


















本文は黒马のredis動画 に基づいて作成されています
Redisはキー値型のNoSQLデータベースです。ここには2つのキーワードがあります:
- キー値型
- NoSQL
そのうちキー値型は、Redisに保存されるデータがすべてkey.valueのペアとして保存され、valueの形式は多岐にわたり、文字列・数値・さらにはJSONにもなり得ます:
Redis入門
NoSQL
NoSQLはNot Only SQL(SQLだけではない)と訳されることが多い、あるいはNo SQL(非SQLの)データベースとも呼ばれます。伝統的なリレーショナルデータベースと比較して大きな差異を持つ、特殊なデータベースであり、したがって非リレーショナルデータベースとも呼ばれます。
- リレーショナルデータベースとの比較
従来のリレーショナルデータベースは構造化データで、各テーブルには厳密な制約情報があります:フィールド名、フィールドのデータ型、フィールド制約などの情報。挿入されるデータはこれらの制約を遵守しなければなりません:
一方、NoSQLはデータベースの形式に厳密な制約を課さず、しばしば形式がゆるく、自由です。キー値型、ドキュメント型、グラフ型などになり得ます。
従来のデータベースの表と表の間には関連が存在することが多く、例えば外部キーなど
一方、非リレーショナルデータベースには関連関係が存在しません。関係を維持するには、アプリケーションのビジネスロジックで行うか、データ間の結合に頼る必要があります
従来のリレーショナルデータベースはSQL文に基づいてクエリを実行し、構文には統一された標準があります;
しかし、さまざまなNoSQLデータベースごとにクエリ構文は大きく異なり、千差万別です。
従来のリレーショナルデータベースはACIDの原則を満たすことができます
一方、非リレーショナルデータベースは、トランザクションをサポートしない、あるいはACID特性を厳密に保証できないことが多く、基本的な一貫性のみを実現します

- 保存方式
- リレーショナルデータベースはディスク上に保存するため、多くのディスクI/Oが発生し、パフォーマンスに一定の影響を与えます
- 非リレーショナルデータベースは、操作の多くをメモリ上で行うことが多く、メモリの読み書き速度が非常に速いため、性能は自然と良くなります
- 拡張性
- リレーショナルデータベースのクラスタリングは一般にマスター-スレーブ構成で、データは一致し、データバックアップの役割を果たします。垂直拡張と呼ばれます。
- NoSQLデータベースはデータを分割して異なるマシンに保存することができ、膨大なデータを保存でき、メモリ容量の制限を解決します。水平拡張と呼ばれます。
- テーブル間に関連があるため、水平拡張を行うとデータのクエリに多くの手間が発生します
Redis
Redisの正式名称は、Remote Dictionary Server(リモート辞書サーバー)で、メモリ上に基づくキー値型NoSQLデータベースです。
特徴:
- キー値型(key-value)で、valueは多様なデータ構造をサポートし、機能が豊富
- シングルスレッド、各コマンドは原子性を備えます
- 低遅延、高速(メモリ上に基づく、I/O多重化。良好なエンコード。)
- データの永続化をサポート
- マスター-スレーブ構成とシャーディングをサポート
- 複数言語のクライアントをサポート
Redis安装
Dockerでのインストール
docker search redisdocker pul redisdocker run --restart=always -p 6379:6379 --name myredis -v /home/redis/myredis/myredis.conf:/etc/redis/redis.conf -v /home/redis/myredis/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes
docker exec -it <容器名> /bin/bashRedisの一般コマンド
Redisデータ構造の紹介
Redisはキー-valueデータベースで、キーは一般的にString型ですが、valueの型は多様です:

Redisの共通コマンド
共通コマンドは、いくつかのデータ型で使用できるコマンドで、よく使われるものは以下のとおりです:
- KEYS:テンプレートに一致するすべてのキーを表示します
127.0.0.1:6379> keys *
# テンプレート"a"で始まるキーを検索127.0.0.1:6379> keys a*1) "age"本番環境では、keys コマンドの使用は推奨されません。なぜなら、キーが多数ある場合、効率が低いからです
- DEL:指定したキーを削除します
127.0.0.1:6379> del name #削除単一(integer) 1 #成功 delete 1
127.0.0.1:6379> keys *1) "age"
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3 #複数データを一括追加OK
127.0.0.1:6379> keys *1) "k3"2) "k2"3) "k1"4) "age"
127.0.0.1:6379> del k1 k2 k3 k4(integer) 3 #この時点で削除されたキーは3つ。Redisにはk1,k2,k3しかないため、実際には3つが削除され、最終的に3を返します
127.0.0.1:6379> keys * #すべてのキーを再度検索1) "age" # 残っているのは1つだけ- EXISTS:キーが存在するかを判定
127.0.0.1:6379> exists age(integer) 1
127.0.0.1:6379> exists name(integer) 0- EXPIRE:キーに有効期限を設定。期限が切れると自動的に削除される
- TTL:キーの残り有効期限を表示
127.0.0.1:6379> expire age 10(integer) 1
127.0.0.1:6379> ttl age(integer) 8
127.0.0.1:6379> ttl age(integer) -2
127.0.0.1:6379> ttl age(integer) -2 # このキーが期限切れの場合、ttlは-2になる
127.0.0.1:6379> keys *(empty list or set)
127.0.0.1:6379> set age 10 # 有効期限を設定していない場合OK
127.0.0.1:6379> ttl age(integer) -1 # ttlの返り値は-1Redis命令-String命令
String型は、Redisで最も基本的なストレージ型です。
その値は文字列ですが、文字列の形式に応じて3つのカテゴリに分けられます:
- string:通常の文字列
- int:整数型、インクリメント・デクリメントが可能
- float:浮動小数点型、インクリメント・デクリメントが可能
Stringの一般的なコマンドは以下のとおり:
- SET:新規作成または既存のStringキーの値を変更します
- GET:キーに応じてString型の値を取得します
- MSET:複数のString型キーと値を一括して追加します
- MGET:複数のキーに対して複数のString値を取得します
- INCR:整数型キーを1ずつ増加させます
- INCRBY:整数型キーを指定したステップ分だけ増加させます。例:INCRBY num 2 で num を2増やします
- INCRBYFLOAT:浮動小数点数を指定したステップ分だけ増加させます
- SETNX:キーが存在しない場合のみString型のキー値ペアを追加します。存在する場合は実行されません
- SETEX:String型のキーと値を追加し、有効期限を指定します
Redis命令-Keyの階層構造
RedisにはMySQLのようなTableの概念はありません。異なるタイプのキーをどう区別しますか?
Redisのキーは複数の単語で階層構造を形成することが許され、複数の単語の間は’:‘で区切ります
この形式は固定ではなく、用途に応じて語を削除したり追加したりできます。
例えばプロジェクト名をheimaとし、userとproductの2種類のデータがある場合、次のようにキーを定義できます:
- user関連のキー:heima:user<1>
- product関連のキー:heima:product<1>
ValueがJavaオブジェクト(例:Userオブジェクト)である場合、オブジェクトをJSON文字列にシリアライズして保存できます:
| KEY | VALUE |
|---|---|
| heima:user<1> | {“id”<1>, “name”: “Jack”, “age”: 21} |
| heima:product<1> | {“id”<1>, “name”: “小米11”, “price”: 4999} |
このようにRedisに保存すると、可視化インターフェース上で階層構造として保存され、Redisのデータ取得がより便利になります
Redis命令-Hash命令
Hash型、別名ハッシュ、valueは無秩序な辞書で、JavaのHashMap構造に似ています。
String構造はオブジェクトをJSON文字列にシリアライズして保存します。オブジェクトの特定のフィールドを変更する必要がある場合は非常に不便です:
Hash構造はオブジェクトの各フィールドを個別に保存することができ、単一フィールドに対してCRUDを行えます:
Hash型の一般的コマンド
- HSET key field value:Hash型のkeyのfieldの値を追加または変更します
- HGET key field:Hash型のkeyのfieldの値を取得します
- HMSET:複数のhash型keyのfieldの値を一括で追加します
- HMGET:複数のhash型keyのfieldの値を一括取得します
- HGETALL:Hash型のkeyに含まれるすべてのfieldとvalueを取得します
- HKEYS:Hash型のkeyに含まれるすべてのfieldを取得します
- HINCRBY
- HSETNX:Hash型のkeyのfield値を追加します。前提としてそのfieldが存在しない場合のみ実行され、存在する場合は実行されません
Redis命令-List命令
RedisのList型はJavaのLinkedListに似ており、双方向リスト構造と見なすことができます。前方検索も後方検索も可能です。
特徴もLinkedListと似ています:
- 有序
- 要素は重複可能
- 挿入と削除が速い
- 検索速度は普通
しばしば有序データを保存するのに用いられます。例えば、友だちのタイムラインでのいいねリスト、コメントリストなど。
Listの一般的コマンドは以下のとおり:
- LPUSH key element … :リストの左側に1つ以上の要素を挿入します
- LPOP key:リストの左端の最初の要素を削除して返します。なければnilを返します
- RPUSH key element … :リストの右側に1つ以上の要素を挿入します
- RPOP key:リストの右端の最初の要素を削除して返します
- LRANGE key start end:一定範囲のすべての要素を返します
- BLPOPおよびBRPOP:LPOPおよびRPOPと似ていますが、要素がない場合は指定した時間待機し、nilをすぐには返しません
Redis命令-Set命令
RedisのSet型はJavaのHashSetに似ており、値はnullのHashMapと見なすことができます。ハッシュテーブルでもあるため、HashSetと同様の特徴を持ちます:
- 無秩序
- 要素は重複不可
- 検索が速い
- 交差、和集合、差集合などの機能をサポート
Set型の一般的コマンド
- SADD key member …:Setに1つ以上の要素を追加します
- SREM key member …:Setから指定した要素を削除します
- SCARD key:Setの要素数を返します
- SISMEMBER key member:要素がSetに存在するかを判定します
- SMEMBERS:Setの全要素を取得します
- SINTER key1 key2 … :key1とkey2の交差を求めます
- SDIFF key1 key2 … :key1とkey2の差集合を求めます
- SUNION key1 key2 ..:key1とkey2の和集合を求めます
Redis命令-SortedSetタイプ
RedisのSortedSetはソート可能な集合で、JavaのTreeSetに似ていますが、内部データ構造は大きく異なります。SortedSetの各要素はscore属性を持ち、それに基づいてソートされ、内部実装はSkip Listとハッシュテーブルの組み合わせです。
SortedSetの特徴は以下のとおりです:
- ソート可能
- 要素は重複しません
- 検索速度が速い
SortedSetのソート可能という特性のため、ランキングのような機能の実装によく用いられます。
SortedSetの一般的コマンドは以下のとおりです:
- ZADD key score member:1つ以上の要素をSorted Setに追加します。すでに存在する場合はscore値を更新します
- ZREM key member:Sorted Setから指定された要素を削除します
- ZSCORE key member:Sorted Set内の指定要素のscore値を取得します
- ZRANK key member:指定要素の順位を取得します
- ZCARD key:Sorted Setの要素数を取得します
- ZCOUNT key min max:指定範囲内の要素数を統計します
- ZINCRBY key increment member:指定要素をincrement値だけ自動増加させます
- ZRANGE key min max:scoreでソートした後、指定した順位範囲の要素を取得します
- ZRANGEBYSCORE key min max:scoreでソートした後、指定したscore範囲の要素を取得します
- ZDIFF.ZINTER.ZUNION:差集合・交集合・和集合を求めます
注意:すべての順位はデフォルトで昇順です。降順にしたい場合は、コマンドのZの後ろにREVを追加します。例えば:
- 昇順でSorted Setの指定要素の順位を取得:ZRANK key member
- 降順でSorted Setの指定要素の順位を取得:ZREVRANK key member
Javaクライアント-Jedis
https://redis.io/docs/clients/
- JedisとLettuce:この2つはRedisコマンドに対応するAPIを提供しており、Redisの操作を容易にします。Spring Data Redisはこれら2つを抽象化・ラップしているため、今後はSpring Data Redisを使って学習します。
- Redisson:Redisをベースに、Map・Queueなどの分散スケーラブルなJavaデータ構造を実装し、プロセス間の同期機構(Lock・Semaphoreの待機など)をサポートします。特定の機能要件の実現に適しています。
Jedis入門
依存関係:
<!--jedis--><dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version></dependency>テスト:
private Jedis jedis;
@BeforeEachvoid setup() { // 1.接続を確立 // jedis = new Jedis("192.168.150.101", 6379);// jedis = JedisConnectionFactory.getJedis(); jedis = new Jedis("127.0.0.1",6379); // 2.パスワード設定// jedis.auth("123321"); // 3.データベースを選択 jedis.select(0);}
@Testvoid testString() { // データを格納 String result = jedis.set("name", "虎哥"); System.out.println("result = " + result); // データを取得 String name = jedis.get("name"); System.out.println("name = " + name);}
@Testvoid testHash() { // hashデータを挿入 jedis.hset("user:1", "name", "Jack"); jedis.hset("user:1", "age", "21");
// 取得 Map<String, String> map = jedis.hgetAll("user:1"); System.out.println(map);}
@AfterEachvoid tearDown() { if (jedis != null) { jedis.close(); }}Jedis连接池
Jedis自体はスレッドセーフではなく、頻繁な接続の作成と破棄はパフォーマンス損耗を招くため、Jedis直結方式の代わりにJedis接続プールを使用することを推奨します
プール化の思想はここだけでなく、さまざまな場面で見られます。たとえばデータベース接続プール、Tomcatのスレッドプールなど、これらはすべてプール化思想の現れです。
public class JedisConnectionFacotry {
private static final JedisPool jedisPool;
static { //接続プールを設定 JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(8); poolConfig.setMaxIdle(8); poolConfig.setMinIdle(0); poolConfig.setMaxWaitMillis(1000); //接続プールオブジェクトを作成 jedisPool = new JedisPool(poolConfig,"127.0.0.1",6379,1000); }
public static Jedis getJedis(){ return jedisPool.getResource(); }}JedisFactoryからJedis接続を取り出す:
@BeforeEachvoid setup() { // 接続を確立 jedis = JedisConnectionFacotry.getJedis(); // データベースを選択 jedis.select(0);}SpringDataRedis
Spring DataはSpringのデータ操作モジュールで、さまざまなデータベースの統合を含み、Redisの統合モジュールはSpring Data Redisと呼ばれます。公式サイトのアドレス:https://spring.io/projects/spring-data-redis
- LettuceとJedisという異なるRedisクライアントの統合を提供します
- RedisTemplateを提供し、Redisを操作する統一APIを提供します
- RedisのPub/Subモデルをサポート
- Redis SentinelとRedisクラスタをサポート
- Lettuceベースのリアクティブプログラミングをサポート
- JDK、JSON、文字列、Springオブジェクトのデータのシリアライズ・デシリアライズをサポート
- RedisベースのJDKコレクション実装をサポート
SpringDataRedisにはRedisTemplateツールクラスが提供されており、さまざまなRedis操作を包んでいます。また、異なるデータ型の操作APIを異なるタイプに封装しています:
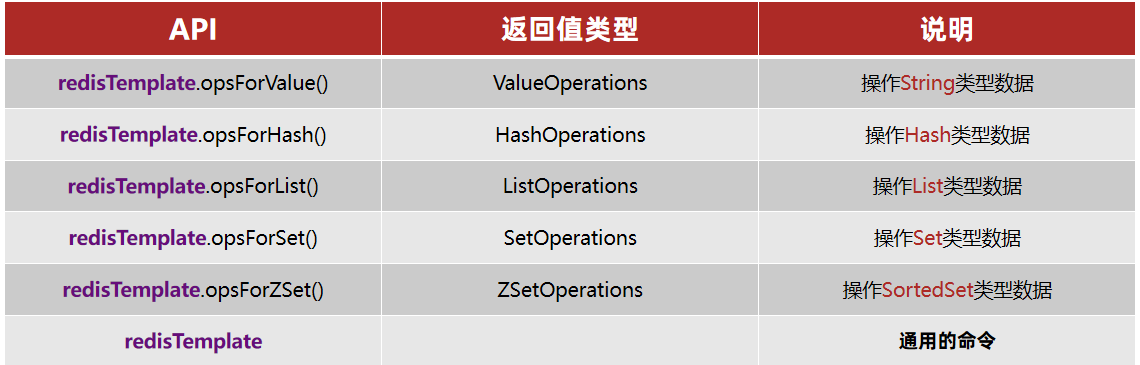
SpringDataRedis入門
pom依存関係:
<!--redis依存--><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--common-pool--><dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId></dependency><!--Jackson依存--><dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId></dependency><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional></dependency>yml配置:
spring: redis: host: 127.0.0.1 port: 6379# password: 123321 lettuce: pool: max-active: 8 #最大接続 max-idle: 8 #最大空闲接続 min-idle: 0 #最小空闲接続 max-wait: 100ms #接続待機時間テスト:
@SpringBootTestclass JedisDemoApplicationTests {
@Autowired private RedisTemplate redisTemplate;
@Test void testString(){ redisTemplate.opsForValue().set("name","hg");
Object name = redisTemplate.opsForValue().get("name"); System.out.println(name); }
}- spring-boot-starter-data-redis依存関係を追加
- application.ymlにRedis情報を設定
- RedisTemplateを注入
データのシリアライズ
RedisTemplateは任意のObjectを値としてRedisに書き込むことができます:
ただし書き込む前にObjectをバイト列にシリアライズします。デフォルトではJDKシリアライズを使用し、得られる結果はこのようになります:
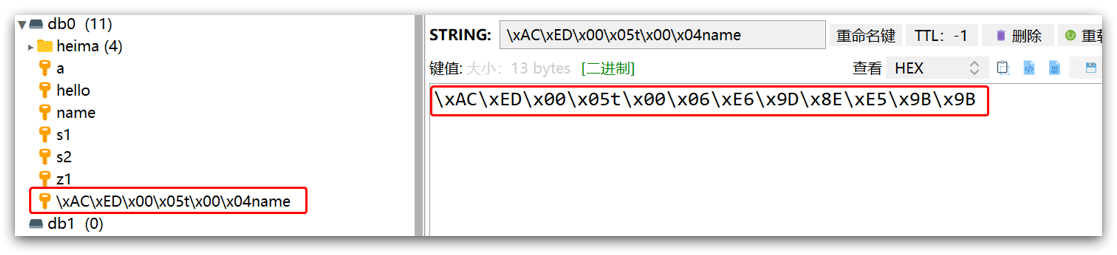
欠点:
- 読みやすさが悪い
- メモリ使用量が大きい
カスタムシリアライズ方式
@Configurationpublic class RedisConfig {
@Bean public RedisTemplate redisTemplate(RedisConnectionFactory connectionFactory){ // RedisTemplateオブジェクトを作成 RedisTemplate template = new RedisTemplate(); // 接続ファクトリを設定 template.setConnectionFactory(connectionFactory); // JSONシリアライズツールを作成 GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer(); // Keyのシリアライズを設定 template.setKeySerializer(RedisSerializer.string()); template.setHashKeySerializer(RedisSerializer.string()); // Valueのシリアライズを設定 template.setValueSerializer(jsonRedisSerializer); template.setHashValueSerializer(jsonRedisSerializer); // 返す return template; }
}StringRedisTemplate
デシリアライズ時にオブジェクトの型を知るため、JSONシリアライザはクラスの型情報をJSON結果に書き込み、Redisに格納します。これにより余分なメモリ使用量が発生します。
メモリの消費を抑えるため、手動シリアライズの方法を採用します。言い換えれば、デフォルトのシリアライザを使わず、自分でシリアライズの動作を制御します。同時に、文字列シリアライザだけを使用します。これにより、valueを保存する際に、メモリ上で余分にデータを保持する必要がなくなり、メモリ空間を節約できます
@Autowiredprivate StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Testvoid testSaveUser() throws JsonProcessingException { // オブジェクトを作成 User user = new User("hg", 21); // 手動シリアライズ String json = mapper.writeValueAsString(user); // データを書き込む stringRedisTemplate.opsForValue().set("user:200", json);
// データを取得 String jsonUser = stringRedisTemplate.opsForValue().get("user:200"); // 手動デシリアライズ User user1 = mapper.readValue(jsonUser, User.class); System.out.println("user1 = " + user1);}RedisTemplateの2つのシリアライズ実践案:
- 案1:
- 自作RedisTemplate
- RedisTemplateのシリアライザをGenericJackson2JsonRedisSerializerへ変更
- 案2:
- StringRedisTemplateを使用
- Redisへ書き込む際、オブジェクトを手動でJSONにシリアライズ
- Redisから読み取る際、読み取ったJSONを手動でデシリアライズしてオブジェクト化
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります