


















コンピュータシステムはハードウェアとシステムソフトウェアで構成され、アプリケーションを実行するために協力して動作します。
#include<stdio.h>int main(){ printf("hello world! C"); return 0;}hello.cのライフサイクルを追跡する → 作成、実行、出力、終了。
1 情報=ビットとコンテキスト
hello.cはソースプログラムであり、Helloプログラムの出発点、プログラマが作成したテキストファイル—8ビットから成るバイト列で構成されている。
ほとんどはASCII標準を使用します。プログラムはファイル中にバイト列として保存され、各バイトの整数値が1文字に対応します。ASCII文字だけからなるファイルをテキストファイルと呼び、そうでないファイルはバイナリファイルと呼ばれます。
基本的な考え方:システム内のすべての情報はビットの列として表されます。データの文脈によって異なるデータオブジェクトを区別します。数値の機械表現は実際の値とは異なり、真理値の有限近似です。
2 プログラムは他のプログラムによって異なる形式へ翻訳される
高度なC言語—変換—>低級機械語指令—パッケージ化—>実行可能ターゲットプログラム
gcc -o hello hello.c./hello
コンパイルシステム
コンパイルシステム:プリプロセッサ、コンパイラ、アセンブラ、リンカ
-
プリプロセス
プリプロセッサ(cpp)は # で始まる命令に従って原始プログラムを修正し、ヘッダファイルの内容をプログラム本文に直接挿入します。
hello.c—cpp—>hello.i
-
コンパイル
コンパイラ(ccl)は前の.iファイルを .s ファイルへ翻訳し、アセンブリ言語プログラムを含みます。
hello.i—ccl—>hello.s
-
アセンブリ
アセンブラ(as)は .s ファイルをマシン語命令へ翻訳し、再配置可能なターゲットプログラムとして、.o のバイナリファイルに保存します。
hello.s—as—>hello.o
-
リンケージ
リンカ(ld)は現在の .o ファイルとライブラリ関数を呼び出すプリコンパイル済みターゲットファイルを結合し、実行可能なターゲットファイルを得て、システムで実行可能になります。
hello.o+printf.o—ld—>hello
3 コンパイルシステムの利点を理解する
- クエリ性能の最適化
- リンケージ時に発生するエラーの理解
- 安全性の脆弱性を回避する
4 プロセッサが命令を読み取り解釈する
4.1 システムハードウェアの構成
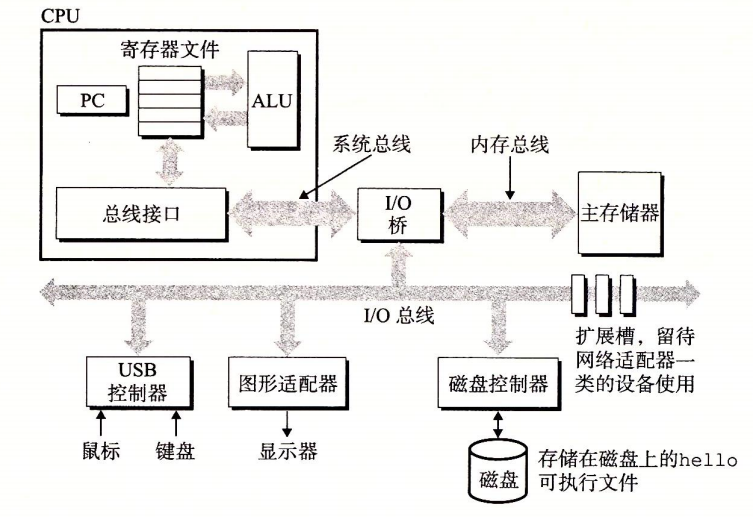
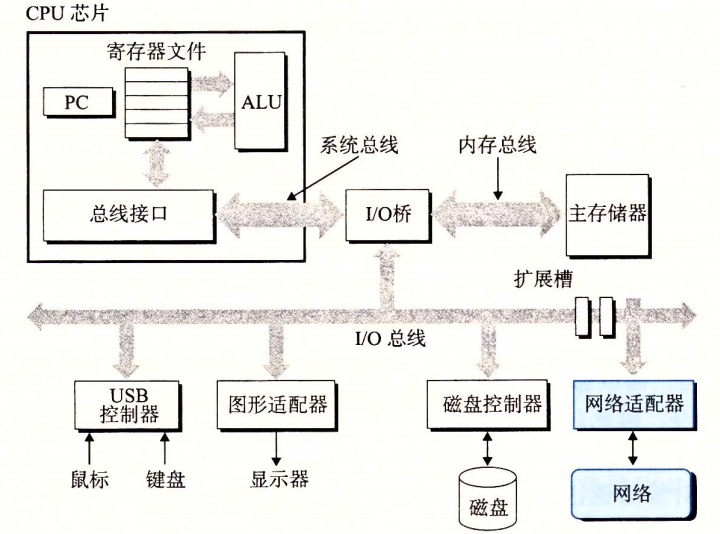
システムのハードウェア構成
-
バス
システムを貫く一連の電子的パイプで、情報をバイト単位で伝送します。固定長のバイトブロック(ワード)を伝送します。ワード内のバイト数はシステムによって異なり、基本的なシステムパラメータとして例として4バイト(32ビット)、8バイト(64ビット)などがあります。
システムバス、メモリバス、I/Oバス
-
I/Oデバイス
システムと外部との連絡を担います。入力のキーボードとマウス、出力のディスプレイ、長期保存のディスクなど。
I/Oデバイスはコントローラまたはアダプタを介してI/Oバスに接続されます。
-
コントローラとアダプタの違い
パッケージ化方式が異なります。
コントローラ:I/Oデバイス自体、またはシステムマザーボード上のチップセット。
アダプタ:マザーボードのスロットに挿さるカード。
-
-
主記憶(メインメモリ)
一時的な記憶装置で、プログラムとプログラムが処理するデータを格納します。
物理的にはダイナミックRAM(DRAM)チップで構成され、論理的には連続したバイト配列で、各バイトのアドレスは一意で、アドレスは0から始まります。
-
プロセッサ
中央処理装置(CPU)は、主記憶に格納された命令を解釈するエンジンです。
コアは1ワード分のストレージ装置で、プログラムカウンタ(PC)と呼ばれ、主記憶中のある機械語命令のアドレスを指します。電源投入後、プロセッサはPCが指す命令を絶えず実行し、PCを更新して次の命令を実行します。
プロセッサは命令操作モデル(ISAにより決定)に従って動作します。モデル内では命令は厳密な順序で実行され、1つの命令を実行するには、PCからメモリへ命令を読み取り、命令のビットを解釈し、命令が指示する単純な操作を実行し、PCを更新して次の指令へ向けます。
上記の単純な操作は多くはなく、それらは主記憶、レジスタファイル(小さな記憶デバイスで、いくつかの単一ワード長のレジスタから成り、それぞれ名前は一意)、 算術/論理演算ユニット(ALU)[新しいデータとアドレス値を計算]を中心に展開します。
- 単純操作
-
ロード
主記憶から1バイトまたは1ワードをレジスタへコピーし、レジスタの元の内容を上書きします。
-
ストア
レジスタから1バイトまたは1ワードを主記憶のある位置へコピーし、その位置の元の内容を上書きします。
-
演算
2つのレジスタの内容をALUへコピーし、ALUがこの2つの数で算術演算を行い、結果を1つのレジスタに格納して、そのレジスタの元の内容を上書きします。
-
ジャンプ
命令自体から1ワードを取り出し、そのバイトをプログラムカウンタ(PC)へコピーして、PCの元の値を上書きします。
-
表面的には、プロセッサはISAの単純実装ですが、実際にはプログラムの実行を加速するために非常に複雑な仕組みを使用しています。したがって、プロセッサのISAとマイクロアーキテクチャを区別します:ISAは各機械コード命令の効果を記述し、マイクロアーキテクチャはプロセッサが実際にどのように実現されているかを記述します。
- 単純操作
4.2 プログラムの実行
手順:
シェルはコマンドを実行し、コマンド入力を待ちます。./helloと入力すると、シェルは文字を1文字ずつレジスタへ読み込み、それをメモリへ格納します。エンターを押すとコマンドが実行されます。helloファイルをロードし、その中のコードとデータをディスクから主記憶へコピーします。
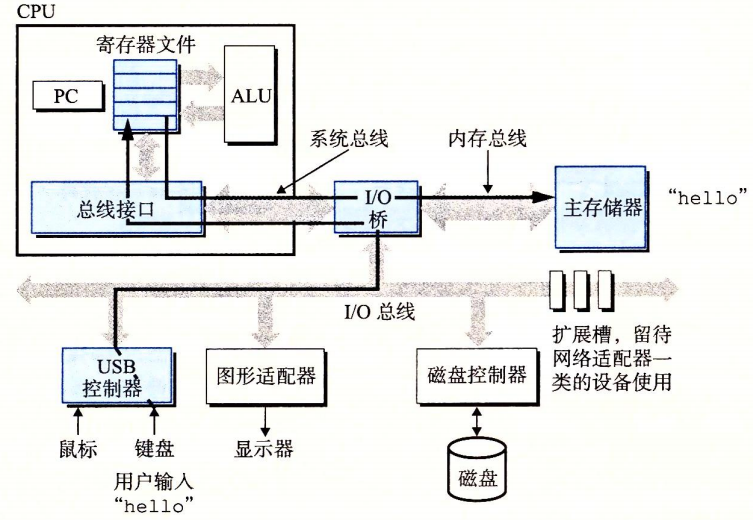
hello コマンドの読み取り
DMA(直接メモリアクセス)を使用して、データはプロセッサを経由せずにディスクから主記憶へ直接転送されます。
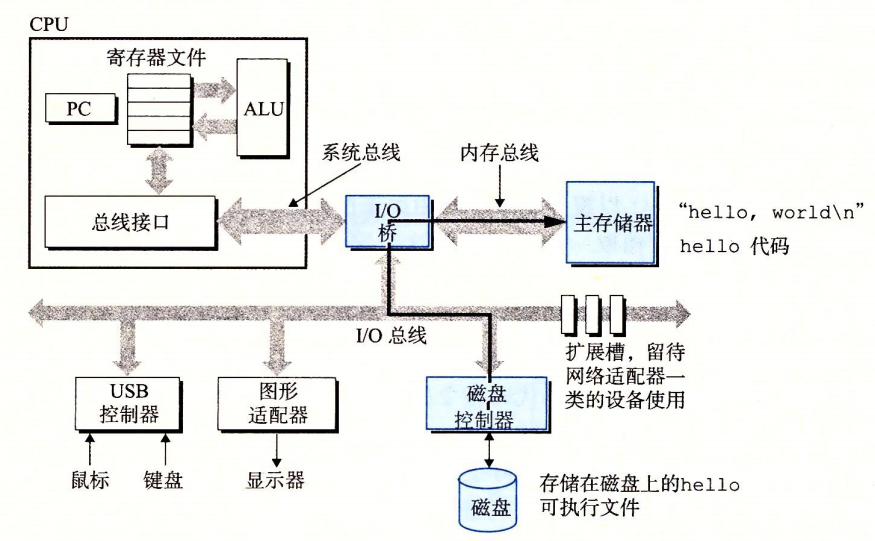
ディスクは実行可能ファイルを主記憶へロードします
次に、helloプログラムのmain内の機械語命令を実行し、‘hello world! C’ という文字列のバイトを主記憶からレジスタへ、そしてレジスタから表示装置へコピーし、最終的に画面に表示されます。
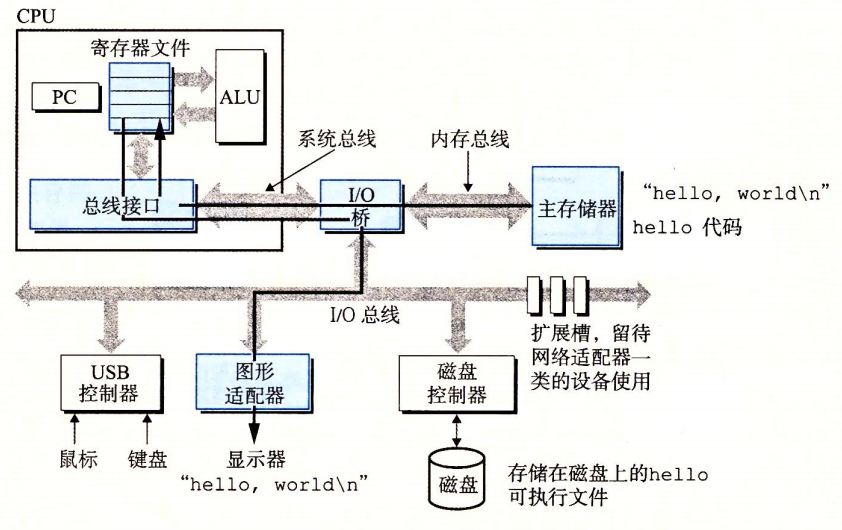
文字列を画面へ出力
5 キャッシュの重要性
上記のとおり、システムは情報の移動に多くの時間を費やします。これらのコピーは、ある程度、プログラムの動作を遅くします。
プロセッサと主記憶の速度差を埋めるため、キャッシュメモリ(cache)を使用します。最近使用される可能性がある情報を格納します。L1キャッシュ、L2キャッシュ…、SRAMハードウェア技術を使用して実装します。キャッシュの局所性原理を利用します:プログラムはデータとコードを頻繁にアクセスする傾向があります。
キャッシュを活用することで、プログラムの性能を1桁向上させることができます。
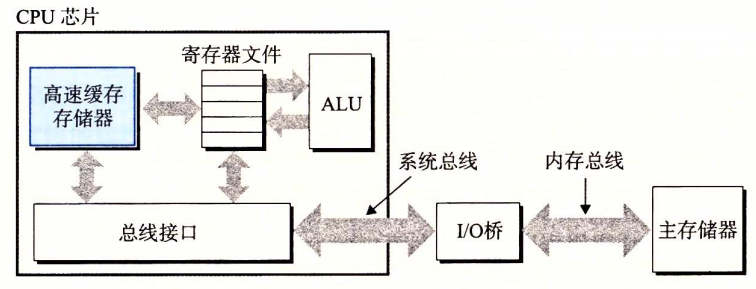
高速缓存存储器 cache
6 保存デバイスの階層構造
メモリ階層構造は、プロセッサと比較的大きくて遅いデバイスとの間に、より小さく高速な記憶装置を挿入する考え方です。
主な考え方は、上一層の記憶を低い層の記憶の高速キャッシュとして使用することです。
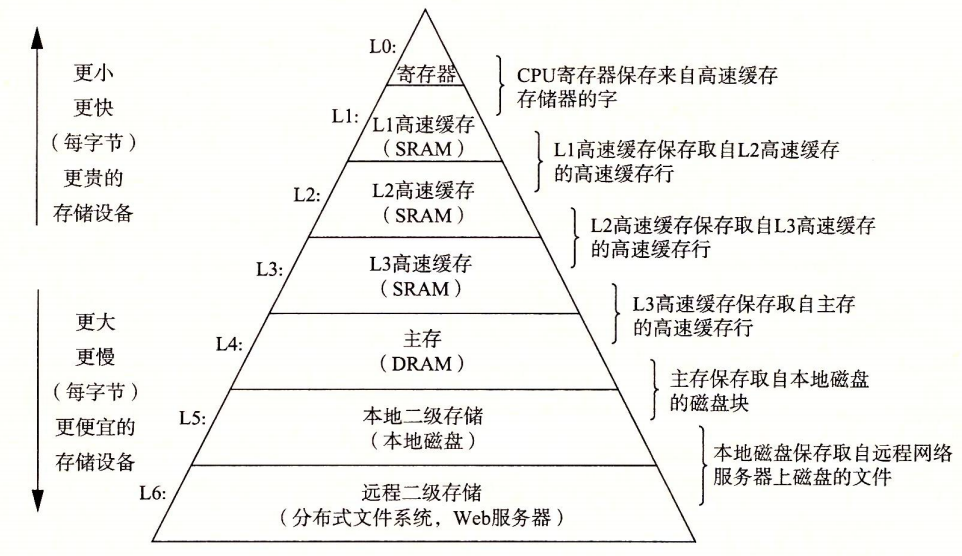
メモリ階層構造
7 オペレーティングシステムがハードウェアを管理する
プログラムは、OSが提供するサービスを通じてハードウェアにアクセスします。すべてのアプリケーションによるハードウェアの操作はOSを通じて行われなければなりません。

コンピュータシステムの階層ビュー
OSは、ハードウェアが制御不能なアプリケーションに乱用されるのを防ぎ、複雑で異なるハードウェアデバイスを制御するための、アプリケーションに対して単純で一貫したメカニズムを提供します。その実現は、いくつかの抽象概念(プロセス、仮想メモリ、ファイル)によって実現されます。
ファイルはI/Oデバイスの抽象、仮想メモリは主記憶とI/Oデバイスの抽象、プロセスは処理系、主記憶、I/Oデバイスの抽象です。
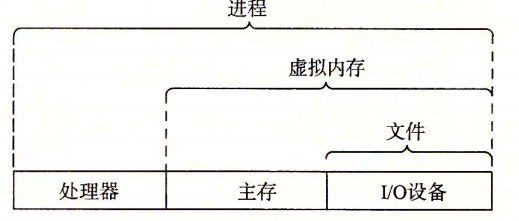
OSが提供する抽象表現
7.1 プロセス
プログラムが実行されると、OSは現在のプログラムが独占的にプロセッサ、主記憶、I/Oデバイスを使用しているという仮想を提供します。その仮想はプロセスを通じて実現されます。
プロセスは、実行中のプログラムをOSが持つ抽象です。1つのシステムには複数のプロセスが同時に実行されることがありますが、それぞれのプロセスはハードウェアを独占しているように見えます。
並行に実行されるとは、1つのプロセスの命令と別のプロセスの命令が交互に実行されることを指します。これは、プロセッサがプロセス間で切り替わることによって実現します。その仕組みはコンテキストスイッチと呼ばれます。
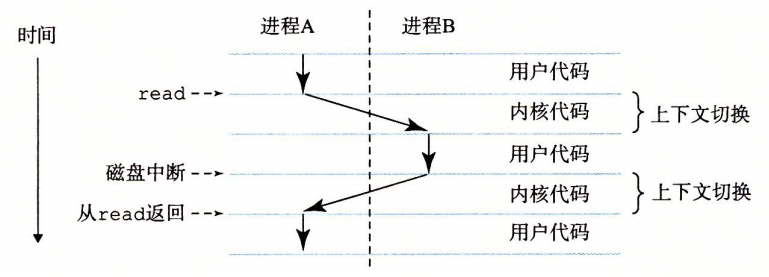
プロセスのコンテキストスイッチ
図のように、プロセスの切り替えはOSのカーネル(kernel)によって管理されます。OSのコードは主記憶に常駐する部分で、全てのプロセスを管理するコードとデータ構造の集合です。アプリケーションがOS機能を必要とするとき、カーネルは特別なシステムコール(system call)命令を実行して制御をカーネルへ渡します。その後、カーネルは要求された操作を実行し、再度アプリケーションへ戻します。
7.2 スレッド
1つのプロセスは、複数の実行単位(スレッド)で構成されることがあり、各スレッドはプロセスのコンテキスト内で動作し、同じコードと全局データを共有します。マルチスレッドはマルチプロセスよりデータ共有が容易なため、スレッドは通常プロセスより効率的です。
7.3 仮想メモリ
仮想メモリは、プロセスに対して独占的に主記憶を使用しているかのような仮想感を提供します。各プロセスが見るメモリは一様で、仮想アドレス空間と呼ばれます。Linuxでは、アドレス空間の最上部の領域がOSのコードとデータの領域で、下部にはユーザープロセスが定義するコードとデータが格納されます。
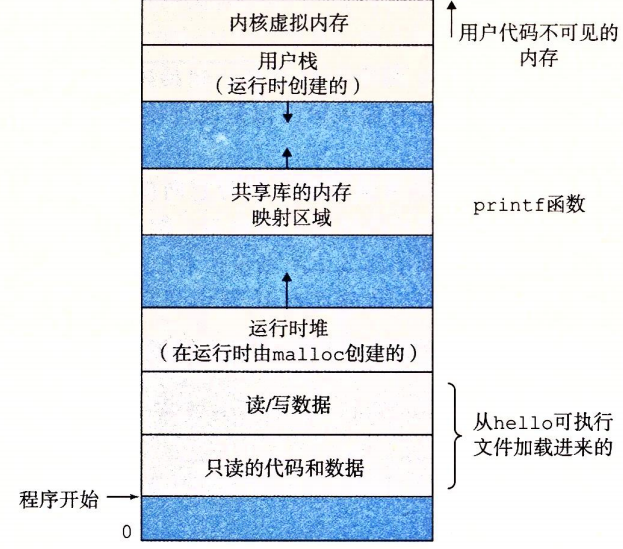
仮想アドレス空間
-
プログラムのコードとデータ
すべてのプロセスにとって、コードは同じ固定アドレスから開始し、その後にCのグローバル変数に対応するデータ領域が続きます。
-
ヒープ
実行時のヒープ。mallocやfreeの呼び出しによって、実行時に動的に拡張・縮小します。
-
共有ライブラリ
C標準ライブラリや数学ライブラリのような共有ライブラリのコードとデータが中間部に格納されます。
-
スタック
ユーザスタックはユーザ仮想メモリの最上部にあり、関数呼び出しを実現するために使用されます。実行時にも動的に拡張・縮小します。関数を呼び出すとスタックは増え、関数が戻るとスタックは縮みます。
-
カーネル仮想メモリ
アドレス空間の最上部に位置します。アプリケーションはその領域の内容を読み書きしたり、カーネルコードが定義する関数を直接呼ぶことは許されず、必ずカーネルを経由して呼び出します。
基本的な考え方は、1つのプロセスの仮想メモリの内容をディスク上に保存し、主記憶をディスクの高速キャッシュとして使用することです。
7.4 ファイル
ファイルはバイト列であり、各I/Oデバイスはファイルとして見ることができます。Linuxシステムの入出力は、Unix I/Oと呼ばれる一連のシステム関数呼び出しを用いてファイルを読み書きすることで実現されます。
ファイルはアプリケーションに対して、さまざまなI/Oデバイスを一様に扱うビューを提供します。
8 システム間ネットワーク通信
1台のシステムから見ると、ネットワークはI/Oデバイスとして扱えます。システムは他のマシンから送られてくるデータを読み取り、それを自分の主記憶へコピーします。
ネットワークデバイスI/O
helloプログラムについても、リモートサーバー上で実行し、ネットワークを介して通信し、戻り値を取得することが可能です。

telnetを用いてネットワーク経由でhelloをリモート実行する
9 重要なテーマ
9.1 アムダールの法則
システムの一部を高速化したとき、システム全体のスループットはその部分の重要性と高速化の程度に依存します。
αはその部分が全体時間に占める割合、kは性能向上の倍率です。
加速比S=T_{old}/T_{new}を計算します。
kが無限大に近づくと、
9.2 同時実行と並列性
同時実行(コンカレンシー):同時に複数の活動を持つシステムを指します。並列性(並列処理):並行性を用いてシステムをより速く動作させることを指します。
-
スレッドレベルの並行
プロセスを用いて、複数のプログラムを同時に実行させることができ、これにより並行性が生まれます。この並行性は模擬的なもので、1台の計算機が実行中のプロセス間を高速に切り替えて実現します。これにより、複数のユーザーが同時にシステムと対話したり、同時に複数のタスクを実行したりできます。
マルチコアプロセッサは、複数のCPUを1つの集積回路チップに統合したものです。
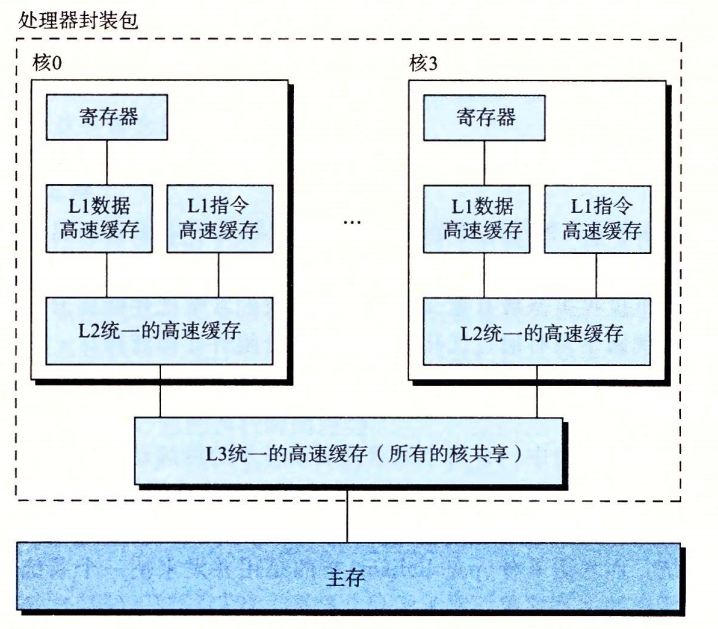
マルチコアプロセッサ
ハイパースレッディング、または同時多スレッドは、1つのCPUが複数の実行経路(スレッド)を実行できる技術です。ハイパースレッディング対応のプロセッサは、1サイクルを基準としてどのスレッドを実行するかを決定し、CPUが処理資源をよりよく利用できるようにします。
複数のプロセッサがシステム性能を向上させる理由は2つあります:1) 複数のタスクを模擬的に同時実行する必要が減る、2) アプリケーションがより速く動作する(プログラムをマルチスレッドで書く必要がある場合が多い)
-
命令レベルの並列
プロセッサは同時に複数の命令を実行できます。プロセッサはパイプラインを利用して命令の実行速度を高め、命令の実行を異なる段階に分割して、プロセッサのハードウェアを一連の段階に組織します。各段は1つのステップを実行します。段階は並行して動作し、異なる命令の異なるステップを処理します。
スーパーサカラー・プロセッサ — 1サイクルあたり1命令以上の実行速度を持つプロセッサ。
-
単一命令・多データ並列
プロセッサの特殊なハードウェアを利用して、1つの命令で複数の並列演算を生成する仕組みを、単一命令・多データ(SIMD)並列と呼びます。主に画像・音声・動画データ処理の速度向上を狙います。コンパイラがサポートする特別なベクトルデータ型を用いてプログラムを記述できます。
9.3 抽象の重要性
抽象の利用は、計算機科学において最も重要な概念の1つです。
プロセッサでは、ISAが実際のハードウェアを抽象化します。
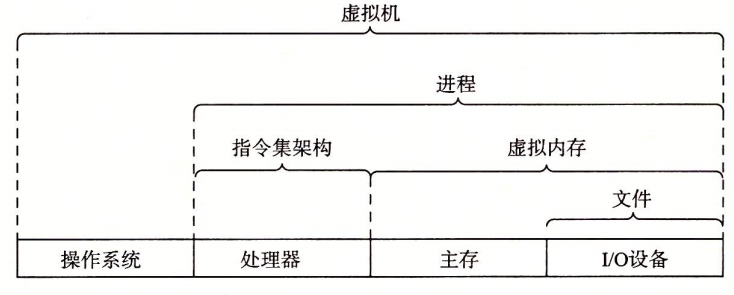
コンピュータシステムの抽象
仮想マシンは、OS、プロセッサ、プログラムを含む、コンピュータ全体の抽象です。
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります