






















Scipy
介绍
SciPy 是一个开源的 Python 算法库和数学工具包。
Scipy 是基于 Numpy 的科学计算库,用于数学、科学、工程学等领域,很多有一些高阶抽象和物理模型需要使用 Scipy。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
应用
Scipy 是一个用于数学、科学、工程领域的常用软件包,可以处理最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解器等。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
NumPy 和 SciPy 的协同工作可以高效解决很多问题,在天文学、生物学、气象学和气候科学,以及材料科学等多个学科得到了广泛应用。
安装
python3 -m pip install -U pippython3 -m pip install -U scipy验证安装:
import scipy
print(scipy.__version__)模块列表
以下列出了 SciPy 常用的一些模块及官网 API 地址:
| 模块名 | 功能 | 参考文档 |
|---|---|---|
| scipy.cluster | 向量量化 | cluster API |
| scipy.constants | 数学常量 | constants API |
| scipy.fft | 快速傅里叶变换 | fft API |
| scipy.integrate | 积分 | integrate API |
| scipy.interpolate | 插值 | interpolate API |
| scipy.io | 数据输入输出 | io API |
| scipy.linalg | 线性代数 | linalg API |
| scipy.misc | 图像处理 | misc API |
| scipy.ndimage | N 维图像 | ndimage API |
| scipy.odr | 正交距离回归 | odr API |
| scipy.optimize | 优化算法 | optimize API |
| scipy.signal | 信号处理 | signal API |
| scipy.sparse | 稀疏矩阵 | sparse API |
| scipy.spatial | 空间数据结构和算法 | spatial API |
| scipy.special | 特殊数学函数 | special API |
| scipy.stats | 统计函数 | stats.mstats API |
更多模块内容可以参考官方文档:https://docs.scipy.org/doc/scipy/reference/
scipy常量模块
SciPy 常量模块 constants 提供了许多内置的数学常数。
圆周率是一个数学常数,为一个圆的周长和其直径的比率,近似值约等于 3.14159,常用符号 来表示。
以下输出圆周率:
from scipy import constants
print(constants.pi)以下输出黄金比例:
from scipy import constants
print(constants.golden)我们可以使用 dir() 函数来查看 constants 模块包含了哪些常量:
from scipy import constants
print(dir(constants))单位类型
常量模块包含以下几种单位:
-
公制单位 国际单位制词头(英语:SI prefix)表示单位的倍数和分数,目前有 20 个词头,大多数是千的整数次幂。 (centi 返回 0.01):
from scipy import constantsprint(constants.yotta) #1e+24print(constants.zetta) #1e+21print(constants.exa) #1e+18print(constants.peta) #1000000000000000.0print(constants.tera) #1000000000000.0print(constants.giga) #1000000000.0print(constants.mega) #1000000.0print(constants.kilo) #1000.0print(constants.hecto) #100.0print(constants.deka) #10.0print(constants.deci) #0.1print(constants.centi) #0.01print(constants.milli) #0.001print(constants.micro) #1e-06print(constants.nano) #1e-09print(constants.pico) #1e-12print(constants.femto) #1e-15print(constants.atto) #1e-18print(constants.zepto) #1e-21 -
二进制,以字节为单位 返回字节单位 (kibi 返回 1024)。
from scipy import constantsprint(constants.kibi) #1024print(constants.mebi) #1048576print(constants.gibi) #1073741824print(constants.tebi) #1099511627776print(constants.pebi) #1125899906842624print(constants.exbi) #1152921504606846976print(constants.zebi) #1180591620717411303424print(constants.yobi) #1208925819614629174706176 -
质量单位 返回多少千克 kg。(gram 返回 0.001)。
from scipy import constantsprint(constants.gram) #0.001print(constants.metric_ton) #1000.0print(constants.grain) #6.479891e-05print(constants.lb) #0.45359236999999997print(constants.pound) #0.45359236999999997print(constants.oz) #0.028349523124999998print(constants.ounce) #0.028349523124999998print(constants.stone) #6.3502931799999995print(constants.long_ton) #1016.0469088print(constants.short_ton) #907.1847399999999print(constants.troy_ounce) #0.031103476799999998print(constants.troy_pound) #0.37324172159999996print(constants.carat) #0.0002print(constants.atomic_mass) #1.66053904e-27print(constants.m_u) #1.66053904e-27print(constants.u) #1.66053904e-27 -
角度换算 返回弧度 (degree 返回 0.017453292519943295)。
from scipy import constantsprint(constants.degree) #0.017453292519943295print(constants.arcmin) #0.0002908882086657216print(constants.arcminute) #0.0002908882086657216print(constants.arcsec) #4.84813681109536e-06print(constants.arcsecond) #4.84813681109536e-06 -
时间单位 返回秒数(hour 返回 3600.0)。
from scipy import constantsprint(constants.minute) #60.0print(constants.hour) #3600.0print(constants.day) #86400.0print(constants.week) #604800.0print(constants.year) #31536000.0print(constants.Julian_year) #31557600.0 -
长度单位 返回米数(nautical_mile 返回 1852.0)。
from scipy import constantsprint(constants.inch) #0.0254print(constants.foot) #0.30479999999999996print(constants.yard) #0.9143999999999999print(constants.mile) #1609.3439999999998print(constants.mil) #2.5399999999999997e-05print(constants.pt) #0.00035277777777777776print(constants.point) #0.00035277777777777776print(constants.survey_foot) #0.3048006096012192print(constants.survey_mile) #1609.3472186944373print(constants.nautical_mile) #1852.0print(constants.fermi) #1e-15print(constants.angstrom) #1e-10print(constants.micron) #1e-06print(constants.au) #149597870691.0print(constants.astronomical_unit) #149597870691.0print(constants.light_year) #9460730472580800.0print(constants.parsec) #3.0856775813057292e+16 -
压强单位 返回多少帕斯卡,压力的 SI 制单位。(psi 返回 6894.757293168361)。
from scipy import constantsprint(constants.atm) #101325.0print(constants.atmosphere) #101325.0print(constants.bar) #100000.0print(constants.torr) #133.32236842105263print(constants.mmHg) #133.32236842105263print(constants.psi) #6894.757293168361 -
面积单位 返回多少平方米,平方米是面积的公制单位,其定义是:在一平面上,边长为一米的正方形之面积。(hectare 返回 10000.0)。
from scipy import constantsprint(constants.hectare) #10000.0print(constants.acre) #4046.8564223999992 -
体积单位
返回多少立方米,立方米容量计量单位,1 立方米的容量相当于一个长、宽、高都等于 1 米的立方体的体积,与 1 公秉和 1 度水的容积相等,也与1000000立方厘米的体积相等。(liter返回0.001)。
from scipy import constantsprint(constants.liter) #0.001print(constants.litre) #0.001print(constants.gallon) #0.0037854117839999997print(constants.gallon_US) #0.0037854117839999997print(constants.gallon_imp) #0.00454609print(constants.fluid_ounce) #2.9573529562499998e-05print(constants.fluid_ounce_US) #2.9573529562499998e-05print(constants.fluid_ounce_imp) #2.84130625e-05print(constants.barrel) #0.15898729492799998print(constants.bbl) #0.15898729492799998 -
速度单位 返回每秒多少米。(speed_of_sound 返回 340.5)。
from scipy import constantsprint(constants.kmh) #0.2777777777777778print(constants.mph) #0.44703999999999994print(constants.mach) #340.5print(constants.speed_of_sound) #340.5print(constants.knot) #0.5144444444444445 -
温度单位 返回多少开尔文。(zero_Celsius 返回 273.15)。
from scipy import constantsprint(constants.zero_Celsius) #273.15print(constants.degree_Fahrenheit) #0.5555555555555556 -
能量单位 返回多少焦耳,焦耳(简称焦)是国际单位制中能量、功或热量的导出单位,符号为J。(calorie 返回 4.184)。
from scipy import constantsprint(constants.calorie) #4.184 -
功率单位 返回多少瓦特,瓦特(符号:W)是国际单位制的功率单位。1瓦特的定义是1焦耳/秒(1 J/s),即每秒钟转换,使用或耗散的(以安培为量度的)能量的速率。(horsepower返回745.6998715822701)。
from scipy import constantsprint(constants.hp) #745.6998715822701print(constants.horsepower) #745.6998715822701 -
力学单位 返回多少牛顿,牛顿(符号为N,英语:Newton)是一种物理量纲,是力的公制单位。它是以建立经典力学(经典力学)的艾萨克·牛顿命名。。(kilogram_force返回9.80665)。
from scipy import constantsprint(constants.dyn) #1e-05print(constants.dyne) #1e-05print(constants.lbf) #4.4482216152605print(constants.pound_force) #4.4482216152605print(constants.kgf) #9.80665print(constants.kilogram_force) #9.80665
Scipy优化器
SciPy 的 optimize 模块提供了常用的最优化算法函数实现,我们可以直接调用这些函数完成我们的优化问题,比如查找函数的最小值或方程的根等。
求方程的根
NumPy 能够找到多项式和线性方程的根,但它无法找到非线性方程的根,如下所示:
x + cos(x)
因此我们可以使用 SciPy 的 optimze.root 函数,这个函数需要两个参数:
- fun - 表示方程的函数。
- x0 - 根的初始猜测。
该函数返回一个对象,其中包含有关解决方案的信息。
from scipy.optimize import rootfrom math import cos
def eqn(x): return x + cos(x)
myroot = root(eqn, 0)
print(myroot.x)# 查看更多信息#print(myroot)最小化函数
函数表示一条曲线,曲线有高点和低点。
高点称为最大值。
低点称为最小值。
整条曲线中的最高点称为全局最大值,其余部分称为局部最大值。
整条曲线的最低点称为全局最小值,其余的称为局部最小值。
可以使用 scipy.optimize.minimize() 函数来最小化函数。
minimize() 函接受以下几个参数:
-
fun - 要优化的函数
-
x0 - 初始猜测值
-
method - 要使用的方法名称,值可以是:‘CG’,‘BFGS’,‘Newton-CG’,‘L-BFGS-B’,‘TNC’,‘COBYLA’,,‘SLSQP’。
-
callback - 每次优化迭代后调用的函数。
-
options - 定义其他参数的字典:
