとも呼ばれます# columns:列ラベル、デフォルトは RangeIndex (0, 1, 2, …, n)# dtype:データ型、デフォルトは自動判定。# copy:データをコピー、デフォルトは False。dataframeの実例
-
DataFrame の使用
import pandas as pddata = [['Google',10],['Runoob',12],['Wiki',13]]df = pd.DataFrame(data,columns=['Site','Age'])print(df) -
ndarrays で作成
import pandas as pddata = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}df = pd.DataFrame(data)print (df) -
辞書リストから作成
import pandas as pddata = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]df = pd.DataFrame(data)print (df)対応するデータがない部分は NaN。
-
loc を使って指定行を返す Pandas は loc 属性を用いて指定した行のデータを返します。インデックスが設定されていない場合、最初の行のインデックスは 0、次の行は 1、以下同様です。
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]}# DataFrame へデータを読み込むdf = pd.DataFrame(data)# 第1行を返すprint(df.loc[0])# 第2行を返すprint(df.loc[1])# 第1行と第2行を返すprint(df.loc[[0, 1]])# 指定インデックスprint(df.loc["duration"]) -
pd.DataFrame でインデックスを指定
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]}df = pd.DataFrame(data, index = ["day1", "day2", "day3"])print(df)
dataframeの基本操作
-
基本操作
# 列の取得name_column = df['Name']# 行の取得first_row = df.loc[0]# 複数列の選択subset = df[['Name', 'Age']]# 行のフィルタfiltered_rows = df[df['Age'] > 30] -
データ操作
# 新しい列の追加df['Salary'] = [50000, 60000, 70000]# 列の削除df.drop('City', axis=1, inplace=True)# ソートdf.sort_values(by='Age', ascending=False, inplace=True)# 列名の変更df.rename(columns={'Name': 'Full Name'}, inplace=True) -
属性とメソッド
# 列名の取得columns = df.columns# 形状の取得(行数と列数)shape = df.shape# インデックスの取得index = df.index# 記述統計情報の取得stats = df.describe() -
外部データ源からの作成
# CSV ファイルから DataFrame を作成df_csv = pd.read_csv('example.csv')# Excel ファイルから DataFrame を作成df_excel = pd.read_excel('example.xlsx')# 辞書リストから DataFrame を作成data_list = [{'Name': 'Alice', 'Age': 25}, {'Name': 'Bob', 'Age': 30}]df_from_list = pd.DataFrame(data_list) -
注意事項
- DataFrame は柔軟なデータ構造で、異なるデータ型の列を格納できます。
- 列名と行インデックスは文字列、整数などを含むことがあります。
- DataFrame はデータの選択、フィルタ、修正、分析を多様な方法で行えます。
- DataFrame の操作を通じて、データのクリーニング、変換、分析、可視化などを行うことができます。
pandas CSV
紹介
CSV(Comma-Separated Values、カンマ区切り値、時には文字区切り値とも呼ばれる。区切り文字が必ずしもカンマとは限らない)、ファイルはプレーンテキスト形式で表形式データ(数字とテキスト)を保存します。
CSV は一般的で比較的シンプルなファイル形式で、ユーザー・ビジネス・科学の分野で広く利用されています。
-
CSV の処理 Pandas は CSV ファイルの処理を非常に容易に行えます
import pandas as pddf = pd.read_csv('site.csv')print(df.to_string()) -
CSV の保存 DataFrame を CSV ファイルとして保存するには to_csv() を使用します
import pandas as pd# 三つのフィールド name, site, agenme = ["Google", "Runoob", "Taobao", "Wiki"]st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]ag = [90, 40, 80, 98]# 辞書dict = {'name': nme, 'site': st, 'age': ag}df = pd.DataFrame(dict)# DataFrame の保存df.to_csv('site.csv')
データ処理
head()
head(n) メソッドは先頭の n 行を読み取ります。引数 n を指定しない場合はデフォルトで 5 行を返します。
import pandas as pd
df = pd.read_csv('nba.csv')print(df.head())
print(df.head(10))tail()
tail(n) メソッドは末尾の n 行を読み取ります。引数を指定しない場合はデフォルトで 5 行を返します。空行の各フィールドの値は NaN となります。
import pandas as pd
df = pd.read_csv('nba.csv')print(df.tail())
print(df.tail(10))info()
info() メソッドは表の基本情報を返します:
import pandas as pd
df = pd.read_csv('nba.csv')print(df.info())Pandas JSON
JSON(JavaScript Object Notation、JavaScript のオブジェクト表記法)は、テキスト情報を保存・交換するための文法で、XMLに似ています。
JSON は XML より小さく、高速で、解析が容易です。JSON に関する詳細は JSON チュートリアルを参照してください。
Pandas は JSON データの処理を非常に簡単に行えます。
普通JSON処理
import pandas as pd
df = pd.read_json('sites.json')print(df.to_string())
URL = '<https://static.runoob.com/download/sites.json>'df = pd.read_json(URL)print(df)JSON オブジェクトは Python の辞書と同じフォーマットを持つため、Python の辞書をそのまま DataFrame データに変換できます。
内嵌JSON処理
ネストされたデータを完全に解析するには json_normalize() メソッドを使用します。
import pandas as pdimport json
# Python の JSON モジュールを使用してデータを読み込むwith open('nested_list.json','r') as f: data = json.loads(f.read())
# データをフラット化df_nested_list = pd.json_normalize(data, record_path =['students'])print(df_nested_list)より複雑なデータ
import pandas as pdimport json
# Python の JSON モジュールを使用してデータを読み込むwith open('nested_mix.json','r') as f: data = json.loads(f.read())
df = pd.json_normalize( data, record_path =['students'], meta=[ 'class', ['info', 'president'], ['info', 'contacts', 'tel'] ])
print(df)ネストされたJSONの一部データを読む
glom モジュールを使用してデータのネストを扱います。glom モジュールを使って、’.’ を使ってネストされたオブジェクトの属性にアクセスします。
-
glom のインストール
pip3 install glom -
使用方法
import pandas as pdfrom glom import glomdf = pd.read_json('nested_deep.json')data = df['students'].apply(lambda row: glom(row, 'grade.math'))print(data)
データのクリーニング
欠損値のクリーニング
欠損値を含む行を削除したい場合、dropna() メソッドを使用します。書式は以下のとおりです:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# axis:デフォルトは 0。NA を含む行を削除。axis=1 を設定するとNAを含む列を削除します。# how:デフォルトは 'any'。行(または列)に NA が1つでも含まれていればその行を削除。how='all' の場合、行(または列)がすべて NA のときのみ削除します。# thresh:残すべき非空値の最小数を設定します。# subset:チェックしたい列を設定します。複数列の場合、列名のリストを引数として使用します。# inplace:True に設定すると、計算結果を元のデータに直接上書きして、None を返します。元データを変更します。isnull() を使って、各セルが空かどうかを判定できます。
pandas.read_csv で na_values を指定して、空値を指定することができます
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df['NUM_BEDROOMS'])print(df['NUM_BEDROOMS'].isnull())
# 空データを指定missing_values = ["n/a", "na", "--"]df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])print (df['NUM_BEDROOMS'].isnull())
# 空データを削除new_df = df.dropna()print(new_df.to_string())
# 元の DataFrame を上書きdf.dropna(inplace = True)print(df.to_string())
# 特定の空値を含む行を削除df.dropna(subset=['ST_NUM'], inplace = True)print(df.to_string())fillna() を使って空値を置換します
空セルを置換する一般的な方法は、列の平均値・中央値・最頻値を計算することです。
Pandas は mean()、median()、mode() メソッドを使用して、列の平均値(全値の総和を割った値)、中央値、および最頻値(出現頻度が最も高い値)を計算します。
import pandas as pd
df = pd.read_csv('property-data.csv')
# 空のフィールドを 12345 で置換df.fillna(12345, inplace = True)print(df.to_string())
# 平均値で空値を置換x = df["ST_NUM"].mean()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())
# 中央値で空値を置換x = df["ST_NUM"].median()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())
# 最頻値で空値を置換x = df["ST_NUM"].mode()df["ST_NUM"].fillna(x, inplace = True)print(df.to_string())フォーマットエラーのクリーニング
データ形式が正しくないセルは、データ分析を難しくし、場合によっては不可能にします。
ネストされたセルを含む行、または列内のすべてのセルを同じ形式のデータに変換することで対応できます。
import pandas as pd
# 3番目の日付形式が間違っていますdata = { "Date": ['2020/12/01', '2020/12/02' , '20201226'], "duration": [50, 40, 45]}df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 新しい Python 3 では、下の行はエラーになり、format='mixed' を明示して混合形式を許可する必要があります# pd.to_datetime(df['Date'])df['Date'] = pd.to_datetime(df['Date'], format='mixed')print(df.to_string())astype でデータ形式を変更する
data['語文'].dropna(how='any').astype('int')エラーデータのクリーニング
import pandas as pd
person = { "name": ['Google', 'Runoob' , 'Taobao'], "age": [50, 200, 12345]}
df = pd.DataFrame(person)
# データを直接変更df.loc[2, 'age'] = 30
# ループで判定for x in df.index: if df.loc[x, "age"] > 120: df.loc[x, "age"] = 120
# 行を削除for x in df.index: if df.loc[x, "age"] > 120: df.drop(x, inplace = True)
print(df.to_string())重複データのクリーニング
もし重複データをクリーニングする場合、duplicated() と drop_duplicates() メソッドを使います。
対応するデータが重複している場合、duplicated() は True を返し、そうでなければ False を返します。
import pandas as pd
person = { "name": ['Google', 'Runoob', 'Runoob', 'Taobao'], "age": [50, 40, 40, 23]}df = pd.DataFrame(person)
# 重複データの検索print(df.duplicated())
# 重複データの削除df.drop_duplicates(inplace = True)print(df)この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります