


















numpy
はじめに
NumPy(Numerical Python) は Python 言語の拡張ライブラリで、多数の次元配列と行列演算をサポートします。さらに、配列演算のための数学関数ライブラリも多数提供します。
NumPy は非常に高速な数学ライブラリで、主に配列計算に用いられ、以下を含みます:
- 強力なN次元配列オブジェクト ndarray
- ブロードキャスト機能関数
- C/C++/Fortran コードを統合するツール
- 線形代数、フーリエ変換、乱数生成などの機能
アプリケーション
NumPy は通常 SciPy(Scientific Python)と Matplotlib(描画ライブラリ)と一緒に使用されます。
この組み合わせは MatLab の代替として広く用いられる強力な科学計算環境で、Python を通じてデータサイエンスや機械学習を学ぶのに役立ちます。
SciPy はオープンソースの Python アルゴリズムライブラリと数学ツールキットです。
SciPy に含まれるモジュールとして、最適化、線形代数、積分、補間、特殊関数、高速フーリエ変換、信号処理と画像処理、常微分方程式の解法など、科学と工学でよく使われる計算があります。
Matplotlib は Python プログラミング言語と NumPy の数値数学拡張パックの可視化操作インターフェースです。
それは Tkinter、wxPython、Qt、GTK+ などの一般的な GUI ツールキットを用いて、アプリケーションに組み込み型の描画を提供する API を提供します。
インストール
- 配布版のインストール
- pip によるインストール
pip3 install numpy scipy matplotlib
インストールの検証
from numpy import *eye(4)Numpyデータ
Numpy Ndarrayオブジェクト
NumPy の最も重要な特徴の一つは N 次元配列オブジェクト ndarray で、同じ型のデータの集合であり、0 番目のインデックスから要素を参照します。
ndarray オブジェクトは同一型要素を格納する多次元配列です。
ndarray の各要素はメモリ内で同じサイズの領域を占めます。
ndarray は以下の構成要素から成ります:
- データを指すポインタ(メモリまたはメモリマッピングファイル内の一部のデータ)
- データ型(dtype)、配列内の固定サイズ値を表します
- 配列の形状(shape)を表すタプル、各次元の大きさを表します
- ストライド(stride)を表すタプルで、現在の次元の次の要素へ進むために跨ぐバイト数を表します
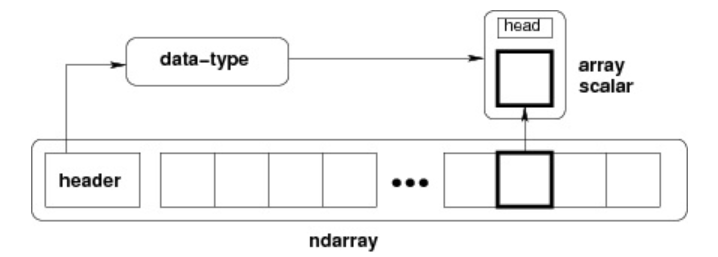
ndarray オブジェクトはメモリの連続した1次元部分で構成され、インデックスの方法と組み合わせて、各要素をメモリブロックの1つの位置にマッピングします。メモリブロックは行優先(C順)または列優先(Fortran/MatLab 風、F順)で要素を格納します。
Ndarrayの作成
ndarray を作成するには NumPy の array 関数を呼ぶだけです:
numpy.array(object,dtype = None,copy = True,order = None,subok = False,ndmin = 0)
# object:配列またはネストされた数列# dtype:配列要素のデータ型、オプション# copy: オブジェクトをコピーするかどうか、オプション# order: 配列の作成順序、Cは行方向、Fは列方向、Aは任意(デフォルト)# subok: デフォルトで基底クラスと同一の配列を返す# ndmin: 生成される配列の最小次元数例
import numpy as npa = np.array([1,2,3])print (a)
a = np.array([[1, 2], [3, 4]])print (a)
# 最小次元a = np.array([1, 2, 3, 4, 5], ndmin = 2)print (a)
# dtype パラメータa = np.array([1, 2, 3], dtype = complex)print (a)データ型
NumPy がサポートするデータ型は Python の組み込み型よりもはるかに多く、基本的には C 言語のデータ型と対応します。そのうちの一部の型は Python の組み込み型に対応します。
bool,int,intc,intp,int8,int16,int32,int64,uint8,uint16,uint32,uint64,float,float16,float32,float64,complex_,complex128,complex64,complex128
データ型オブジェクト(numpy.dtype クラスのインスタンス)は、配列に対応するメモリ領域がどのように使われるかを説明します。以下の点を説明します:
- データの型(整数、浮動小数点数、あるいは Python オブジェクト)
- データのサイズ(例:整数は何バイトで格納されるか)
- データのバイト順序(リトルエンディアンかビッグエンディアン)
- 構造化型の場合、フィールドの名前、各フィールドのデータ型、各フィールドが占めるメモリブロックの部分
- データ型がサブ配列の場合、その形状とデータ型
バイト順序は、データ型を予め設定する < または > によって決まります。 < はリトルエンディアン(最小値が最小アドレスに格納され、低位のバイトが先頭)を意味します。> はビッグエンディアン(最も重要なバイトが最小アドレスに格納され、最高位のバイトが先頭)を意味します。
dtype オブジェクトは以下の構文で作成します:
numpy.dtype(object, align, copy)
# object - 変換するデータ型オブジェクト# align - true の場合、フィールドを C の構造体風にパディングします。# copy - dtype オブジェクトをコピー。false の場合、組み込みデータ型オブジェクトへの参照になります。使用例:
import numpy as np# スカラー型を使用dt = np.dtype(np.int32)print(dt)
# まず構造化データ型を作成dt = np.dtype([('age',np.int8)])# ndarray にデータ型を適用a = np.array([(10,),(20,),(30,)], dtype = dt)print(a)各組み込み型には、それを一意に定義する文字コードがあり、以下のとおりです:
| 文字 | 対応する型 |
|---|---|
| b | ブール型 |
| i | (符号付き) 整数型 |
| u | 符号なし整数型 |
| f | 浮動小数点型 |
| c | 複素浮動小数点型 |
| m | timedelta(時間間隔) |
| M | datetime(日時) |
| O | (Python) オブジェクト |
| S, a | (バイト列)文字列 |
| U | Unicode |
| V | 生データ(void) |
Numpy配列
Numpy配列の属性
NumPy 配列の次元は「階数(rank)」と呼ばれ、軸の数、すなわち配列の次元を表します。1 次元配列の階数は 1、2 次元は 2、以下同様です。
NumPy では、配列の各軸を axis と呼び、これが次元(dimensions)を構成します。例えば、2 次元配列は 2 つの 1 次元配列から成り、それぞれの 1 次元配列の中にはさらに別の 1 次元配列が含まれます。
したがって、1 次元配列は NumPy の軸(axis)であり、最初の軸は下位の配列、次の軸はその中の配列を表します。軸の数、すなわち「秩」は配列の次元数です。
多くの場合、axis を宣言できます。axis=0 は第 0 軸に沿って操作することを意味し、列ごとに操作します。axis=1 は第 1 軸に沿って操作することを意味し、行ごとに操作します。
NumPy の配列で特に重要な ndarray オブジェクトの属性には次のものがあります:
-
ndarray.ndim 秩、軸の数または次元の数
import numpy as npa = np.arange(24)print (a.ndim) # a は現在1次元です# サイズを変更しますb = a.reshape(2,4,3) # b は3次元になりますprint (b.ndim) -
ndarray.shape 配列の次元、行列の場合は n 行 m 列
ndarray.shape も配列のサイズを調整するのに使用できます。
NumPy も reshape 関数を提供して、配列のサイズを調整します。
import numpy as npa = np.array([[1,2,3],[4,5,6]])print (a.shape)a.shape = (3,2)print (a)a = np.array([[1,2,3],[4,5,6]])b = a.reshape(3,2)print (b) -
ndarray.size 配列要素の総数、すなわち .shape の n*m に相当します
-
ndarray.dtype ndarray オブジェクトの要素型
-
ndarray.itemsize ndarray オブジェクトの各要素の大きさをバイト単位で
import numpy as np# 配列の dtype が int8(1 バイト)x = np.array([1,2,3,4,5], dtype = np.int8)print (x.itemsize)# 配列の dtype が float64(8 バイト)y = np.array([1,2,3,4,5], dtype = np.float64)print (y.itemsize) -
ndarray.flags ndarray オブジェクトのメモリ情報
属性 説明 C_CONTIGUOUS (C) データは単一の C 風の連続領域に格納されます F_CONTIGUOUS (F) データは単一の Fortran 風の連続領域に格納されます OWNDATA (O) 配列は使用するメモリを所有するか、他のオブジェクトから借用します WRITEABLE (W) データ領域は書き込み可能で、False に設定するとデータは読み取り専用 ALIGNED (A) データとすべての要素が適切にハードウェアに整列します UPDATEIFCOPY (U) この配列は他の配列のコピーであり、この配列が解放されると元配列の内容が更新されます import numpy as npx = np.array([1,2,3,4,5])print (x.flags) -
ndarray.real ndarray 要素の実部
-
ndarray.imag ndarray 要素の虚部
-
ndarray.data 実際の配列要素を含むバッファ。通常は配列のインデックスを介して要素を取得するため、この属性を使う機会はほとんどありません
Numpy配列の作成
ndarray 配列は基盤となる ndarray コンストラクタを使って作成するほか、以下の方法でも作成できます。
-
numpy.empty
numpy.empty は、指定した形状(shape)、データ型(dtype)を持ち、未初期化の配列を作成します:
numpy.empty(shape, dtype = float, order = 'C')# shape 配列の形状# dtype データ型、任意# order 'C' または 'F' の2つのオプション、要素をメモリ上に格納する順序を表します使用例:
import numpy as npx = np.empty([3,2], dtype = int)print (x) -
numpy.zeros
指定したサイズの配列を作成し、要素を 0 で埋めます:
numpy.zeros(shape, dtype = float, order = 'C')# shape 配列の形状# dtype データ型、任意# order 'C' は行優先、`'F'` は Fortran の列優先使用例:
import numpy as np# デフォルトは浮動小数点数x = np.zeros(5)print(x)# 整数型を設定y = np.zeros((5,), dtype = int)print(y)# 複数の型を指定z = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])print(z) -
numpy.ones
指定した形状の配列を作成し、要素を 1 で埋めます:
numpy.ones(shape, dtype = float, order = 'C')# shape 配列の形状# dtype データ型、任意# order 'C' は行優先、または 'F' は Fortran の列優先使用例:
import numpy as np# デフォルトは浮動小数点数x = np.ones(5)print(x)# 自定义类型x = np.ones([2,2], dtype = int)print(x) -
numpy.zeros_like/ones_like
numpy.zeros_like は、与えられた配列と同じ形状の配列を作成し、要素を 0 で埋めます。
numpy.zeros と numpy.zeros_like は、指定した形状の配列を作成し、全要素を 0 にします。
これらの違いは、numpy.zeros は作成する配列の形状を直接指定できるのに対し、numpy.zeros_like は与えられた配列と同じ形状の配列を作る点です。
numpy.zeros_like(a, dtype=None, order='K', subok=True, shape=None)# a 与えられた同形状の配列# dtype 作成する配列のデータ型# order メモリ上の格納順序、'C'(行優先)または 'F'(列優先)、デフォルトは 'K'(入力配列の格納順序を保持)# subok サブクラスの返却を許可するか、True の場合はサブクラスを返す、そうでなければ a 配列と同じデータ型と格納順序の配列を返します# shape 作成する配列の形状。指定しなければ a 配列と同じ形状になります。使用例:
import numpy as np# 3x3 の2次元配列を作成arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# arr と同じ形状の、全要素が 0 の配列を作成zeros_arr = np.zeros_like(arr)print(zeros_arr)
既存の配列から作成
-
numpy.asarray
numpy.asarray は numpy.array に似ていますが、引数は 3 つだけで、numpy.array より少なくなっています。
numpy.asarray(a, dtype = None, order = None)# パラメータの説明:# a 任意の形式の入力パラメータ。リスト、リストのタプル、タプル、タプルのタプル、タプルのリスト、多次元配列など# dtype データ型、任意# order 任意。'C' と 'F' の2つのオプションがあり、それぞれ行優先と列優先を表し、メモリ上のデータの格納順序を決定します。# 使用例:import numpy as np# リストx = [1,2,3]a = np.asarray(x)print (a)# タプルx = (1,2,3)a = np.asarray(x)print (a)# タプルのリストx = [(1,2,3),(4,5)]a = np.asarray(x)print (a)x = [1,2,3]a = np.asarray(x, dtype = float)print (a) -
numpy.frombuffer
numpy.frombuffer は動的配列を実現するために用いられます。
numpy.frombuffer は buffer 入力パラメータを受け取り、ストリームとして読み込んで ndarray オブジェクトへ変換します。
注意:buffer が文字列のとき、Python3 ではデフォルトで str は Unicode 型のため、元の str の前に b を付けて bytestring に変換します。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)# パラメータの説明:# buffer 任意のオブジェクトで、ストリームとして読み込まれます。# dtype 返される配列のデータ型、任意# count 読み込むデータ数、デフォルトは -1、すべて読み込みます# offset 読み取り開始位置、デフォルトは0。# 使用例:import numpy as nps = b'Hello World'a = np.frombuffer(s, dtype = 'S1')print (a) -