{"disp": boolean - print detailed description"gtol": number - the tolerance of the error}
使用 BFGS 的最小化函数:
from scipy.optimize import minimize
def eqn(x): return x**2 + x + 2
mymin = minimize(eqn, 0, method='BFGS')
print(mymin)scipy稀疏矩阵
稀疏矩阵(英语:sparse matrix)指的是在数值分析中绝大多数数值为零的矩阵。反之,如果大部分元素都非零,则这个矩阵是稠密的(Dense)。
在科学与工程领域中求解线性模型时经常出现大型的稀疏矩阵。
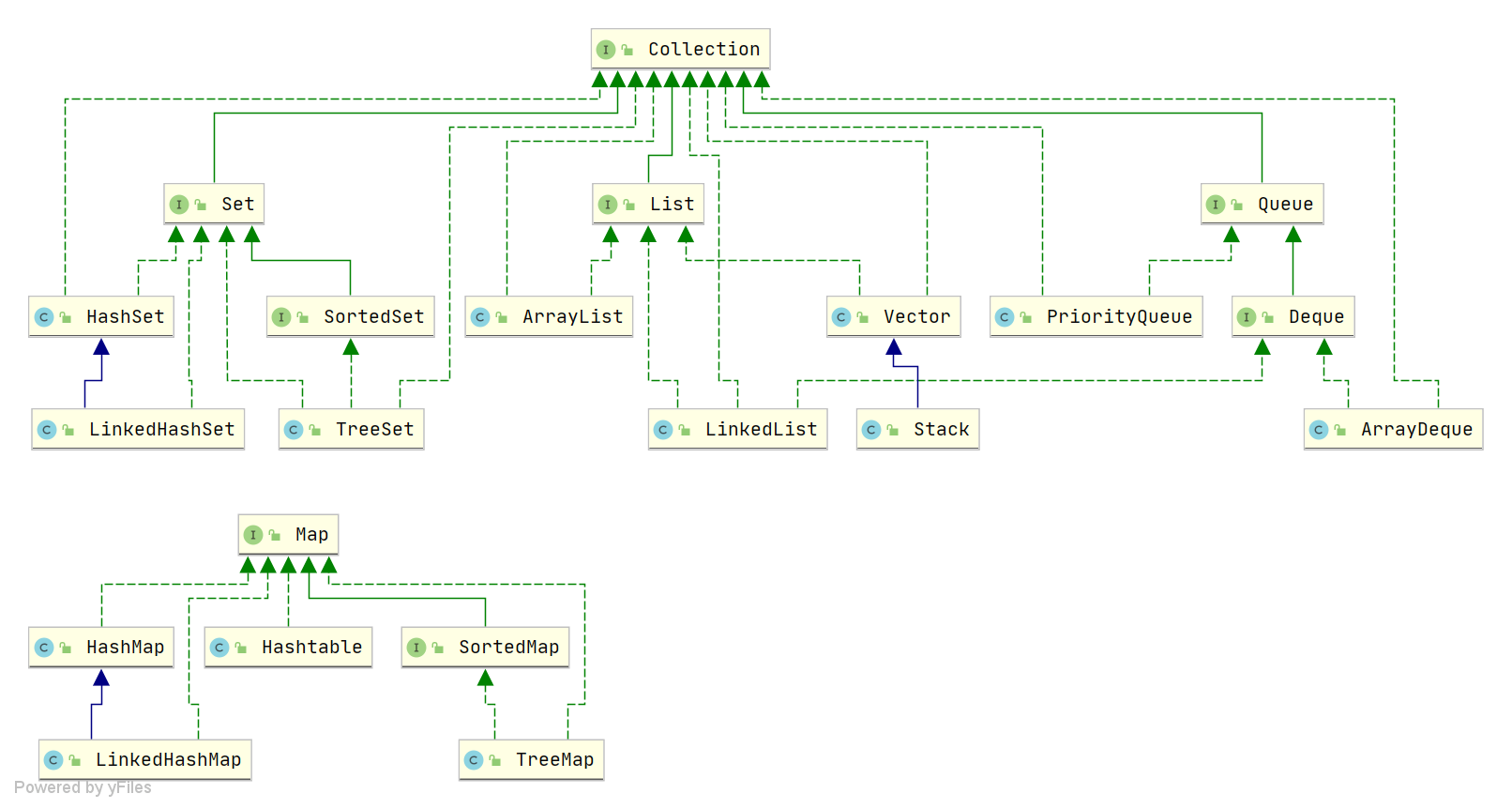
上述稀疏矩阵仅包含 9 个非零元素,另外包含 26 个零元。其稀疏度为 74%,密度为 26%。
SciPy 的 scipy.sparse 模块提供了处理稀疏矩阵的函数。
我们主要使用以下两种类型的稀疏矩阵:
- CSC - 压缩稀疏列(Compressed Sparse Column),按列压缩。
- CSR - 压缩稀疏行(Compressed Sparse Row),按行压缩。
本章节我们主要使用 CSR 矩阵。
CSR矩阵
我们可以通过向 scipy.sparse.csr_matrix() 函数传递数组来创建一个 CSR 矩阵。
# 创建 CSR 矩阵。import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([0, 0, 0, 0, 0, 1, 1, 0, 2])print(csr_matrix(arr))- data 使用 data 属性查看存储的数据(不含 0 元素):
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).data)- count_nonzero() 使用 count_nonzero() 方法计算非 0 元素的总数:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).count_nonzero())- eliminate_zeros() 使用 eliminate_zeros() 方法删除矩阵中 0 元素:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.eliminate_zeros()
print(mat)- sum_duplicates() 使用 sum_duplicates() 方法来删除重复项:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.sum_duplicates()
print(mat)- tocsc() csr 转换为 csc 使用 tocsc() 方法:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
newarr = csr_matrix(arr).tocsc()
print(newarr)SciPy 图结构
图结构是算法学中最强大的框架之一。
图是各种关系的节点和边的集合,节点是与对象对应的顶点,边是对象之间的连接。
SciPy 提供了 scipy.sparse.csgraph 模块来处理图结构。
邻接矩阵
邻接矩阵(Adjacency Matrix)是表示顶点之间相邻关系的矩阵。
邻接矩阵逻辑结构分为两部分:V 和 E 集合,其中,V 是顶点,E 是边,边有时会有权重,表示节点之间的连接强度。
用一个一维数组存放图中所有顶点数据,用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。
邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。
无向图是双向关系,边没有方向:
有向图的边带有方向,是单向关系:
连接组件
查看所有连接组件使用 connected_components() 方法。
import numpy as npfrom scipy.sparse.csgraph import connected_componentsfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(connected_components(newarr))Dijkstra — 最短路径算法
Dijkstra(迪杰斯特拉)最短路径算法,用于计算一个节点到其他所有节点的最短路径。
Scipy 使用 dijkstra() 方法来计算一个元素到其他元素的最短路径。 dijkstra() 方法可以设置以下几个参数:
- return_predecessors: 布尔值,设置 True,遍历所有路径,如果不想遍历所有路径可以设置为 False。
- indices: 元素的索引,返回该元素的所有路径。
- limit: 路径的最大权重。
# 查找元素 1 到 2 的最短路径:import numpy as npfrom scipy.sparse.csgraph import dijkstrafrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(dijkstra(newarr, return_predecessors=True, indices=0))Floyd Warshall — 弗洛伊德算法
弗洛伊德算法算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 floyd_warshall() 方法来查找所有元素对之间的最短路径。
# 查找所有元素对之间的最短路径径:import numpy as npfrom scipy.sparse.csgraph import floyd_warshallfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(floyd_warshall(newarr, return_predecessors=True))Bellman Ford — 贝尔曼-福特算法
贝尔曼-福特算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 bellman_ford() 方法来查找所有元素对之间的最短路径,通常可以在任何图中使用,包括有向图、带负权边的图。
# 使用负权边的图查找从元素 1 到元素 2 的最短路径:import numpy as npfrom scipy.sparse.csgraph import bellman_fordfrom scipy.sparse import csr_matrix
arr = np.array([ [0, -1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(bellman_ford(newarr, return_predecessors=True, indices=0))深度优先顺序
depth_first_order() 方法从一个节点返回深度优先遍历的顺序。
可以接收以下参数:
- 图
- 图开始遍历的元素
# 给定一个邻接矩阵,返回深度优先遍历的顺序:import numpy as npfrom scipy.sparse.csgraph import depth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(depth_first_order(newarr, 1))广度优先顺序
breadth_first_order() 方法从一个节点返回广度优先遍历的顺序。
可以接收以下参数:
- 图
- 图开始遍历的元素
# 给定一个邻接矩阵,返回广度优先遍历的顺序:import numpy as npfrom scipy.sparse.csgraph import breadth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(breadth_first_order(newarr, 1))SciPy 空间数据
空间数据又称几何数据,它用来表示物体的位置、形态、大小分布等各方面的信息,比如坐标上的点。
SciPy 通过 scipy.spatial 模块处理空间数据,比如判断一个点是否在边界内、计算给定点周围距离最近点以及给定距离内的所有点。
三角测量
三角测量在三角学与几何学上是一借由测量目标点与固定基准线的已知端点的角度,测量目标距离的方法。
多边形的三角测量是将多边形分成多个三角形,我们可以用这些三角形来计算多边形的面积。
拓扑学的一个已知事实告诉我们:任何曲面都存在三角剖分。
假设曲面上有一个三角剖分, 我们把所有三角形的顶点总个数记为 p(公共顶点只看成一个),边数记为 a,三角形的个数记为 n,则 e=p-a+n 是曲面的拓扑不变量。也就是说不管是什么剖分,e总是得到相同的数值。e被称为称为欧拉示性数。
对一系列的点进行三角剖分点方法是 Delaunay() 三角剖分。
# 通过给定的点来创建三角形:import numpy as npfrom scipy.spatial import Delaunayimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1]])
simplices = Delaunay(points).simplices # 三角形中顶点的索引
plt.triplot(points[:, 0], points[:, 1], simplices)plt.scatter(points[:, 0], points[:, 1], color='r')
plt.show()凸包
凸包(Convex Hull)是一个计算几何(图形学)中的概念。
在一个实数向量空间 V 中,对于给定集合 X,所有包含 X 的凸集的交集 S 被称为 X 的凸包。X 的凸包可以用 X 内所有点(X1,…Xn)的凸组合来构造。
我们可以使用 ConvexHull() 方法来创建凸包。
# 通过给定的点来创建凸包:import numpy as npfrom scipy.spatial import ConvexHullimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1], [1, 2], [5, 0], [3, 1], [1, 2], [0, 2]])
hull = ConvexHull(points)hull_points = hull.simplices
plt.scatter(points[:,0], points[:,1])for simplex in hull_points: plt.plot(points[simplex,0], points[simplex,1], 'k-')
plt.show()K-D 树
kd-tree(k-dimensional树的简称),是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。
K-D 树可以使用在多种应用场合,如多维键值搜索(范围搜寻及最邻近搜索)。
最邻近搜索用来找出在树中与输入点最接近的点。
KDTree() 方法返回一个 KDTree 对象。
query() 方法返回最邻近距离和最邻近位置。
查找到 (1,1) 的最邻近距离:from scipy.spatial import KDTree
points = [(1, -1), (2, 3), (-2, 3), (2, -3)]
kdtree = KDTree(points)
res = kdtree.query((1, 1))
print(res)距离矩阵
在数学中, 一个距离矩阵是一个各项元素为点之间距离的矩阵(二维数组)。因此给定 N 个欧几里得空间中的点,其距离矩阵就是一个非负实数作为元素的 N×N 的对称矩阵距离矩阵和邻接矩阵概念相似,其区别在于后者仅包含元素(点)之间是否有连边,并没有包含元素(点)之间的连通的距离的讯息。因此,距离矩阵可以看成是邻接矩阵的加权形式。
举例来说,我们分析如下二维点 a 至 f。在这里,我们把点所在像素之间的欧几里得度量作为距离度量。
欧几里得距离
在数学中,欧几里得距离或欧几里得度量是欧几里得空间中两点间”普通”(即直线)距离。使用这个距离,欧氏空间成为度量空间。相关联的范数称为欧几里得范数。较早的文献称之为毕达哥拉斯度量。
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
from scipy.spatial.distance import euclidean
p1 = (1, 0)p2 = (10, 2)
res = euclidean(p1, p2)
print(res)曼哈顿距离
出租车几何或曼哈顿距离(Manhattan Distance)是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,是种使用在几何度量空间的几何学用语,用以标明两个点在标准坐标系上的绝对轴距总和。
曼哈顿距离 只能上、下、左、右四个方向进行移动,并且两点之间的曼哈顿距离是两点之间的最短距离。
曼哈顿与欧几里得距离: 红、蓝与黄线分别表示所有曼哈顿距离都拥有一样长度(12),而绿线表示欧几里得距离有6×√2 ≈ 8.48的长度。
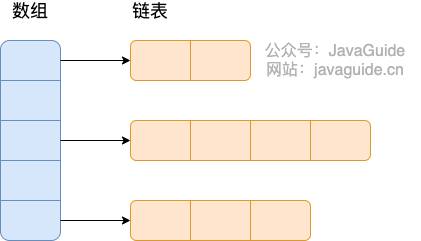
余弦距离
余弦距离,也称为余弦相似度,通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
0 度角的余弦值是 1,而其他任何角度的余弦值都不大于 1,并且其最小值是 -1。
# 计算 A 与 B 两点的余弦距离:from scipy.spatial.distance import cosine
p1 = (1, 0)p2 = (10, 2)
res = cosine(p1, p2)
print(res)汉明距离
在信息论中,两个等长字符串之间的汉明距离(英语:Hamming distance)是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。
汉明重量是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是 1 的个数,所以 11101 的汉明重量是4。
- 1011101与1001001之间的汉明距离是2。
- 2143896与2233796之间的汉明距离是3。
- “toned”与”roses”之间的汉明距离是3。
# 计算两个点之间的汉明距离:from scipy.spatial.distance import hamming
p1 = (True, False, True)p2 = (False, True, True)
res = hamming(p1, p2)
print(res)SciPy Matlab 数组
NumPy 提供了 Python 可读格式的数据保存方法。
SciPy 提供了与 Matlab 的交互的方法。
SciPy 的 scipy.io 模块提供了很多函数来处理 Matlab 的数组。
以 Matlab 格式导出数据
savemat() 方法可以导出 Matlab 格式的数据。 该方法参数有:
- filename - 保存数据的文件名。
- mdict - 包含数据的字典。
- do_compression - 布尔值,指定结果数据是否压缩。默认为 False。
# 将数组作为变量 "vec" 导出到 mat 文件:from scipy import ioimport numpy as np
arr = np.arange(10)
io.savemat('arr.mat', {"vec": arr})注意:上面的代码会在您的计算机上保存了一个名为 “arr.mat” 的文件。
导入 Matlab 格式数据
loadmat() 方法可以导入 Matlab 格式数据。
该方法参数:
- filename - 保存数据的文件名。
返回一个结构化数组,其键是变量名,对应的值是变量值。
# 从 mat 文件中导入数组:from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# 导出io.savemat('arr.mat', {"vec": arr})
# 导入mydata = io.loadmat('arr.mat')
print(mydata)
# 使用变量名 "vec" 只显示 matlab 数据的数组:print(mydata['vec'])从结果可以看出数组最初是一维的,但在提取时它增加了一个维度,变成了二维数组。
解决这个问题可以传递一个额外的参数 squeeze_me=True:
from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# 导出io.savemat('arr.mat', {"vec": arr})
# 导入mydata = io.loadmat('arr.mat', squeeze_me=True)
print(mydata['vec'])SciPy 插值
什么是插值?
在数学的数值分析领域中,插值(英语:interpolation)是一种通过已知的、离散的数据点,在范围内推求新数据点的过程或方法。
简单来说插值是一种在给定的点之间生成点的方法。
例如:对于两个点 1 和 2,我们可以插值并找到点 1.33 和 1.66。
插值有很多用途,在机器学习中我们经常处理数据缺失的数据,插值通常可用于替换这些值。
这种填充值的方法称为插补。
除了插补,插值经常用于我们需要平滑数据集中离散点的地方。
如何在 SciPy 中实现插值?
SciPy 提供了 scipy.interpolate 模块来处理插值。
一维插值
一维数据的插值运算可以通过方法 interp1d() 完成。
该方法接收两个参数 x 点和 y 点。
返回值是可调用函数,该函数可以用新的 x 调用并返回相应的 y,y = f(x)。
# 对给定的 xs 和 ys 插值,从 2.1、2.2... 到 2.9:from scipy.interpolate import interp1dimport numpy as np
xs = np.arange(10)ys = 2*xs + 1
interp_func = interp1d(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)单变量插值
在一维插值中,点是针对单个曲线拟合的,而在样条插值中,点是针对使用多项式分段定义的函数拟合的。
单变量插值使用 UnivariateSpline() 函数,该函数接受 xs 和 ys 并生成一个可调用函数,该函数可以用新的 xs 调用。
分段函数,就是对于自变量 x 的不同的取值范围,有着不同的解析式的函数。
# 为非线性点找到 2.1、2.2...2.9 的单变量样条插值:from scipy.interpolate import UnivariateSplineimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = UnivariateSpline(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)径向基函数插值
径向基函数是对应于固定参考点定义的函数。
曲面插值里我们一般使用径向基函数插值。
# Rbf() 函数接受 xs 和 ys 作为参数,并生成一个可调用函数from scipy.interpolate import Rbfimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = Rbf(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)Scipy 显著性检验
显著性检验(significance test)就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设(备择假设)是否合理,即判断总体的真实情况与原假设是否有显著性差异。 或者说,显著性检验要判断样本与我们对总体所做的假设之间的差异是纯属机会变异,还是由我们所做的假设与总体真实情况之间不一致所引起的。 显著性检验是针对我们对总体所做的假设做检验,其原理就是”小概率事件实际不可能性原理”来接受或否定假设。
显著性检验即用于实验处理组与对照组或两种不同处理的效应之间是否有差异,以及这种差异是否显著的方法。
SciPy 提供了 scipy.stats 的模块来执行Scipy 显著性检验的功能。
统计假设
统计假设是关于一个或多个随机变量的未知分布的假设。随机变量的分布形式已知,而仅涉及分布中的一个或几个未知参数的统计假设,称为参数假设。检验统计假设的过程称为假设检验,判别参数假设的检验称为参数检验。
零假设
零假设(null hypothesis),统计学术语,又称原假设,指进行统计检验时预先建立的假设。 零假设成立时,有关统计量应服从已知的某种概率分布。
当统计量的计算值落入否定域时,可知发生了小概率事件,应否定原假设。
常把一个要检验的假设记作 H0,称为原假设(或零假设)(null hypothesis),与H0对立的假设记作 H1,称为备择假设 (alternative hypothesis)
- 在原假设为真时,决定放弃原假设,称为第一类错误,其出现的概率通常记作 α;
- 在原假设不真时,决定不放弃原假设,称为第二类错误,其出现的概率通常记作 β
- α+β 不一定等于 1。
通常只限定犯第一类错误的最大概率 α, 不考虑犯第二类错误的概率 β。这样的假设 检验又称为显著性检验,概率 α 称为显著性水平。
最常用的 α 值为 0.01、0.05、0.10 等。一般情况下,根据研究的问题,如果放弃真假设损失大,为减少这类错误,α 取值小些 ,反之,α 取值大些。
备择假设
备择假设(alternative hypothesis)是统计学的基本概念之一,其包含关于总体分布的一切使原假设不成立的命题。备择假设亦称对立假设、备选假设。
备择假设可以替代零假设。
例如我们对于学生的评估,我们将采取:
- “学生比平均水平差” -— 作为零假设
- “学生优于平均水平” —— 作为替代假设。
单边检验
单边检验(one-sided test)亦称单尾检验,又称单侧检验,在假设检验中,用检验统计量的密度曲线和二轴所围成面积中的单侧尾部面积来构造临界区域进行检验的方法称为单边检验。
当我们的假设仅测试值的一侧时,它被称为”单尾测试”。
例子:
对于零假设:
“均值等于 k”
我们可以有替代假设:
- “平均值小于 k”
- “平均值大于 k”
双边检验
双边检验(two-sided test),亦称双尾检验、双侧检验.在假设检验中,用检验统计量的密度曲线和x轴所围成的面积的左右两边的尾部面积来构造临界区域进行检验的方法。
当我们的假设测试值的两边时。
例子:
对于零假设:
“均值等于 k”
我们可以有替代假设:
“均值不等于k”
在这种情况下,均值小于或大于 k,两边都要检查。
阿尔法值
阿尔法值是显著性水平。
显著性水平是估计总体参数落在某一区间内,可能犯错误的概率,用 α 表示。
数据必须有多接近极端才能拒绝零假设。
通常取为 0.01、0.05 或 0.1。
P 值
P 值表明数据实际接近极端的程度。
比较 P 值和阿尔法值(alpha)来确定统计显著性水平。
如果 p 值 <= alpha,我们拒绝原假设并说数据具有统计显著性,否则我们接受原假设。
T 检验(T-Test)
T 检验用于确定两个变量的均值之间是否存在显著差异,并判断它们是否属于同一分布。
这是一个双尾测试。
函数 ttest_ind() 获取两个相同大小的样本,并生成 t 统计和 p 值的元组。
# 查找给定值 v1 和 v2 是否来自相同的分布:import numpy as npfrom scipy.stats import ttest_ind
v1 = np.random.normal(size=100)v2 = np.random.normal(size=100)
res = ttest_ind(v1, v2)
print(res)
# 只想返回 p 值res = ttest_ind(v1, v2).pvalueprint(res)KS 检验
KS 检验用于检查给定值是否符合分布。
该函数接收两个参数;测试的值和 CDF。
CDF 为累积分布函数(Cumulative Distribution Function),又叫分布函数。
CDF 可以是字符串,也可以是返回概率的可调用函数。
它可以用作单尾或双尾测试。
默认情况下它是双尾测试。 我们可以将参数替代作为两侧、小于或大于其中之一的字符串传递。
# 查找给定值是否符合正态分布:import numpy as npfrom scipy.stats import kstest
v = np.random.normal(size=100)
res = kstest(v, 'norm')
print(res)数据统计说明
使用 describe() 函数可以查看数组的信息,包含以下值:
- nobs — 观测次数
- minmax — 最小值和最大值
- mean — 数学平均数
- variance — 方差
- skewness — 偏度
- kurtosis — 峰度
# 显示数组中的统计描述信息:import numpy as npfrom scipy.stats import describe
v = np.random.normal(size=100)res = describe(v)
print(res)正态性检验(偏度和峰度)
利用观测数据判断总体是否服从正态分布的检验称为正态性检验,它是统计判决中重要的一种特殊的拟合优度假设检验。
正态性检验基于偏度和峰度。
normaltest() 函数返回零假设的 p 值:
“x 来自正态分布”
偏度
数据对称性的度量。
对于正态分布,它是 0。
如果为负,则表示数据向左倾斜。
如果是正数,则意味着数据是正确倾斜的。
峰度
衡量数据是重尾还是轻尾正态分布的度量。
正峰度意味着重尾。
负峰度意味着轻尾。
# 查找数组中值的偏度和峰度:import numpy as npfrom scipy.stats import skew, kurtosisfrom scipy.stats import normaltest
v = np.random.normal(size=100)
print(skew(v))print(kurtosis(v))
# 查找数据是否来自正态分布:print(normaltest(v))Scipy
Introduction
SciPy is an open-source Python library for mathematics and scientific computing.
SciPy is a scientific computing library built on NumPy, used in mathematics, science, engineering, and other fields where many advanced abstractions and physical models require SciPy.
SciPy includes modules for optimization, linear algebra, integration, interpolation, special functions, fast Fourier transforms, signal processing and image processing, solving ordinary differential equations, and other computations commonly used in science and engineering.
Applications
SciPy is a widely used package for mathematics, science, and engineering, capable of handling optimization, linear algebra, integration, interpolation, fitting, special functions, fast Fourier transforms, signal processing, image processing, solvers for ordinary differential equations, and more.
SciPy includes modules for optimization, linear algebra, integration, interpolation, special functions, fast Fourier transforms, signal processing and image processing, solving ordinary differential equations, and other computations common in science and engineering.
The synergy between NumPy and SciPy enables efficient solutions to many problems, with broad applications in astronomy, biology, meteorology and climate science, as well as materials science and other disciplines.
Installation
python3 -m pip install -U pippython3 -m pip install -U scipyVerify the installation:
import scipy
print(scipy.__version__)Module List
The following lists some commonly used SciPy modules and their official API URLs:
| Module name | Function / Description | Reference documentation |
|---|---|---|
| scipy.cluster | Vector quantization | cluster API |
| scipy.constants | Mathematical constants | constants API |
| scipy.fft | Fast Fourier Transform | fft API |
| scipy.integrate | Integration | integrate API |
| scipy.interpolate | Interpolation | interpolate API |
| scipy.io | Data input/output | io API |
| scipy.linalg | Linear algebra | linalg API |
| scipy.misc | Image processing | misc API |
| scipy.ndimage | N-dimensional image | ndimage API |
| scipy.odr | Orthogonal distance regression | odr API |
| scipy.optimize | Optimization algorithms | optimize API |
| scipy.signal | Signal processing | signal API |
| scipy.sparse | Sparse matrices | sparse API |
| scipy.spatial | Spatial data structures and algorithms | spatial API |
| scipy.special | Special mathematical functions | special API |
| scipy.stats | Statistical functions | stats.mstats API |
For more module content, see the official documentation: https://docs.scipy.org/doc/scipy/reference/
SciPy Constants Module
SciPy’s constants module, constants, provides many built-in mathematical constants.
Pi is a mathematical constant—the ratio of a circle’s circumference to its diameter, approximately 3.14159, commonly denoted by the symbol π.
The following prints pi:
from scipy import constants
print(constants.pi)The following prints the golden ratio:
from scipy import constants
print(constants.golden)We can use the dir() function to see which constants are contained in the constants module:
from scipy import constants
print(dir(constants))Unit Types
The constants module contains the following kinds of units:
-
SI prefixes The International System of Units prefixes (SI prefixes) denote multiples and submultiples of units; there are currently 20 prefixes, most of which are powers of ten. (centi equals 0.01):
from scipy import constantsprint(constants.yotta) #1e+24print(constants.zetta) #1e+21print(constants.exa) #1e+18print(constants.peta) #1000000000000000.0print(constants.tera) #1000000000000.0print(constants.giga) #1000000000.0print(constants.mega) #1000000.0print(constants.kilo) #1000.0print(constants.hecto) #100.0print(constants.deka) #10.0print(constants.deci) #0.1print(constants.centi) #0.01print(constants.milli) #0.001print(constants.micro) #1e-06print(constants.nano) #1e-09print(constants.pico) #1e-12print(constants.femto) #1e-15print(constants.atto) #1e-18print(constants.zepto) #1e-21 -
Binary, in bytes Returns byte units (kibi = 1024).
from scipy import constantsprint(constants.kibi) #1024print(constants.mebi) #1048576print(constants.gibi) #1073741824print(constants.tebi) #1099511627776print(constants.pebi) #1125899906842624print(constants.exbi) #1152921504606846976print(constants.zebi) #1180591620717411303424print(constants.yobi) #1208925819614629174706176 -
Mass units Returns kilograms (kg). (gram returns 0.001).
from scipy import constantsprint(constants.gram) #0.001print(constants.metric_ton) #1000.0print(constants.grain) #6.479891e-05print(constants.lb) #0.45359236999999997print(constants.pound) #0.45359236999999997print(constants.oz) #0.028349523124999998print(constants.ounce) #0.028349523124999998print(constants.stone) #6.3502931799999995print(constants.long_ton) #1016.0469088print(constants.short_ton) #907.1847399999999print(constants.troy_ounce) #0.031103476799999998print(constants.troy_pound) #0.37324172159999996print(constants.carat) #0.0002print(constants.atomic_mass) #1.66053904e-27print(constants.m_u) #1.66053904e-27print(constants.u) #1.66053904e-27 -
Angle conversions Returns radians (degree returns 0.017453292519943295).
from scipy import constantsprint(constants.degree) #0.017453292519943295print(constants.arcmin) #0.0002908882086657216print(constants.arcminute) #0.0002908882086657216print(constants.arcsec) #4.84813681109536e-06print(constants.arcsecond) #4.84813681109536e-06 -
Time units Returns seconds (hour returns 3600.0).
from scipy import constantsprint(constants.minute) #60.0print(constants.hour) #3600.0print(constants.day) #86400.0print(constants.week) #604800.0print(constants.year) #31536000.0print(constants.Julian_year) #31557600.0 -
Length units Returns meters (nautical_mile returns 1852.0).
from scipy import constantsprint(constants.inch) #0.0254print(constants.foot) #0.30479999999999996print(constants.yard) #0.9143999999999999print(constants.mile) #1609.3439999999998print(constants.mil) #2.5399999999999997e-05print(constants.pt) #0.00035277777777777776print(constants.point) #0.00035277777777777776print(constants.survey_foot) #0.3048006096012192print(constants.survey_mile) #1609.3472186944373print(constants.nautical_mile) #1852.0print(constants.fermi) #1e-15print(constants.angstrom) #1e-10print(constants.micron) #1e-06print(constants.au) #149597870691.0print(constants.astronomical_unit) #149597870691.0print(constants.light_year) #9460730472580800.0print(constants.parsec) #3.0856775813057292e+16 -
Pressure units Returns pascals, the SI unit of pressure. (psi returns 6894.757293168361).
from scipy import constantsprint(constants.atm) #101325.0print(constants.atmosphere) #101325.0print(constants.bar) #100000.0print(constants.torr) #133.32236842105263print(constants.mmHg) #133.32236842105263print(constants.psi) #6894.757293168361 -
Area units Returns square meters, the metric unit of area; defined as the area of a square with side length 1 meter. (hectare returns 10000.0).
from scipy import constantsprint(constants.hectare) #10000.0print(constants.acre) #4046.8564223999992 -
Volume units
Returns cubic meters; a volume of one cubic meter is the volume of a cube with sides of 1 meter; equal to 1 liter and 1 cubic decimeter, and equal to 1,000,000 cubic centimeters. (liter returns 0.001).
from scipy import constantsprint(constants.liter) #0.001print(constants.litre) #0.001print(constants.gallon) #0.0037854117839999997print(constants.gallon_US) #0.0037854117839999997print(constants.gallon_imp) #0.00454609print(constants.fluid_ounce) #2.9573529562499998e-05print(constants.fluid_ounce_US) #2.9573529562499998e-05print(constants.fluid_ounce_imp) #2.84130625e-05print(constants.barrel) #0.15898729492799998print(constants.bbl) #0.15898729492799998 -
Speed units Returns meters per second. (speed_of_sound returns 340.5).
from scipy import constantsprint(constants.kmh) #0.2777777777777778print(constants.mph) #0.44703999999999994print(constants.mach) #340.5print(constants.speed_of_sound) #340.5print(constants.knot) #0.5144444444444445 -
Temperature units Returns kelvin. (zero_Celsius returns 273.15).
from scipy import constantsprint(constants.zero_Celsius) #273.15print(constants.degree_Fahrenheit) #0.5555555555555556 -
Energy units Returns joules; the joule (symbol J) is the SI derived unit of energy, work, or heat. (calorie returns 4.184).
from scipy import constantsprint(constants.calorie) #4.184 -
Power units Returns watts; the watt (symbol W) is the SI unit of power. One watt is defined as one joule per second (1 J/s), i.e., the rate of energy conversion, use, or dissipation. (horsepower returns 745.6998715822701).
from scipy import constantsprint(constants.hp) #745.6998715822701print(constants.horsepower) #745.6998715822701 -
Dynamical (mechanical) units Returns newtons; the newton (symbol N) is the SI unit of force. It is named after Isaac Newton, the founder of classical mechanics. (kilogram_force returns 9.80665).
from scipy import constantsprint(constants.dyn) #1e-05print(constants.dyne) #1e-05print(constants.lbf) #4.4482216152605print(constants.pound_force) #4.4482216152605print(constants.kgf) #9.80665print(constants.kilogram_force) #9.80665
SciPy Optimizers
SciPy’s optimize module provides implementations of common optimization algorithms that we can call directly to solve optimization problems, such as finding the minimum of a function or the roots of equations.
Root Finding
NumPy can find roots of polynomials and linear equations, but it cannot find roots of nonlinear equations, as shown below:
x + cos(x)
Therefore we can use SciPy’s optimize.root function, which requires two parameters:
- fun - the function representing the equation.
- x0 - initial guess for the root.
The function returns an object containing information about the solution.
from scipy.optimize import rootfrom math import cos
def eqn(x): return x + cos(x)
myroot = root(eqn, 0)
print(myroot.x)# See more information#print(myroot)Minimizing Functions
A function represents a curve with maxima and minima.
- A high point is called a maximum.
- A low point is called a minimum.
- The highest point on the entire curve is the global maximum; the rest are local maxima.
- The lowest point on the entire curve is the global minimum; the rest are local minima.
You can use the scipy.optimize.minimize() function to minimize a function.
minimize() accepts the following parameters:
-
fun - the function to optimize
-
x0 - initial guess
-
method - the name of the method to use; values can be: ‘CG’, ‘BFGS’, ‘Newton-CG’, ‘L-BFGS-B’, ‘TNC’, ‘COBYLA’, ‘SLSQP’.
-
callback - the function called after each optimization iteration.
-
options - dictionary for other parameters:
{"disp": boolean - print detailed description"gtol": number - the tolerance of the error}
The minimization of x^2 + x + 2 using BFGS:
from scipy.optimize import minimize
def eqn(x): return x**2 + x + 2
mymin = minimize(eqn, 0, method='BFGS')
print(mymin)SciPy Sparse Matrices
A sparse matrix is a matrix in which the vast majority of the elements are zero. Conversely, if most elements are nonzero, the matrix is dense.
In science and engineering, large sparse matrices frequently arise when solving linear models.
The above sparse matrix contains only 9 nonzero elements, with 26 zeros. Its sparsity is 74%, density 26%.
SciPy’s scipy.sparse module provides functions for working with sparse matrices.
We primarily use the following two types of sparse matrices:
- CSC - Compressed Sparse Column, compressed by column.
- CSR - Compressed Sparse Row, compressed by row.
In this chapter we primarily use CSR matrices.
CSR Matrix
We can create a CSR matrix by passing an array to the scipy.sparse.csr_matrix() function.
# Create a CSR matrix.import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([0, 0, 0, 0, 0, 1, 1, 0, 2])print(csr_matrix(arr))- data Use the data attribute to view the stored data (excluding zero elements):
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).data)- count_nonzero() Use count_nonzero() to count the total number of non-zero elements:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).count_nonzero())- eliminate_zeros() Use eliminate_zeros() to remove zero elements from the matrix:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.eliminate_zeros()
print(mat)- sum_duplicates() Use sum_duplicates() to remove duplicates:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.sum_duplicates()
print(mat)- tocsc() Convert CSR to CSC using tocsc():
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
newarr = csr_matrix(arr).tocsc()
print(newarr)SciPy Graph Structures
Graphs are one of the most powerful frameworks in algorithmic theory.
A graph is a set of nodes (vertices) and edges representing relationships; nodes correspond to objects and edges connect them.
SciPy provides the scipy.sparse.csgraph module to handle graph structures.
Adjacency Matrix
An Adjacency Matrix is a matrix representing the adjacency relationships between vertices.
The adjacency matrix structure consists of two sets: V (vertices) and E (edges); edges may have weights indicating the strength of connections between nodes.
The above sparse matrix contains only 9 nonzero elements, with 26 zeros. Its sparsity is 74%, density 26%.
We can store all vertex data in a 1D array and the relationships between vertices (edges or arcs) in a 2D array; this 2D array is called the adjacency matrix.
Adjacency matrices can distinguish between directed and undirected graphs.
An undirected graph is a bidirectional relationship; edges have no direction:
A directed graph’s edges have direction and represent a one-way relationship:
Connected Components
View all connected components using connected_components().
import numpy as npfrom scipy.sparse.csgraph import connected_componentsfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(connected_components(newarr))Dijkstra — Shortest Path Algorithm
Dijkstra’s algorithm computes the shortest paths from one node to all others.
SciPy uses the dijkstra() function to compute the shortest paths from one element to the others. The dijkstra() function can be configured with the following parameters:
- return_predecessors: Boolean, set to True to traverse all paths; if you do not want to traverse all paths, set to False.
- indices: Indices of the elements; returns all paths to that element.
- limit: The maximum weight of a path.
# Find the shortest path from element 1 to 2:import numpy as npfrom scipy.sparse.csgraph import dijkstrafrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(dijkstra(newarr, return_predecessors=True, indices=0))Floyd Warshall — Floyd-Warshall Algorithm
The Floyd-Warshall algorithm solves the all-pairs shortest path problem.
SciPy uses floyd_warshall() to find the shortest paths between all pairs of elements.
# Find the shortest paths between all pairs:import numpy as npfrom scipy.sparse.csgraph import floyd_warshallfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(floyd_warshall(newarr, return_predecessors=True))Bellman Ford — Bellman-Ford Algorithm
The Bellman-Ford algorithm solves the all-pairs shortest path problem.
SciPy uses bellman_ford() to find the shortest paths between all pairs of nodes; it can be used on any graph, including directed graphs and graphs with negative edge weights.
# Find the shortest path from element 1 to element 2 on a graph with negative weights:import numpy as npfrom scipy.sparse.csgraph import bellman_fordfrom scipy.sparse import csr_matrix
arr = np.array([ [0, -1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(bellman_ford(newarr, return_predecessors=True, indices=0))Depth-First Order
depth_first_order() returns the depth-first traversal order from a node.
It accepts the following parameters:
- Graph
- The starting element for traversal
# Given an adjacency matrix, return the depth-first traversal order:import numpy as npfrom scipy.sparse.csgraph import depth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(depth_first_order(newarr, 1))Breadth-First Order
breadth_first_order() returns the breadth-first traversal order from a node.
It accepts the following parameters:
- Graph
- The starting element for traversal
# Given an adjacency matrix, return the breadth-first traversal order:import numpy as npfrom scipy.sparse.csgraph import breadth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(breadth_first_order(newarr, 1))SciPy Spatial Data
Spatial data, also known as geometric data, is used to represent information about the position, shape, size, and distribution of objects, such as points in coordinates.
SciPy handles spatial data via the scipy.spatial module, for example, determining whether a point lies within a boundary, computing the nearest point around a given point, and finding all points within a given distance.
Triangulation
Triangulation in trigonometry and geometry is a method of measuring the distance to a target by using the angles at known endpoints of fixed reference lines.
Polygon triangulation divides a polygon into multiple triangles; we can use these triangles to compute the polygon’s area.
Topology tells us that every surface admits a triangulation.
Suppose a triangulation of a surface exists; let p be the total number of vertices (identical vertices counted once), a the number of edges, and n the number of triangles; then e = p - a + n is a topological invariant of the surface. In other words, regardless of the particular triangulation, e yields the same value. e is called the Euler characteristic.
Delaunay() triangulation is used for triangulating a set of points.
# Create triangles from given points:import numpy as npfrom scipy.spatial import Delaunayimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1]])
simplices = Delaunay(points).simplices # indices of vertices of triangles
plt.triplot(points[:, 0], points[:, 1], simplices)plt.scatter(points[:, 0], points[:, 1], color='r')
plt.show()Convex Hull
A convex hull is a concept in computational geometry.
In a real vector space V, given a set X, the intersection of all convex sets containing X is called the convex hull of X. The convex hull of X can be constructed by convex combinations of all points in X (X1, … Xn).
We can create a convex hull using the ConvexHull() method.
# Create a convex hull from given points:import numpy as npfrom scipy.spatial import ConvexHullimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1], [1, 2], [5, 0], [3, 1], [1, 2], [0, 2]])
hull = ConvexHull(points)hull_points = hull.simplices
plt.scatter(points[:,0], points[:,1])for simplex in hull_points: plt.plot(points[simplex,0], points[simplex,1], 'k-')
plt.show()KD-Tree
A kd-tree (short for k-dimensional tree) is a tree data structure used for storing points in a k-dimensional space to enable fast retrieval. It is commonly used for searching high-dimensional data (e.g., range searches and nearest-neighbor searches).
KDTree() returns a KDTree object.
The query() method returns the nearest distance and the nearest location.
# Nearest distance to (1,1):from scipy.spatial import KDTree
points = [(1, -1), (2, 3), (-2, 3), (2, -3)]
kdtree = KDTree(points)
res = kdtree.query((1, 1))
print(res)Distance Matrix
In mathematics, a distance matrix is a matrix whose elements are the distances between points (a two-dimensional array). Given N points in Euclidean space, the distance matrix is an N×N symmetric matrix with non-negative real entries, conceptually similar to an adjacency matrix, but the latter only indicates whether there is a connection between points and does not contain information about the actual distances between points. Therefore, a distance matrix can be viewed as a weighted form of an adjacency matrix.
For example, we analyze the following 2D points a to f. Here, we use the Euclidean distances between points as the distance measure.
Euclidean Distance
In mathematics, the Euclidean distance or Euclidean metric is the standard (straight-line) distance between two points in Euclidean space. Using this distance makes Euclidean space a metric space. The associated norm is called the Euclidean norm. Earlier literature called it the Pythagorean distance.
Euclidean distance (euclidean metric) is a commonly used distance definition, referring to the true distance between two points in an m-dimensional space, or the natural length of a vector (i.e., the distance from the origin). In 2D and 3D space, the Euclidean distance is simply the actual distance between two points.
from scipy.spatial.distance import euclidean
p1 = (1, 0)p2 = (10, 2)
res = euclidean(p1, p2)
print(res)Manhattan Distance
The Manhattan distance, coined by Hermann Minkowski in the 19th century, is a term in geometry used in metric spaces to denote the sum of the absolute distances along each axis between two points in a standard coordinate system.
Manhattan distance can only move in the four cardinal directions (up, down, left, right); the distance between two points using Manhattan distance is the shortest path under those constraints.
Manhattan and Euclidean distances: the red, blue, and yellow lines all have the same length (12) for Manhattan distance, while the green line shows the Euclidean distance is 6×√2 ≈ 8.48.
Cosine Distance
Cosine distance, also known as cosine similarity, measures how similar two vectors are by the cosine of the angle between them.
0 degrees has a cosine value of 1; for any other angle, the cosine value is not greater than 1 and minimum is -1.
# Compute the cosine distance between A and B:from scipy.spatial.distance import cosine
p1 = (1, 0)p2 = (10, 2)
res = cosine(p1, p2)
print(res)Hamming Distance
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different. In other words, it counts the number of substitutions required to transform one string into another.
Hamming weight is the Hamming distance of a string relative to a zero string of the same length; that is, the number of nonzero elements in the string: for binary strings, the number of 1s, so the Hamming weight of 11101 is 4.
- The Hamming distance between 1011101 and 1001001 is 2.
- The Hamming distance between 2143896 and 2233796 is 3.
- The Hamming distance between “toned” and “roses” is 3.
# Compute the Hamming distance between two points:from scipy.spatial.distance import hamming
p1 = (True, False, True)p2 = (False, True, True)
res = hamming(p1, p2)
print(res)SciPy MATLAB Arrays
NumPy provides a Python-readable format for saving data.
SciPy provides MATLAB interoperability.
SciPy’s scipy.io module provides many functions to work with MATLAB arrays.
Export data to MATLAB format
The savemat() method can export data in MATLAB format. The method has these parameters:
- filename - the name of the file to save the data.
- mdict - dictionary containing the data.
- do_compression - boolean indicating whether to compress the resulting data. Default is False.
# Export the array as a variable "vec" to a mat file:from scipy import ioimport numpy as np
arr = np.arange(10)
io.savemat('arr.mat', {"vec": arr})Note: The above code will save a file named “arr.mat” on your computer.
Import MATLAB format data
The loadmat() method can import MATLAB format data.
This method has the following parameters:
- filename - the file name to load.
Return a structured array whose keys are variable names and whose values are the corresponding variable values.
# Import from a mat file:from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# Exportio.savemat('arr.mat', {"vec": arr})
# Importmydata = io.loadmat('arr.mat')
print(mydata)
# Display only the MATLAB array with the variable name "vec":print(mydata['vec'])From the result, you can see the array was originally one-dimensional, but when extracted it gains an extra dimension and becomes a two-dimensional array.
To resolve this, you can pass an extra parameter squeeze_me=True:
from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# Exportio.savemat('arr.mat', {"vec": arr})
# Importmydata = io.loadmat('arr.mat', squeeze_me=True)
print(mydata['vec'])SciPy Interpolation
What is interpolation?
In numerical analysis, interpolation is a method or process for estimating new data points within the range of a discrete set of known data points.
In simple terms, interpolation is a method for generating points between given points.
For example, for two points 1 and 2, we can interpolate to obtain points 1.33 and 1.66.
Interpolation has many applications; in machine learning, we often deal with missing data, and interpolation can be used to fill in these values.
This filling approach is called imputation.
Besides imputation, interpolation is frequently used wherever we need to smooth discrete points in a data set.
How to implement interpolation in SciPy?
SciPy provides the scipy.interpolate module to handle interpolation.
One-dimensional interpolation
Interpolation for one-dimensional data can be performed with the interp1d() method.
The method takes two inputs, x and y.
The return value is a callable function that you can call with new x values to obtain the corresponding y, i.e., y = f(x).
# Interpolate given xs and ys from 2.1, 2.2... to 2.9:from scipy.interpolate import interp1dimport numpy as np
xs = np.arange(10)ys = 2*xs + 1
interp_func = interp1d(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)Univariate Interpolation
In one-dimensional interpolation, the points are fitted to a single curve, whereas in spline interpolation, the points are fitted to functions defined by piecewise polynomials.
Univariate interpolation uses the UnivariateSpline() function, which takes xs and ys and returns a callable function that can be called with new xs.
A piecewise function is a function that has different analytic expressions over different ranges of the independent variable x.
# Find the univariate spline interpolation for nonlinear points at 2.1, 2.2...2.9:from scipy.interpolate import UnivariateSplineimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = UnivariateSpline(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)Radial Basis Function Interpolation
Radial basis functions are functions defined with respect to fixed reference points.
In surface interpolation we typically use radial basis function interpolation.
# The Rbf() function accepts xs and ys as arguments and returns a callable functionfrom scipy.interpolate import Rbfimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = Rbf(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)SciPy Significance Testing
A significance test is a hypothesis test conducted by making an a priori assumption about the population (random variable) or its distribution, and then using sample information to determine whether this assumption (the alternative hypothesis) is reasonable; i.e., whether the true population deviates significantly from the null hypothesis. In other words, a significance test asks whether the difference between the sample and our assumption about the population is due to random variation or a real discrepancy between the assumption and the population.
Significance testing is used to determine whether there is a difference between experimental and control groups, or between two different treatments, and whether that difference is statistically significant.
SciPy provides the scipy.stats module to perform SciPy significance testing.
Statistical Hypotheses
A statistical hypothesis concerns the unknown distribution of one or more random variables. A statistical hypothesis that concerns only one or a few unknown parameters within a known distribution is called a parameter hypothesis. The process of testing a statistical hypothesis is called hypothesis testing; testing a parameter hypothesis is called a parameter test.
Null Hypothesis
The null hypothesis, a term in statistics, also called the original hypothesis, is the hypothesis that is stated before performing a statistical test. When the null hypothesis is true, the test statistic should follow a known probability distribution.
When the computed statistic falls into the rejection region, a rare event has occurred, and the null hypothesis should be rejected.
A hypothesis to be tested is usually denoted as H0 (the null hypothesis), while the alternative hypothesis is denoted as H1 (the alternative hypothesis).
- When the null hypothesis is true, deciding to reject it constitutes a Type I error; its probability is usually denoted α.
- When the null hypothesis is false, deciding not to reject it constitutes a Type II error; its probability is usually denoted β.
- α + β does not necessarily equal 1.
Typically, only the maximum probability of making a Type I error, α, is constrained; β is not considered. This kind of hypothesis testing is called significance testing, and α is the significance level.
Common α values are 0.01, 0.05, 0.10, etc. In general, depending on the research question, if the cost of making a wrong decision is high, you choose a smaller α to reduce such errors; otherwise, you may choose a larger α.
Alternative Hypothesis
The alternative hypothesis is one of the fundamental concepts in statistics; it includes any proposition about the population distribution that would render the null hypothesis invalid. It is also called the opposite hypothesis or alternative hypothesis.
The alternative hypothesis can replace the null hypothesis.
For example, in evaluating students, we might adopt:
- “Students are below average” — as the null hypothesis
- “Students are above average” — as the alternative hypothesis.
One-Sided Test
One-sided test, also known as one-tailed or one-sided test, in hypothesis testing, uses the area of the tail on one side of the density curve to construct the critical region for testing.
When our hypothesis tests only one side of the value, it is called a one-tailed test.
Example:
For the null hypothesis:
“Mean equals k”
We can have alternative hypotheses:
- “Mean less than k”
- “Mean greater than k”
Two-Sided Test
Two-sided test, also known as two-tailed or two-sided test, in hypothesis testing, uses the areas in both tails of the distribution to construct the critical region.
When our test concerns both sides of the mean:
Example:
For the null hypothesis:
“Mean equals k”
We can have alternative hypotheses:
“Mean not equal to k”
In this case, both sides (less than or greater than k) are checked.
Alpha Value
The alpha value is the significance level.
The significance level is the probability of committing an error when the population parameter falls within a certain interval, denoted by α.
Data must be sufficiently close to the extremes to reject the null hypothesis.
Usually 0.01, 0.05, or 0.1.
P-value
The P-value indicates how extreme the observed data are.
Compare the P-value with alpha to determine statistical significance.
If the p value <= alpha, we reject the null hypothesis and say the data are statistically significant; otherwise, we fail to reject the null.
T Test
The T-test is used to determine whether there is a significant difference between the means of two variables and whether they come from the same distribution.
This is a two-sided test.
The function ttest_ind() takes two samples of the same size and returns a tuple of the t-statistic and p-value.
# Find whether values v1 and v2 come from the same distribution:import numpy as npfrom scipy.stats import ttest_ind
v1 = np.random.normal(size=100)v2 = np.random.normal(size=100)
res = ttest_ind(v1, v2)
print(res)
# If you only want the p-valueres = ttest_ind(v1, v2).pvalueprint(res)KS Test
The KS test checks whether a given value conforms to a distribution.
The function takes two arguments: the test values and the CDF.
CDF stands for Cumulative Distribution Function, also called the distribution function.
CDF can be a string or a callable function that returns probabilities.
It can be used for one-sided or two-sided tests.
By default, it is a two-sided test. We can pass a string for the alternative as one of two-sided, less, or greater.
# Check whether a given value conforms to a normal distribution:import numpy as npfrom scipy.stats import kstest
v = np.random.normal(size=100)
res = kstest(v, 'norm')
print(res)Descriptive Statistics
Using describe() you can view information about an array, including:
- nobs — number of observations
- minmax — minimum and maximum
- mean — arithmetic mean
- variance — variance
- skewness — skewness
- kurtosis — kurtosis
# Display descriptive statistics for an array:import numpy as npfrom scipy.stats import describe
v = np.random.normal(size=100)res = describe(v)
print(res)Normality Test (Skewness and Kurtosis)
A normality test assesses whether observed data come from a normal distribution; it is an important special case of a goodness-of-fit test in statistics.
Normality tests are based on skewness and kurtosis.
The normaltest() function returns the p-value for the null hypothesis:
“x comes from a normal distribution”
Skewness
A measure of the symmetry of the data.
For a normal distribution, it is 0.
If negative, the data are skewed to the left.
If positive, the data are skewed to the right.
Kurtosis
A measure of whether the data are heavy-tailed or light-tailed relative to a normal distribution.
Positive kurtosis means heavy tails.
Negative kurtosis means light tails.
# Find the skewness and kurtosis of values in an array:import numpy as npfrom scipy.stats import skew, kurtosisfrom scipy.stats import normaltest
v = np.random.normal(size=100)
print(skew(v))print(kurtosis(v))
# Check whether the data come from a normal distribution:print(normaltest(v))SciPy
紹介
SciPy はオープンソースの Python アルゴリズムライブラリおよび数学ツールキットです。
SciPy は NumPy を基盤とした科学計算ライブラリで、数学、科学、工学などの分野で、いくつかの高次抽象や物理モデルを扱う際に SciPy を利用します。
SciPy に含まれるモジュールには、最適化、線形代数、積分、補間、特殊関数、高速フーリエ変換、信号処理と画像処理、常微分方程式の解法、そして科学と工学で一般的に用いられる他の計算が含まれます。
アプリケーション
SciPy は数学、科学、工学の分野でよく使われるソフトウェアパッケージで、最適化、線形代数、積分、補間、回帰、特殊関数、高速フーリエ変換、信号処理、画像処理、常微分方程式の解法器などを扱うことができます。
SciPy に含まれるモジュールには、最適化、線形代数、積分、補間、特殊関数、高速フーリエ変換、信号処理と画像処理、常微分方程式の解法、そして科学と工学で一般的に用いられる計算が含まれます。
NumPy と SciPy の協働は多くの問題を効率的に解決でき、天文学、生物学、気象学と気候科学、材料科学などの複数の学問分野で広く応用されています。
インストール
python3 -m pip install -U pippython3 -m pip install -U scipyインストールの検証:
import scipy
print(scipy.__version__)モジュール一覧
以下は SciPy のよく使われるモジュールと公式 API のアドレスです:
| モジュール名 | 機能 | 参考ドキュメント |
|---|---|---|
| scipy.cluster | ベクトル量子化 | cluster API |
| scipy.constants | 数学定数 | constants API |
| scipy.fft | 高速フーリエ変換 | fft API |
| scipy.integrate | 積分 | integrate API |
| scipy.interpolate | 補間 | interpolate API |
| scipy.io | データ入出力 | io API |
| scipy.linalg | 線形代数 | linalg API |
| scipy.misc | 画像処理 | misc API |
| scipy.ndimage | N 次元画像 | ndimage API |
| scipy.odr | 正交距離回帰 | odr API |
| scipy.optimize | 最適化アルゴリズム | optimize API |
| scipy.signal | 信号処理 | signal API |
| scipy.sparse | 疎行列 | sparse API |
| scipy.spatial | 空間データ構造とアルゴリズム | spatial API |
| scipy.special | 特殊数学関数 | special API |
| scipy.stats | 統計関数 | stats.mstats API |
公式ドキュメントの追加内容は以下をご参照ください:https://docs.scipy.org/doc/scipy/reference/
SciPy 定数モジュール
SciPy の定数モジュール constants は多くの組込み数学定数を提供します。
円周率は数学定数で、円の周長と直径の比率です。近似値は約 3.14159、一般に記号 π で表されます。
以下に円周率を出力します:
from scipy import constants
print(constants.pi)以下に黄金比を出力します:
from scipy import constants
print(constants.golden)dir() 関数を使用して constants モジュールに含まれる定数を確認できます:
from scipy import constants
print(dir(constants))単位の型
定数モジュールには以下の種類の単位が含まれています:
-
SI 単位系(国際単位系)。この系の接頭語は英語で SI prefix と呼ばれ、単位の倍率や分数を表します。現在 20 個の接頭語があり、ほとんどが千の整数倍です。 (centi は 0.01 を返します):
from scipy import constantsprint(constants.yotta) #1e+24print(constants.zetta) #1e+21print(constants.exa) #1e+18print(constants.peta) #1000000000000000.0print(constants.tera) #1000000000000.0print(constants.giga) #1000000000.0print(constants.mega) #1000000.0print(constants.kilo) #1000.0print(constants.hecto) #100.0print(constants.deka) #10.0print(constants.deci) #0.1print(constants.centi) #0.01print(constants.milli) #0.001print(constants.micro) #1e-06print(constants.nano) #1e-09print(constants.pico) #1e-12print(constants.femto) #1e-15print(constants.atto) #1e-18print(constants.zepto) #1e-21 -
2進法、バイト単位 返されるバイト単位 (kibi は 1024)。
from scipy import constantsprint(constants.kibi) #1024print(constants.mebi) #1048576print(constants.gibi) #1073741824print(constants.tebi) #1099511627776print(constants.pebi) #1125899906842624print(constants.exbi) #1152921504606846976print(constants.zebi) #1180591620717411303424print(constants.yobi) #1208925819614629174706176 -
質量単位 キログラムの単位を返します。(gram は 0.001 を返します)。
from scipy import constantsprint(constants.gram) #0.001print(constants.metric_ton) #1000.0print(constants.grain) #6.479891e-05print(constants.lb) #0.45359236999999997print(constants.pound) #0.45359236999999997print(constants.oz) #0.028349523124999998print(constants.ounce) #0.028349523124999998print(constants.stone) #6.3502931799999995print(constants.long_ton) #1016.0469088print(constants.short_ton) #907.1847399999999print(constants.troy_ounce) #0.031103476799999998print(constants.troy_pound) #0.37324172159999996print(constants.carat) #0.0002print(constants.atomic_mass) #1.66053904e-27print(constants.m_u) #1.66053904e-27print(constants.u) #1.66053904e-27 -
角度換算 弧度を返します(degree は 0.017453292519943295)。
from scipy import constantsprint(constants.degree) #0.017453292519943295print(constants.arcmin) #0.0002908882086657216print(constants.arcminute) #0.0002908882086657216print(constants.arcsec) #4.84813681109536e-06print(constants.arcsecond) #4.84813681109536e-06 -
時間単位 秒を返します(hour は 3600.0)。
from scipy import constantsprint(constants.minute) #60.0print(constants.hour) #3600.0print(constants.day) #86400.0print(constants.week) #604800.0print(constants.year) #31536000.0print(constants.Julian_year) #31557600.0 -
長さの単位 メートル数を返します(nautical_mile は 1852.0)。
from scipy import constantsprint(constants.inch) #0.0254print(constants.foot) #0.30479999999999996print(constants.yard) #0.9143999999999999print(constants.mile) #1609.3439999999998print(constants.mil) #2.5399999999999997e-05print(constants.pt) #0.00035277777777777776print(constants.point) #0.00035277777777777776print(constants.survey_foot) #0.3048006096012192print(constants.survey_mile) #1609.3472186944373print(constants.nautical_mile) #1852.0print(constants.fermi) #1e-15print(constants.angstrom) #1e-10print(constants.micron) #1e-06print(constants.au) #149597870691.0print(constants.astronomical_unit) #149597870691.0print(constants.light_year) #9460730472580800.0print(constants.parsec) #3.0856775813057292e+16 -
圧力の単位 パスカルの SI 単位の圧力を返します。(psi は 6894.757293168361)。
from scipy import constantsprint(constants.atm) #101325.0print(constants.atmosphere) #101325.0print(constants.bar) #100000.0print(constants.torr) #133.32236842105263print(constants.mmHg) #133.32236842105263print(constants.psi) #6894.757293168361 -
面積の単位 平方メートルを返します。平方メートルは面積の SI 単位で、1m x 1m の正方形の面積に相当します。(hectare は 10000.0)。
from scipy import constantsprint(constants.hectare) #10000.0print(constants.acre) #4046.8564223999992 -
体積の単位
体積を立方メートルで返します。体積は 1 立方メートルが、長さ・幅・高さがすべて 1 メートルの立方体の体積に相当します。1 公秤や 1 度水の体積とも等しいです。(liter は 0.001 を返します)。
from scipy import constantsprint(constants.liter) #0.001print(constants.litre) #0.001print(constants.gallon) #0.0037854117839999997print(constants.gallon_US) #0.0037854117839999997print(constants.gallon_imp) #0.00454609print(constants.fluid_ounce) #2.9573529562499998e-05print(constants.fluid_ounce_US) #2.9573529562499998e-05print(constants.fluid_ounce_imp) #2.84130625e-05print(constants.barrel) #0.15898729492799998print(constants.bbl) #0.15898729492799998 -
速度の単位 毎秒あたりのメートルを返します。(speed_of_sound は 340.5)。
from scipy import constantsprint(constants.kmh) #0.2777777777777778print(constants.mph) #0.44703999999999994print(constants.mach) #340.5print(constants.speed_of_sound) #340.5print(constants.knot) #0.5144444444444445 -
温度の単位 何 Kelvin かを返します。(zero_Celsius は 273.15)。
from scipy import constantsprint(constants.zero_Celsius) #273.15print(constants.degree_Fahrenheit) #0.5555555555555556 -
エネルギーの単位 焦耳(J)を返します。焦耳は国際単位系におけるエネルギー、仕事、熱量の導出単位です。(calorie は 4.184 を返します)。
from scipy import constantsprint(constants.calorie) #4.184 -
力の単位 ワット(W)は国際単位系の力の単位です。1 ワットは 1 ジュール/秒(1 J/s)で、毎秒変換・使用・散逸するエネルギーの速さを表します。(horsepower は 745.6998715822701 を返します)。
from scipy import constantsprint(constants.hp) #745.6998715822701print(constants.horsepower) #745.6998715822701 -
力学の単位 ニュートン(N)は力の公制単位で、質量の単位である kg を基準とした力です。エイサック・ニュートンにちなんで名付けられています。。(kilogram_force は 9.80665)。
from scipy import constantsprint(constants.dyn) #1e-05print(constants.dyne) #1e-05print(constants.lbf) #4.4482216152605print(constants.pound_force) #4.4482216152605print(constants.kgf) #9.80665print(constants.kilogram_force) #9.80665
SciPy 最適化
SciPy の optimize モジュールは一般的な最適化アルゴリズム関数を提供します。これらの関数を直接呼び出して、最適化問題を解決します。例えば、関数の最小値や方程式の根を見つけるといったことが可能です。
方程式の根を求める
NumPy は多項式や線形方程式の根を見つけることはできますが、非線形方程式の根を見つけることはできません。例えば:
x + cos(x)
このため SciPy の optimze.root 関数を使用します。この関数は2つのパラメータを必要とします。
- fun - 方程式の関数を表します。
- x0 - 根の初期推定値。
この関数は解についての情報を含むオブジェクトを返します。
from scipy.optimize import rootfrom math import cos
def eqn(x): return x + cos(x)
myroot = root(eqn, 0)
print(myroot.x)# 追加情報を確認#print(myroot)関数の最小化
関数は曲線を表し、曲線には極大点と極小点があります。
- 極大点は最大値。
- 極小点は最小値。
曲線全体の最高点をグローバル最大値、残りをローカル最大値と呼びます。 曲線の最低点をグローバル最小値、残りをローカル最小値と呼びます。
関数を最小化するには scipy.optimize.minimize() を使用します。
minimize() は次のパラメータを受け取ります:
-
fun - 最適化する関数
-
x0 - 初期推定値
-
method - 使用する手法名。値は:‘CG’、‘BFGS’、‘Newton-CG’、‘L-BFGS-B’、‘TNC’、‘COBYLA’、‘SLSQP’。
-
callback - 各最適化ステップ後に呼び出される関数。
-
options - その他のパラメータを定義する辞書:
{"disp": boolean - 出力の詳細を表示"gtol": number - 誤差の許容範囲}
を BFGS で最小化する関数:
from scipy.optimize import minimize
def eqn(x): return x**2 + x + 2
mymin = minimize(eqn, 0, method='BFGS')
print(mymin)SciPy 疎行列
疎行列(英語:sparse matrix)とは、数値解析においてほとんどの要素が 0 である行列のことを指します。逆に、ほとんどの要素が非ゼロである場合、その行列は密な(Dense) です。
科学と工学の分野で線形モデルを解く際には、大規模な疎行列が頻繁に現れます。
上記の疎行列は 9 個の非零要素を含み、他に 26 個のゼロ要素を含みます。その疎密度は 74%、密度は 26% です。
SciPy の scipy.sparse モジュールは疎行列の処理を提供します。
主に以下の2種類の疎行列を使用します:
- CSC - 圧縮疎列(Compressed Sparse Column)、列方向に圧縮。
- CSR - 圧縮疎行(Compressed Sparse Row)、行方向に圧縮。
本章では主に CSR 行列を使用します。
CSR 行列
scipy.sparse.csr_matrix() 関数に配列を渡すことで CSR 行列を作成できます。
# CSR 行列を作成します。import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([0, 0, 0, 0, 0, 1, 1, 0, 2])print(csr_matrix(arr))- data データとして格納されているデータを確認するには data 属性を使います(0 要素は含まれません):
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).data)- count_nonzero() 非 0 要素の総数を計算するには count_nonzero() を使用します:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
print(csr_matrix(arr).count_nonzero())- eliminate_zeros() 行列から 0 要素を削除するには eliminate_zeros() を使用します:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.eliminate_zeros()
print(mat)- sum_duplicates() 重複アイテムを削除するには sum_duplicates() を使用します:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
mat = csr_matrix(arr)mat.sum_duplicates()
print(mat)- tocsc() CSR を CSC に変換するには tocsc() を使用します:
import numpy as npfrom scipy.sparse import csr_matrix
arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]])
newarr = csr_matrix(arr).tocsc()
print(newarr)SciPy グラフ構造
グラフ構造はアルゴリズムの中で最も強力なフレームワークのひとつです。
グラフは、ノードとエッジの集合であり、ノードは対象を表す頂点、エッジは対象間の接続を表します。
SciPy は scipy.sparse.csgraph モジュールを提供しており、グラフ構造を扱います。
隣接行列
隣接行列(Adjacency Matrix)は、頂点間の隣接関係を表す行列です。
隣接行列の論理構造は 2 つの集合 V と E から成り、V は頂点、E は辺で、辺には時として重みがあり、頂点間の結びつきの強さを表します。
グラフ中のすべての頂点データを 1 次元配列に格納し、頂点間の関係(辺または弧)を 2 次元配列に格納します。この 2 次元配列を隣接行列と呼びます。
隣接行列は、有向グラフの隣接行列と無向グラフの隣接行列に分けられます。
無向グラフは双方向の関係で、辺には向きがありません。
有向グラフの辺には向きがあり、単方向の関係です。
連結成分
すべての連結成分を確認するには connected_components() メソッドを使用します。
import numpy as npfrom scipy.sparse.csgraph import connected_componentsfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(connected_components(newarr))Dijkstra — 最短経路アルゴリズム
Dijkstra(ディジェストラ)最短経路アルゴリズムは、あるノードから他のすべてのノードへの最短経路を計算します。
SciPy は dijkstra() メソッドを使って、ある要素から他の要素への最短経路を計算します。dijkstra() メソッドは以下のパラメータを設定できます:
- return_predecessors: ブール値。True に設定するとすべての経路をたどります。すべての経路をたどりたくない場合は False に設定します。
- indices: 要素のインデックス。該当要素のすべての経路を返します。
- limit: 経路の最大重み。
# 要素 1 から 2 への最短経路を探す:import numpy as npfrom scipy.sparse.csgraph import dijkstrafrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(dijkstra(newarr, return_predecessors=True, indices=0))Floyd-Warshall — フロイド・ワーシャル法
フロイド・ワーシャル法は、任意の 2 点間の最短経路を解くアルゴリズムです。
SciPy は floyd_warshall() メソッドを使って、全ての要素対の最短経路を求めます。
# 全要素対間の最短経路径を求める:import numpy as npfrom scipy.sparse.csgraph import floyd_warshallfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(floyd_warshall(newarr, return_predecessors=True))Bellman-Ford — ベルマン-フォード法
ベルマン-フォード法は、任意の 2 点間の最短経路を解くアルゴリズムです。
SciPy は bellman_ford() メソッドを使って、全要素対の最短経路を探します。負の辺を含む有向グラフをはじめ、任意のグラフで通常使用できます。
# 負の重みの辺を持つグラフで、要素 1 から要素 2 への最短経路を探索:import numpy as npfrom scipy.sparse.csgraph import bellman_fordfrom scipy.sparse import csr_matrix
arr = np.array([ [0, -1, 2], [1, 0, 0], [2, 0, 0]])
newarr = csr_matrix(arr)
print(bellman_ford(newarr, return_predecessors=True, indices=0))深さ優先順序
depth_first_order() メソッドは、あるノードからの深さ優先探索の順序を返します。
以下のパラメータを受け取ることができます:
- 图
- 图を開始する要素
# 隣接行列を与え、深さ優先探索の順序を返す:import numpy as npfrom scipy.sparse.csgraph import depth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(depth_first_order(newarr, 1))幅優先順序
breadth_first_order() メソッドは、あるノードからの幅優先探索の順序を返します。
以下のパラメータを受け取ることができます:
- 图
- 图を開始する要素
# 隣接行列を与え、幅優先探索の順序を返す:import numpy as npfrom scipy.sparse.csgraph import breadth_first_orderfrom scipy.sparse import csr_matrix
arr = np.array([ [0, 1, 0, 1], [1, 1, 1, 1], [2, 1, 1, 0], [0, 1, 0, 1]])
newarr = csr_matrix(arr)
print(breadth_first_order(newarr, 1))SciPy 空間データ
空間データは幾何データとも呼ばれ、物体の位置、形、サイズ分布などの情報を表すために用いられます。たとえば座標上的な点。
SciPy は scipy.spatial モジュールを通じて空間データを処理します。例えば、ある点が境界内にあるかを判定したり、与えられた点の周囲の最近傍点を計算したり、指定距離内のすべての点を求めたりします。
三角測量
三角測量は、三角法と幾何学の分野で、ターゲット点と固定基準線の既知端点の角度を測定することで、ターゲットまでの距離を測る方法です。
多角形の三角測量は、多角形をいくつかの三角形に分割し、これらの三角形を用いて多角形の面積を計算します。
トポロジーの既知の事実として、どんな曲面にも三角形分割が存在します。
曲面上に三角形分割があると仮定すると、すべての三角形の頂点の総数を p(公共頂点は1つと見なす)、辺の数を a、三角形の数を n とすると e = p - a + n が曲面のトポロジ的不変量です。換言すれば、どんな分割をしても e は同じ値になります。e はオイラー示性数と呼ばれます。
一連の点に対する三角形分割点法は Delaunay() 三角剖分です。
# 与えられた点から三角形を作成する:import numpy as npfrom scipy.spatial import Delaunayimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1]])
simplices = Delaunay(points).simplices # 三角形の頂点のインデックス
plt.triplot(points[:, 0], points[:, 1], simplices)plt.scatter(points[:, 0], points[:, 1], color='r')
plt.show()凸包
凸包(Convex Hull)は、計算幾何の概念のひとつです。
実数ベクトル空間 V において、集合 X に対して X を含むすべての凸集合の交集を取ったものを X の凸包と呼びます。X の凸包は、X 内のすべての点の凸結合によって構成できます。
ConvexHull() メソッドを使って凸包を作成できます。
# 与えられた点から凸包を作成:import numpy as npfrom scipy.spatial import ConvexHullimport matplotlib.pyplot as plt
points = np.array([ [2, 4], [3, 4], [3, 0], [2, 2], [4, 1], [1, 2], [5, 0], [3, 1], [1, 2], [0, 2]])
hull = ConvexHull(points)hull_points = hull.simplices
plt.scatter(points[:,0], points[:,1])for simplex in hull_points: plt.plot(points[simplex,0], points[simplex,1], 'k-')
plt.show()KD ツリー
kd-tree(k 次元空間木の略)は、k 次元空間内の実点を格納して高速に検索するための木構造です。多次元空間におけるキー値検索(範囲検索および最近傍探索)に主に用いられます。
KDTree() メソッドは KDTree オブジェクトを返します。
query() メソッドは最近傍距離と最近傍の位置を返します。
# (1,1) に対する最近傍距離を求めるfrom scipy.spatial import KDTree
points = [(1, -1), (2, 3), (-2, 3), (2, -3)]
kdtree = KDTree(points)
res = kdtree.query((1, 1))
print(res)距離行列
距離行列とは、各要素が点間の距離である行列(2次元配列)です。したがって、N 個の欧幾里得空間上の点が与えられた場合、その距離行列は要素(点)間の距離を値とする N×N の対称行列となり、隣接行列の概念と似ています。ただし後者は要素間にエッジがあるかどうかのみを示し、距離情報は含みません。そのため、距離行列は隣接行列の重み付き形式と考えることができます。
例えば、以下の 2 次元点 a から f を分析します。ここでは点間のユークリッド距離を距離の尺度として用います。
ユークリッド距離
ユークリッド距離またはユークリッド距離量は、ユークリッド空間における点と点の「通常の」直線距離を指します。これによりユークリッド空間は距離空間となり、対応するノルムはユークリッドノルムと呼ばれます。古い文献ではピタゴラス距離と呼ばれることもあります。
ユークリッド距離(Euclidean metric)(別名 Euclidean distance)は、m 次元空間における2点間の実距離、あるいはベクトルの自然長(原点からその点への距離)を指す、よく使われる距離の定義です。2 次元および 3 次元空間では、ユークリッド距離は2点間の実際の距離です。
from scipy.spatial.distance import euclidean
p1 = (1, 0)p2 = (10, 2)
res = euclidean(p1, p2)
print(res)マンハッタン距離
マンハッタン幾何学、または Manhattan 距離は、19世紀のヘルマン・闵可夫斯基により導入された、幾何計量空間における幾何学用語です。標準座標系上の2点の絶対的な軸間距離の総和を表します。
マンハッタン距離は上下左右の4方向のみで移動可能で、2点間の最短距離はこの距離です。
マンハッタン距離とユークリッド距離の比較:赤、青、黄の線はすべてのマンハッタン距離が同じ長さ(12)になることを示し、緑の線はユークリッド距離が 6×√2 ≈ 8.48 であることを示します。
コサイン距離
コサイン距離は、コサイン類似度とも呼ばれ、2 つのベクトルのなす角のコサイン値を測定して、それらの類似性を表します。
0 度のコサイン値は 1 で、他の角度のコサイン値は 1 以下で、最小値は -1 です。
# A と B の点のコサイン距離を計算する:from scipy.spatial.distance import cosine
p1 = (1, 0)p2 = (10, 2)
res = cosine(p1, p2)
print(res)ハミング距離
情報理論において、等長の2つの文字列の間のハミング距離(Hamming distance)は、対応する位置で異なる文字の数です。言い換えれば、ある文字列を別の文字列へ変換するのに置換する文字の数です。
ハミング重量は、同じ長さのゼロ文字列に対するその文字列のハミング距離で、つまり文字列中の非ゼロ要素の数です。2進文字列の場合、1 の数です。したがって 11101 のハミング重量は 4 です。
- 1011101 と 1001001 のハミング距離は 2。
- 2143896 と 2233796 のハミング距離は 3。
- “toned” と “roses” のハミング距離は 3。
# 2 点間のハミング距離を計算する:from scipy.spatial.distance import hamming
p1 = (True, False, True)p2 = (False, True, True)
res = hamming(p1, p2)
print(res)SciPy Matlab 配列
NumPy は Python が読み取れる形式のデータ保存を提供します。
SciPy は MATLAB との相互作用を提供します。
SciPy の scipy.io モジュールは MATLAB の配列を扱う多くの関数を提供します。
Matlab 形式でデータをエクスポート
savemat() メソッドは Matlab 形式のデータをエクスポートできます。 このメソッドの引数は:
- filename - 保存するデータのファイル名。
- mdict - データを含む辞書。
- do_compression - 真偽値。結果データを圧縮するかどうかを指定します。デフォルトは False。
# 配列を変数 "vec" として mat ファイルへエクスポートする:from scipy import ioimport numpy as np
arr = np.arange(10)
io.savemat('arr.mat', {"vec": arr})注意:上記のコードはあなたのコンピュータ上に “arr.mat” というファイルを保存します。
Matlab 形式データのインポート
loadmat() メソッドは Matlab 形式データを読み込みます。
このメソッドの引数:
- filename - 保存データのファイル名。
結果は構造化配列で、キーは変数名、対応する値は変数の値です。
# mat ファイルから配列をインポート:from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# エクスポートio.savemat('arr.mat', {"vec": arr})
# インポートmydata = io.loadmat('arr.mat')
print(mydata)
# 変数名 "vec" だけ matlab データの配列を表示:print(mydata['vec'])結果から、最初は1次元の配列でしたが、取り出す際に次元が1つ追加され、2次元配列になっています。
この問題を解決するには squeeze_me=True の追加パラメータを渡します:
from scipy import ioimport numpy as np
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,])
# エクスポートio.savemat('arr.mat', {"vec": arr})
# インポートmydata = io.loadmat('arr.mat', squeeze_me=True)
print(mydata['vec'])SciPy 插值
插值とは?
数学の数値解析分野において、插值(インターポレーション)は、既知の離散データ点を用いて、範囲内の新しいデータ点を推定するプロセスまたは手法です。
簡単に言えば、与えられた点の間で点を生成する方法です。
例えば、2 点 1 と 2 に対して、補間をして点 1.33 および 1.66 を見つけることができます。
插值には多くの用途があり、機械学習ではデータ欠損を扱うことがよくあり、補間はこれらの値を埋めるのに使われます。
この埋め込みの方法は「補間」と呼ばれます。
補間の他にも、データ集合の離散点を平滑化する場面で頻繁に使われます。
SciPy での補間の実装
SciPy は補間を扱う scipy.interpolate モジュールを提供します。
一次元補間
一次元データの補間演算は interp1d() メソッドで完了します。
このメソッドは x 点と y 点の 2 つのパラメータを受け取り、戻り値は呼び出し可能な関数です。この関数を新しい x で呼び出すと対応する y が返されます。y = f(x)。
# 与えられた xs と ys に対して、2.1、2.2... から 2.9 までの補間を行う:from scipy.interpolate import interp1dimport numpy as np
xs = np.arange(10)ys = 2*xs + 1
interp_func = interp1d(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)単変量補間
一次補間では点は単一の曲線に対して適合しますが、スプライン補間では、点は多項式分割法で定義された関数に対して適合します。
単変量補間には UnivariateSpline() 関数を使用します。この関数は xs と ys を受け取り、新しい xs を呼び出すことができる関数を生成します。
分割関数とは、自変数 x の異なる値の範囲に対して、異なる解析式を持つ関数のことです。
# 非線形点の 2.1、2.2...2.9 の単変量スプライン補間を見つける:from scipy.interpolate import UnivariateSplineimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = UnivariateSpline(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)放射状基底関数補間
放射状基底関数とは、固定の参照点に対して定義される関数です。
曲面補間では一般に放射状基底関数補間を使用します。
# Rbf() 関数は xs と ys を引数として受け取り、呼び出し可能な関数を生成しますfrom scipy.interpolate import Rbfimport numpy as np
xs = np.arange(10)ys = xs**2 + np.sin(xs) + 1
interp_func = Rbf(xs, ys)
newarr = interp_func(np.arange(2.1, 3, 0.1))
print(newarr)SciPy 有意性検定
有意性検定(significance test)は、事前に母集団(確率変数)のパラメータまたは母集団分布の形について仮説を立て、標本情報を用いてその仮説(対立仮説)が妥当かどうかを判断する、つまり母集団の実情と元の仮説との間に顕著な差があるかを判断する検定です。言い換えれば、有意性検定は、標本と母集団に対する仮説との間の差が偶然の変動によるものなのか、仮説と母集団の実情の不一致によるものなのかを判断する検定です。 有意性検定は、母集団に対する仮説を検定するもので、その原理は「極めて低い確率の事象は現実には起こり得ない」という原理に基づき、仮説を受け入れたり棄却したりします。
有意性検定は、処理群と対照群または2 つの異なる処理間の効果に差があるかどうか、そしてこの差が統計的に有意かどうかを判断するために用いられます。
SciPy は scipy.stats モジュールを提供しており、SciPy の有意性検定を実行する機能を提供します。
統計仮説
統計仮説は、1つまたは複数のランダム変数の未知の分布についての仮説です。確率分布の形は既知で、分布の1つまたは数個の未知パラメータのみを含む統計仮説を「パラメータ仮説」と呼び、検定するべき仮説を仮説検定といいます。
帰無仮説
帰無仮説(null hypothesis)は、統計学用語で、検定を行う際に事前に設定する仮説のことです。帰無仮説が成立する場合、統計量は既知の分布に従うはずです。
統計量の計算値が棄却域に入ると、小さな確率のイベントが発生したことになるため、帰无仮説を棄却します。
検定すべき仮説を H0、対立仮説を H1 と表記することが多いです。
- 帰無仮説が真である場合、第一種の誤りを起こす確率を α とします。
- 帰無仮説が偽である場合、第二種の誤りを起こす確率を β とします。
- α + β が必ずしも 1 にはなりません。
通常は第一種の誤りの最大確率 α のみを設定し、β は考慮しません。こうした検定を有意検定といい、α は有意水準と呼ばれます。
最もよく使われる α の値は 0.01、0.05、0.10 などです。研究の問題によっては、偽陽性の損失が大きい場合は α を小さくします。逆に、偽陰性の損失が大きい場合は α を大きくします。
代替仮説
代替仮説(alternative hypothesis)は、統計学の基本概念のひとつで、元の帰無仮説を却下させるべての命題を含む仮説です。代替仮説は別名、対立仮説、候補仮説とも呼ばれます。
代替仮説は帰無仮説を置き換えることができます。
例えば学生の評価については、次のようにします:
- 「学生は平均水準より劣る」 - 帰無仮説
- 「学生は平均水準より優れる」 - 対立仮説
片側検定
片側検定(one-sided test)は、検定統計量の密度曲線と軸の間の領域の片側尾部の面積を用いて臨界域を構築する検定方法です。
仮説検定で、検定値の一方のみを検討する場合、それを「片側検定」と呼びます。
例:
帰無仮説: 「平均値は k に等しい」
対処仮説:
- 「平均値は小さい」
- 「平均値は大きい」
両側検定
両側検定(two-sided test)は、検定統計量の密度曲線と x 軸で囲まれる領域の左右両端の尾部の面積を用いて臨界域を構築する検定方法です。
検定値が両側にわたる場合。
例:
帰無仮説: 「平均値は k に等しい」
対立仮説:
- 「平均値は k と等しくない」
この場合、平均値が小さい場合も大きい場合も両方をチェックします。
アルファ値
アルファ値は有意水準です。
有意水準は、母集団のパラメータがある区間に落ちる確率を表すもので、α で表します。
データは極端さに近いほど帰無仮説を棄却しやすくなります。
通常は 0.01、0.05、0.1 が用いられます。
p値
p値は、データが実際にどれだけ極端かを表します。
p値とアルファ値を比較して統計的有意性を判断します。
もし p 値が ≤ α であれば、帰無仮説を棄却し、データは統計的に有意であると言います。そうでなければ帰無仮説を受け入れます。
t 検定(T-Test)
t 検定は、2 つの変数の平均値の間に顕著な差が存在するかどうかを判断し、それらが同じ分布に属するかどうかを判定します。これは両側検定です。
ttest_ind() は、同じ大きさの 2 つのサンプルを取得し、t 統計量と p 値のタプルを生成します。
# v1 と v2 が同じ分布から来ているかを調べる:import numpy as npfrom scipy.stats import ttest_ind
v1 = np.random.normal(size=100)v2 = np.random.normal(size=100)
res = ttest_ind(v1, v2)
print(res)
# p 値のみを返す場合res = ttest_ind(v1, v2).pvalueprint(res)KS 検定
KS 検定は、データが特定の分布に適合するかを検定します。
この関数は2つの引数を受け取ります;検定値と CDF。
CDF は累積分布関数(Cumulative Distribution Function)で、別名分布関数です。
CDF は文字列でも、確率を返す呼び出し可能な関数でも構いません。
デフォルトでは両側検定です。対となる引数として、片側検定、小さい方、または大きい方のいずれかを表す文字列を渡すことができます。
# 指定された値が正規分布に適合するかを調べる:import numpy as npfrom scipy.stats import kstest
v = np.random.normal(size=100)
res = kstest(v, 'norm')
print(res)データ統計の説明
describe() 関数を使うと、配列の統計情報を確認できます。以下を含みます:
- nobs — 観測回数
- minmax — 最小値と最大値
- mean — 算術平均
- variance — 分散
- skewness — 歪度
- kurtosis — 尖度
# 配列の統計記述を表示:import numpy as npfrom scipy.stats import describe
v = np.random.normal(size=100)res = describe(v)
print(res)正規性検定(歪度と尖度)
観測データを用いて母集団が正規分布に従うかを判断する検定を正規性検定といい、統計的判断において重要な特殊な適合度仮説検定です。
正規性検定は歪度と尖度に基づきます。
normaltest() 関数は帰無仮説の p 値を返します:
「x は正規分布に従う」
歪度
データの対称性の指標です。
正規分布では 0 です。
負の場合、データは左に歪んでいます。
正の場合、データは右に歪んでいます。
尖度
データが重尾か軽尾の正規分布かを測る指標です。
正の尖度は重尾を意味します。
負の尖度は軽尾を意味します。
# 配列の歪度と尖度を求める:import numpy as npfrom scipy.stats import skew, kurtosisfrom scipy.stats import normaltest
v = np.random.normal(size=100)
print(skew(v))print(kurtosis(v))
# データが正規分布に従うかを調べる:print(normaltest(v))部分信息可能已经过时