numpy.fromiter
numpy.fromiter は反復可能オブジェクトから ndarray オブジェクトを生成し、一つの1次元配列を返します。
numpy.fromiter(iterable, dtype, count=-1)# パラメータの説明:# iterable 反復可能オブジェクト# dtype 戻り値のデータ型# count 読み込むデータ数、デフォルトは-1、すべて読み込み# 使用例:import numpy as np# range 関数を使ってリストを作成list=range(5)it=iter(list)# イテレータを用いて ndarray を作成x=np.fromiter(it, dtype=float)print(x)
から数値範囲の作成
-
numpy.arange
numpy パッケージには arange 関数を用いて数値範囲を作成し ndarray オブジェクトを返します。関数の形式は次のとおりです:
start と stop で指定された範囲と step で設定された歩幅に従って、ndarray を生成します。
numpy.arange(start, stop, step, dtype)# パラメータの説明:# start 起始値、デフォルトは0# stop 終了値(含まれない)# step 歩幅、デフォルトは1# dtype 戻り値の ndarray のデータ型、指定がなければ入力データの型を使用# 使用例:import numpy as npx = np.arange(5)print (x)# dtype を設定x = np.arange(5, dtype = float)print (x)# 起始値、終止値、步長を設定x = np.arange(10,20,2)print (x) -
numpy.linspace
numpy.linspace 関数は、等差数列からなる1次元配列を作成するためのものです。形式は以下のとおりです:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)# パラメータの説明:# start シリーズの開始値# stop シリーズの終了値。endpoint が true の場合、この値は数列に含まれます# num 生成する等間隔のサンプル数、デフォルトは50# endpoint true の場合 stop 値を数列に含めます。デフォルトは True。# retstep True の場合、生成された配列に間隔が表示されます。 False の場合は表示されません。# dtype ndarray のデータ型# 使用例:import numpy as npa = np.linspace(1,10,10)print(a)a = np.linspace(1,1,10)print(a)a = np.linspace(10, 20, 5, endpoint = False)print(a)a =np.linspace(1,10,10,retstep= True)print(a)b =np.linspace(1,10,10).reshape([10,1])print(b) -
numpy.logspace
numpy.logspace 関数は等比数列を作成します。形式は以下のとおりです:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)# パラメータの説明:# start 系列の開始値は base ** start# stop 系列の終了値は base ** stop。endpoint が true の場合、この値は数列に含まれます# num 生成する等歩長のサンプル数、デフォルトは50# endpoint true の場合、stop 値を数列に含めます、デフォルトは True。# base 対数の底数。# dtype ndarray のデータ型# 使用例:import numpy as np# デフォルトの底は 10a = np.logspace(1.0, 2.0, num = 10)print (a)a = np.logspace(0,9,10,base=2)print (a)
配列のスライスとインデックス
スライスとインデックス
ndarray オブジェクトの内容は、インデックスまたはスライスを介してアクセス・変更できます。これは Python の list のスライス操作と同様です。
ndarray 配列は 0 から n の下標でインデックス可能で、スライスオブジェクトは組み込みの slice 関数を用いて start, stop 及び step を設定し、元の配列から新しい配列を切り出します。
コロン : の説明:1つのパラメータだけ置くと、そのインデックスに対応する単一要素を返します。
[2:] は、そのインデックス以降のすべての項目を抽出します。 [2:7] のように2つのパラメータを使うと、開始インデックスから停止インデックスを含まない範囲の項目を抽出します。スライスには省略記号 … も含められ、選択するタプルの長さを配列の次元と揃えることができます。 行位置で省略記号を使うと、行を含む ndarray が返されます。
import numpy as np
a = np.arange(10)s = slice(2,7,2) # インデックス 2 から 7 まで、間隔は 2print (a[s])
# あるいはコロンでスライスパラメータ start:stop:step を用いてスライス操作をすることもできますa = np.arange(10)b = a[2:7:2] # インデックス 2 から 7 まで、間隔は 2print(b)
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]b = a[5]print(b)
print(a[2:])
print(a[2:5])
# 多次元a = np.array([[1,2,3],[3,4,5],[4,5,6]])print(a)# あるインデックスから切り取るprint('配列インデックス a[1:] から切り取る')print(a[1:])
# 省略符号a = np.array([[1,2,3],[3,4,5],[4,5,6]])print (a[...,1]) # 第2列の要素print (a[1,...]) # 第2行の要素print (a[...,1:]) # 第2列およびそれ以降の要素高度なインデックス
NumPy は一般的な Python のシーケンスよりも多くのインデックス方法を提供します。
以前に見た整数とスライスによるインデックス以外にも、整数配列インデックス、ブールインデックス、ファンシーインデックスを用いて配列の要素にアクセスできます。
NumPy の高度なインデックスは、整数配列、ブール配列、または他のシーケンスを用いて配列の要素にアクセスすることを指します。基本的なインデックスと比べて、高度なインデックスは配列内の任意の要素にアクセスでき、配列に対する複雑な操作や変更を行うことができます。
整数配列インデックス
整数配列インデックスとは、別の配列の要素へアクセスするために1つの配列を用いることを指します。この配列の各要素は、ターゲット配列のある次元上のインデックス値です。
import numpy as np
# 配列の (0,0)、(1,1) および (2,0) の位置の要素を取得x = np.array([[1, 2], [3, 4], [5, 6]])y = x[[0,1,2], [0,1,0]]print (y)
# 4x3 配列の四隅の要素を取得。 行インデックスは [0,0] と [3,3]、列インデックスは [0,2] と [0,2]x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])print ('Our array is:' )print (x)print ('\\n')rows = np.array([[0,0],[3,3]])cols = np.array([[0,2],[0,2]])y = x[rows,cols]print ('この配列の四隅の要素は:')print (y)
# スライス : または … とインデックス配列を組み合わせるa = np.array([[1,2,3], [4,5,6],[7,8,9]])b = a[1:3, 1:3]c = a[1:3,[1,2]]d = a[...,1:]print(b)print(c)print(d)ブールインデックス
ブール配列を用いてターゲット配列をインデックスできます。
ブールインデックスはブール演算(比較演算子など)により、指定条件を満たす要素の配列を取得します。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])print ('Our array is:')print (x)print ('\\n')# 現在、5より大きい要素を出力しますprint ('大きい要素は:')print (x[x > 5])
a = np.array([np.nan, 1,2,np.nan,3,4,5])print (a[~np.isnan(a)])
a = np.array([1, 2+6j, 5, 3.5+5j])print (a[np.iscomplex(a)])ファンシーインデックス
ファンシーインデックスは、整数配列を用いてインデックスすることを指します。
ファンシーインデックスは、インデックス配列の値を対象配列のある軸の下標として用い、値を取り出します。
1次元の整数配列をインデックスとして用いる場合、対象が1次元配列ならインデックス結果は対応する位置の要素、対象が2次元配列なら対応する行になります。
ファンシーインデックスはスライスとは異なり、データを新しい配列へ常にコピーします。
-
1次元配列
1次元配列には軸が1つしかないため、 axis = 0 の軸で値を取ります:
import numpy as npx = np.arange(9,0,-1)print(x)print(x[[0,2]]) -
2次元配列
2次元配列には軸が2つあるため、 axis=0 で値を取ります:
import numpy as npx=np.arange(32).reshape((8,4))print(x)# 二次元配列の指定インデックスの行を読み取るprint("-------読み取る行-------")print (x[[4,2,1,7]])px=np.arange(32).reshape((8,4))print (x[[-4,-2,-1,-7]]) -
複数のインデックス配列の入力
np.ix_ 関数は2つの配列を入力として受け、デカルト積のマッピングを生成します。
import numpy as npx=np.arange(32).reshape((8,4))print (x[np.ix_([1,5,7,2],[0,3,1,2])])
ブロードキャスト
ブロードキャストは numpy が異なる形状(shape) の配列同士で数値計算を行う方法で、配列の算術演算は通常、対応する要素上で行われます。
もし2つの配列 a と b の形状が同じであれば、a*b の結果は a と b の対応する要素の積になります。これは次元数が同じで、各次元の長さが同じことを要求します。
計算中の2つの配列の形状が異なる場合、NumPy は自動的にブロードキャスト機構を発動します。4x3 の2次元配列と長さ 3 の1次元配列を加算する場合、配列 b を2次元方向に 4 回繰り返してから演算するのと同等です:
import numpy as numpy
a = np.array([[ 0, 0, 0], [10,10,10], [20,20,20], [30,30,30]])b = np.array([0,1,2])print(a + b)
bb = np.tile(b, (4, 1)) # b の各次元を繰り返すprint(a + bb)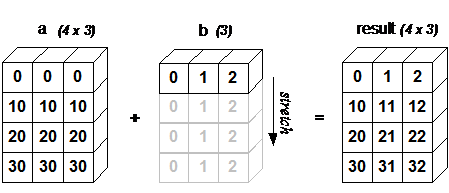
ブロードキャストのルール:
- すべての入力配列を、形状が最も長い配列に合わせ、足りない部分は前に 1 を追加して埋める。
- 出力配列の形状は、入力配列の各次元の最大値になる。
- 入力配列のある次元の長さが、出力配列の対応する次元の長さと同じ、または長さが 1 のとき、その配列を計算に用いることができる。そうでない場合はエラーになる。
- 入力配列のある次元の長さが 1 の場合、その次元に沿って演算する時はこの次元の最初の値を用いる。
条件を満たさない場合、“ValueError: frames are not aligned” 例外が発生します。
配列操作
配列の反復
NumPy のイテレータオブジェクト numpy.nditer は、1つまたは複数の配列要素へ柔軟にアクセスする方法を提供します。
イテレータの最も基本的な役割は、配列要素へのアクセスを実現することです。
import numpy as np
a = np.arange(6).reshape(2,3)print ('原始数组は:')print (a,'\\n')print ('反復で要素を出力します:')for x in np.nditer(a): print (x, end=", " )print ('\\n')
for x in np.nditer(a.T): print (x, end=", " )print ('\\n')
for x in np.nditer(a.T.copy(order='C')): print (x, end=", " )print ('\\n')上述の例から、a と a.T の走査順序は同じで、メモリ上の格納順序も同じですが、a.T.copy(order = ‘C’) の走査結果は異なります。nditer はデフォルトで K 順序、つまり配列要素がメモリ上に表示されるデータにできるだけ近づくように走査します。
走査順序の制御
- for x in np.nditer(a, order=‘F’): Fortran order、すなわち列優先;
- for x in np.nditer(a.T, order=‘C’): C order、すなわち行優先;
import numpy as np
a = np.arange(0,60,5)a = a.reshape(3,4)print ('原始数组は:')print (a)print ('\\n')print ('原始配列の転置は:')b = a.Tprint (b)print ('\\n')print ('C 風順序でソート:')c = b.copy(order='C')print (c)for x in np.nditer(c): print (x, end=", " )print ('\\n')print ('F 風順序でソート:')c = b.copy(order='F')print (c)for x in np.nditer(c): print (x, end=", " )print ('\\n')# 明示的に設定して nditer が特定の順序を使用するよう強制することもできます:print ('C 風順序でソート:')for x in np.nditer(a, order = 'C'): print (x, end=", " )print ('\\n')print ('F 風順序でソート:')for x in np.nditer(a, order = 'F'): print (x, end=", " )配列要素の変更
nditer オブジェクトには another optional parameter op_flags があります。デフォルトでは、nditer は反復対象の配列を読み取り専用とみなします。配列の要素値を変更できるようにするには、readwrite または writeonly のモードを指定する必要があります。
import numpy as np
a = np.arange(0,60,5)a = a.reshape(3,4)print ('原始数组は:')print (a)print ('\\n')for x in np.nditer(a, op_flags=['readwrite']): x[...]=2*xprint ('変更後の配列は:')print (a)外部ループの使用
nditer クラスのコンストラクタには flags パラメータがあり、以下の値を受け付けます:
| パラメータ | 説明 |
|---|---|
| c_index | C 順序のインデックスを追跡できる |
| f_index | Fortran 順序のインデックスを追跡できる |
| multi_index | 各反復で1つのインデックス型を追跡 |
| external_loop | 出力の値は複数の値を持つ1次元配列で、スカラー値ではない |
import numpy as npa = np.arange(0,60,5)a = a.reshape(3,4)print ('原始数组は:')print (a)print ('\\n')print ('変更後の配列は:')for x in np.nditer(a, flags = ['external_loop'], order = 'F'): print (x, end=", " )ブロードキャスト反復
もし2つの配列がブロードキャスト可能であれば、nditer の組み合わせオブジェクトを同時に反復できます。例えば、配列 a の次元が 3x4、配列 b の次元が 1x4 の場合、以下のイテレータを使います(配列 b が a の大きさにブロードキャストされます)。
import numpy as np
a = np.arange(0,60,5)a = a.reshape(3,4)print ('第の配列は:')print (a)print ('\\n')print ('第2の配列は:')b = np.array([1, 2, 3, 4], dtype = int)print (b)print ('\\n')print ('変更後の配列は:')for x,y in np.nditer([a,b]): print ("%d:%d" % (x,y), end=", " )配列操作
形状の変更
| 関数 | 説明 | 関数 |
|---|---|---|
| reshape | データを変えずに形状を変更 | `numpy.reshape(arr, newshape, order=[‘C' |
| flat | 配列の要素イテレータ | 配列要素イテレータ(for e in a.flat:) |
| flatten | コピーを返し、コピー上の変更は元の配列に影響しない | `ndarray.flatten(order=[‘C' |
| ravel | 展開した配列を返す | `numpy.ravel(a, order=[‘C' |
配列の反転
| 関数 | 説明 | 関数 |
|---|---|---|
| transpose | 配列の次元を転置 | numpy.transpose(arr, axes) |
| ndarray.T | self.transpose() と同じ | 類似 numpy.transpose |
| rollaxis | 指定した軸を後ろへ転がす | numpy.rollaxis(arr, axis, start) |
| swapaxes | 配列の二つの軸を入れ替える | numpy.swapaxes(arr, axis1, axis2) |
次元の変更
| 関数 | 説明 | 関数 |
|---|---|---|
| broadcast | ブロードキャストを模倣するオブジェクトを作成 | この関数は2つの配列を入力として使用します |
| broadcast_to | 配列を新しい形状へブロードキャスト | numpy.broadcast_to(array, shape, subok) |
| expand_dims | 配列の形状を拡張 | numpy.expand_dims(arr, axis) |
| squeeze | 配列の形状から1次元の要素を削除 | numpy.squeeze(arr, axis) |
配列の結合
| 関数 | 説明 | 関数 |
|---|---|---|
| concatenate | 既存の軸に沿って配列列を結合 | numpy.concatenate((a1, a2, ...), axis) |
| stack | 新しい軸に沿って一連の配列を結合します。 | numpy.stack(arrays, axis) |
| hstack | 配列を水平方向に結合(列方向) | numpy.hstack(arrays) |
| vstack | 配列を垂直方向に結合(行方向) | numpy.vstack(arrays |
配列の分割
| 関数 | 説明 | 関数 |
|---|---|---|
| split | 配列を複数のサブ配列に分割します(左開右開) | numpy.split(ary, indices_or_sections, axis) |
| hsplit | 配列を水平方向に分割します(列方向) | numpy.hsplit(ary, indices_or_sections) |
| vsplit | 配列を垂直方向に分割します(行方向) | numpy.vsplit(ary, indices_or_sections) |
配列要素の追加と削除
| 関数 | 説明 | 関数 |
|---|---|---|
| resize | 指定形状の新しい配列を返す | numpy.resize(arr, shape) |
| append | 値を配列の末尾に追加 | numpy.append(arr, values, axis=None) |
| insert | 指定した軸に沿って、指定した位置の前に値を挿入 | numpy.insert(arr, obj, values, axis) |
| delete | ある軸のサブ配列を削除し、削除後の新しい配列を返す | numpy.delete(arr, obj, axis) |
| unique | 配列内の一意な要素を検索 | numpy.unique(arr, return_index, return_inverse, return_counts) |
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります