


















正しいスレッドプールの宣言
スレッドプールは必ず手動で ThreadPoolExecutor **のコンストラクタを介して宣言する必要があります。Executors クラスを使ってスレッドプールを作成するのは避けてください。OOM のリスクがあります。
Executors が返すスレッドプールオブジェクトのデメリットは以下のとおりです:
FixedThreadPoolとSingleThreadExecutor:無界のLinkedBlockingQueueを使用しており、タスクキューの最大長はInteger.MAX_VALUE、大量のリクエストが蓄積されて OOM になる可能性があります。CachedThreadPool:SynchronousQueue を使用し、作成可能なスレッド数がInteger.MAX_VALUEで、大量のスレッドを作成して OOM になる可能性があります。ScheduledThreadPoolとSingleThreadScheduledExecutor: 無界の遅延ブロックキュー DelayedWorkQueue を使用しており、タスクキューの最大長はInteger.MAX_VALUE、大量のリクエストが蓄積されて OOM になる可能性があります。
要するに:有界キューを使用して、スレッド作成数を制御する。
実際の OOM を避ける以外にも、Executors が提供する2つの快捷なスレッドプールを推奨しない理由は以下のとおりです:
- 実際の運用では、マシンの性能やビジネスシナリオに応じて、コアスレッド数、使用するタスクキュー、飽和時の策略などを手動で設定する必要があります。
- また、スレッドプールを命名することは重要です。名前を付けることで問題の特定が容易になります。
スレッドプールの実行状態の監視
SpringBoot の Actuator など、スレッドプールの実行状態を検知する手段を利用できます。
それに加えて、ThreadPoolExecutor の関連 API を用いて簡易的な監視を行うことも可能です。ThreadPoolExecutor は現在のスレッド数やアクティブスレッド数、完了したタスク数、待機中のタスク数などを取得できます。
以下は簡易 Demo です。printThreadPoolStatus() は1秒ごとにスレッドプールの総数、アクティブなスレッド数、完了したタスク数、キュー内のタスク数を表示します。
/** * 打印线程池的状态 * * @param threadPool 线程池对象 */public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) { ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false)); scheduledExecutorService.scheduleAtFixedRate(() -> { log.info("========================="); log.info("ThreadPool Size: [{}]", threadPool.getPoolSize()); log.info("Active Threads: {}", threadPool.getActiveCount()); log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount()); log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size()); log.info("========================="); }, 0, 1, TimeUnit.SECONDS);}異なるカテゴリのビジネスには別々のスレッドプールを推奨
多くの人が実務で以下のような問題に直面します:私のプロジェクトには複数のビジネスでスレッドプールを使う必要があります。各スレッドプールを定義すべきか、それとも共用のスレッドプールを使うべきか?
一般的には、異なるビジネスには別々のスレッドプールを使用し、現在のビジネスの状況に応じてそのスレッドプールを設定します。なぜなら、ビジネスごとに並行性やリソースの使用状況が異なるため、システムの性能ボトルネックに焦点を合わせたビジネスを最適化する必要があるからです。
実際の事故ケースを見てみましょう
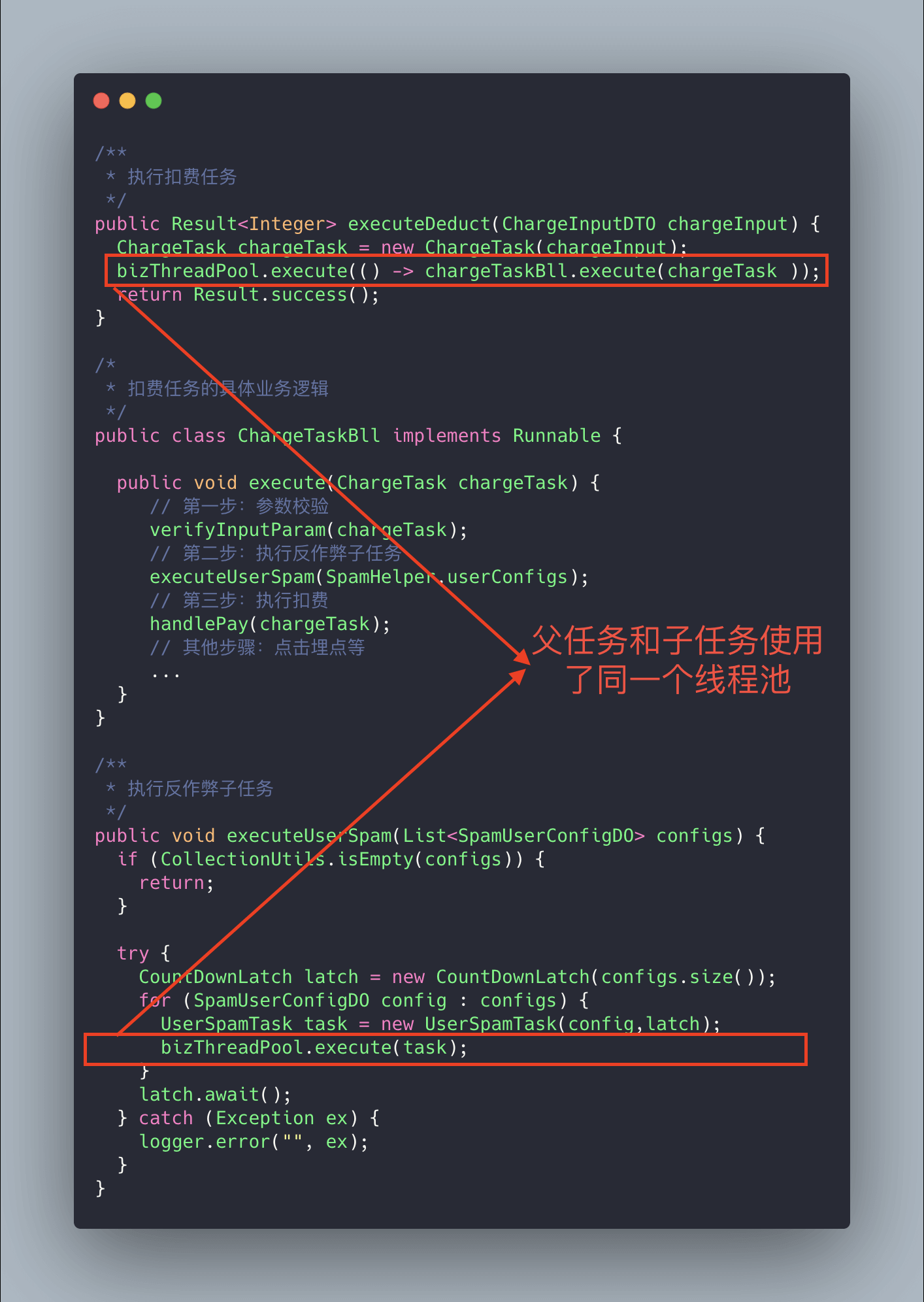
上記のコードは死結が発生する可能性があります。なぜでしょうか?
極端なケースを想像してみましょう:スレッドプールのコアスレッド数を n、親タスク(課金タスク)の数を n、親タスクの下に2つのサブタスク(課金タスク下のサブタスク)があり、そのうち1つがすでに実行完了し、もう1つがタスクキューに入っています。親タスクがスレッドプールのコアスレッド資源を使い切っているため、子タスクはスレッド資源を取得できず正常に実行できず、キューで待機し続けます。親タスクは子タスクの実行完了を待ち、子タスクは親タスクがスレッドプール資源を開放するのを待つことになり、これが「デッドロック」を引き起こします。
解決方法は非常に単純で、子タスクを実行する専用の別のスレッドプールを新たに追加して、それを子タスク専用にします。
スレッドプールに名前を付けるのを忘れずに
スレッドプールを初期化する際には明示的に名前を付ける(スレッドプール名のプレフィックスを設定する)と、問題の特定に役立ちます。
デフォルトで作成されるスレッド名は pool-1-thread-n のようなもので、業務の意味を持たず、問題の特定には不便です。
スレッドプール内のスレッドに名前を付けるには、通常次の2つの方法があります:
-
Guava の
ThreadFactoryBuilderThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat(threadNamePrefix + "-%d").setDaemon(true).build();ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory) -
自分で実装する
ThreadFactory。import java.util.concurrent.ThreadFactory;import java.util.concurrent.atomic.AtomicInteger;/*** 线程工厂,它设置线程名称,有利于我们定位问题。*/public final class NamingThreadFactory implements ThreadFactory {private final AtomicInteger threadNum = new AtomicInteger();private final String name;/*** 创建一个带名字的线程池生产工厂*/public NamingThreadFactory(String name) {this.name = name;}@Overridepublic Thread newThread(Runnable r) {Thread t = new Thread(r);t.setName(name + " [#" + threadNum.incrementAndGet() + "]");return t;}}
正しいスレッドプールのパラメータ設定
まず、さまざまな書籍とブログで一般的に推奨されるスレッドプールのパラメータ設定方法を見てみましょう。参考として。
一般的な操作
スレッド数が多すぎる影響は、私たちが仕事を割り当てる人数と同様に、マルチスレッドのこの状況では主にコンテキストスイッチングのコストを増加させます。
- スレッドプールの数が小さすぎる場合、一度に大量のタスク/リクエストを処理する必要があると、タスク/リクエストがキューで待機して実行される、キューが満杯になって待機できなくなる、またはキューに大量のタスクが堆積してOOM になるなどの問題が生じ、CPU が十分に活用されません。
- スレッド数を大きくすると、多数のスレッドが同時に CPU 資源を奪い合い、多くのコンテキストスイッチが発生して、スレッドの実行時間が長くなり、全体の実行効率が低下します。
一般的で広く適用できる式があります:
- CPU 集中型タスク(N+1):このタイプのタスクは主に CPU リソースを消費するため、スレッド数を N(CPU コア数)+1 に設定します。余分な1つのスレッドは、突発的なページフォールトなど、タスクが一時停止する原因を補うためです。タスクが一時停止すると CPU は空闲になり、この追加スレッドが CPU の空き時間を有効活用します。
- I/O 集中型タスク(2N):このタイプのタスクは、I/O との対話に多くの時間を要し、I/O を待っている間は CPU を占有しません。従って CPU を他のスレッドに割り当てることができます。I/O 集中型のアプリケーションでは、スレッドを多めに設定します。具体的な計算方法は 2N。
どうやってCPU密集型かIO密集型かを判断しますか?
CPU密集型の簡単な理解は、CPUの計算能力を利用するタスク、例えば大量データのソートなどです。ネットワーク読み取り、ファイル読み取りなどはすべて IO 密集型であり、これらのタスクはCPU の計算に要する時間が IO 操作待ちの時間よりも少なく、待機時間の方が長いのが特徴です。
スレッド数をより厳密に計算する方法は次のとおりです:最佳线程数 = N(CPU 核心数)∗(1+WT(线程等待时间)/ST(线程计算时间))、ここで WT(线程等待时间)=线程运行总时间 - ST(线程计算时间)。
WT が大きいほど、より多くのスレッドが必要になります。ST が大きいほど、より少ないスレッドが必要になります。
私たちは JDK に付属するツール VisualVM を使って WT/ST の比率を確認できます。
CPU 密集型タスクの WT/ST は 0 に近い、あるいは等しいため、スレッド数は N(CPU コア数)∗(1+0)= N に設定でき、上記の N(CPU コア数)+1 とほぼ同じです。
IO 密集型タスクでは、ほとんど全てが待機時間です。原理的にはスレッド数を 2N に設定してよいです(WT/ST の結果が大きくなるはずですが、過度なスレッド作成を避ける意味で 2N を選ぶことが多いです)。
注意:上記の式はあくまで参考であり、実際のプロジェクトでは式に従って直接パラメータを設定することはあまりなく、ビジネス環境ごとに要件が異なるため、実稼働状況に応じて動的に調整する必要があります。
美団の最適化操作
美団の技術チームは「Java 线程池实现原理及其在美团业务中的实践」という記事の中で、スレッドプールのパラメータをカスタマイズ可能にするアプローチを紹介しています。
美団のアプローチは、主にスレッドプールの核心パラメータをカスタム可能にすることです。3つのコアパラメータは:
corePoolSize:コアスレッド数。同時に動作可能な最小スレッド数を定義します。maximumPoolSize:キューの容量に達した場合、同時実行可能なスレッド数が最大値になります。workQueue:新しいタスクが来たとき、現在の実行スレッド数がコアスレッド数に達しているかを判断し、達していればタスクをキューに格納します。
なぜこの3つのパラメータですか?
この3つのパラメータは ThreadPoolExecutor の最も重要なパラメータであり、タスクの処理戦略をほぼ決定します。
特に corePoolSize には注意が必要です。プログラムの実行中に setCorePoolSize() を呼ぶと、現在の作業スレッド数が corePoolSize を超えている場合、スレッドを回収します。
また、上記には動的にキュー長を指定する方法がないことにも気づきます。美団の方法は ResizableCapacityLinkedBlockIngQueue というキューを自作することでした(主に LinkedBlockingQueue の capacity フィールドの final 修飾子を外して可変にする、という点です)。
もし私たちのプロジェクトでもこの効果を実現したい場合は、すでに用意されているオープンソースプロジェクトを活用するのが良いでしょう:
- Hippo4j:非同期スレッドプールフレームワーク。スレッドプールの動的変更、監視、アラートをサポート。コード変更なしで導入可能。複数の使用モードをサポートし、システムの運用保証能力の向上を目指します。
- Dynamic TP:軽量な動的スレッドプール。内蔵監視・警告機能を備え、サードパーティのミドルウェアと連携したスレッドプール管理を提供。主流の設定センターに対応(Nacos、Apollo、Zookeeper、Consul、Etcd、SPI での自作実装も可能)。
スレッドプールを閉じるのを忘れないでください
スレッドプールが不要になったときには、明示的にスレッドプールを閉じ、スレッド資源を解放すべきです。
スレッドプールには2つのシャットダウン方法があります:
shutdown(): スレッドプールをシャットダウンします。スレッドプールの状態はSHUTDOWNとなり、新しいタスクは受け付けられなくなりますが、キュー内のタスクは完了します。shutdownNow(): スレッドプールを強制的にシャットダウンします。状態はSTOPとなり、現在実行中のタスクを強制終了し、待機中のタスクの処理を停止して、実行待ちの List を返します。
shutdownNow と shutdown を呼び出した後も、直ちにスレッドプールが完全に閉じるわけではなく、非同期で閉じ処理が通知されているだけです。完全に閉じるまで待つ必要がある場合は、awaitTermination を呼んで同期的に待機します。
// ...// 关闭线程池executor.shutdown();try { // 等待线程池关闭,最多等待5分钟 if (!executor.awaitTermination(5, TimeUnit.MINUTES)) { // 如果等待超时,则打印日志 System.err.println("线程池未能在5分钟内完全关闭"); }} catch (InterruptedException e) { // 异常处理}スレッドプールには長時間実行タスクを入れない
スレッドプール自体の目的は、タスクの実行効率を高めることと、頻繁なスレッド作成・破棄によるパフォーマンスコストを避けることです。長時間実行されるタスクをスレッドプールに投入すると、スレッドが長時間占有され、他のタスクへ迅速に応答できなくなり、最悪の場合スレッドプールが崩壊したり、プログラムがフリーズしたりする可能性があります。
したがって、スレッドプールを使う際には、長時間実行タスクをスレッドプールに投入することをできるだけ避けるべきです。ネットワーク要求、ファイルの読み書きなど、時間のかかる操作には非同期処理を用意して処理することで、スレッドプール内のスレッドのブロックを回避します。
スレッドプールの使用時の小さな落とし穴
繰り返しスレッドプールを作成する落とし穴
スレッドプールは再利用可能です。ユーザーのリクエストごとに新しいスレッドプールを作成するなど、頻繁に作成してはいけません。
@GetMapping("wrong")public String wrong() throws InterruptedException { // 自作のスレッドプール ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(100),new ThreadPoolExecutor.CallerRunsPolicy());
// 处理任务 executor.execute(() -> { // ...... } return "OK";}この問題が起こる原因は、スレッドプールの理解が十分でないことにあります。スレッドプールの基礎知識を高める必要があります。
Spring 内部スレッドプールの落とし穴
Spring の内部スレッドプールを使用する場合は、必ず手動でスレッドプールを定義し、合理的なパラメータを設定してください。そうしないと生産上の問題(1つのリクエストにつき1つのスレッドが作成される等)が発生します。
@Configuration@EnableAsyncpublic class ThreadPoolExecutorConfig {
@Bean(name="threadPoolExecutor") public Executor threadPoolExecutor(){ ThreadPoolTaskExecutor threadPoolExecutor = new ThreadPoolTaskExecutor(); int processNum = Runtime.getRuntime().availableProcessors(); // 利用可能なCPUコア数を返す int corePoolSize = (int) (processNum / (1 - 0.2)); int maxPoolSize = (int) (processNum / (1 - 0.5)); threadPoolExecutor.setCorePoolSize(corePoolSize); // コアプールサイズ threadPoolExecutor.setMaxPoolSize(maxPoolSize); // 最大スレッド数 threadPoolExecutor.setQueueCapacity(maxPoolSize * 1000); // キューの容量 threadPoolExecutor.setThreadPriority(Thread.MAX_PRIORITY); threadPoolExecutor.setDaemon(false); threadPoolExecutor.setKeepAliveSeconds(300);// スレッドのアイドル時間 threadPoolExecutor.setThreadNamePrefix("test-Executor-"); // スレッド名のプレフィックス return threadPoolExecutor; }}スレッドプールと ThreadLocal の共用の落とし穴
スレッドプールと ThreadLocal の共用は、スレッドプールがスレッドオブジェクトを再利用するため、スレッドオブジェクトに結びつくクラスの静的属性である ThreadLocal 変数も再利用され、別のスレッドの ThreadLocal 値を取得してしまう可能性があります。
コード上でスレッドプールを明示的に使用していないからといって、スレッドプールが存在しないわけではありません。例えば、一般的な Web サーバー Tomcat は高い同時処理を実現するためにスレッドプールを使用しており、原生 Java のスレッドプールを改善して得られた自作のスレッドプールを利用しています。
もちろん Tomcat を単一スレッドで処理するように設定することもできますが、それは適切ではなく、タスク処理速度に重大な影響を与えます。
server.tomcat.max-threads=1この問題を解決するのに比較的推奨される方法は、Alibaba のオープンソースである TransmittableThreadLocal(TTL)を使用することです。TransmittableThreadLocal クラスは JDK 内蔵の InheritableThreadLocal を継承・拡張しており、スレッドプールなどのプーリング再利用されるスレッドを使用する場合に、ThreadLocal の値を伝搬させる機能を提供し、非同期実行時のコンテキスト伝搬の問題を解決します。
TransmittableThreadLocal プロジェクトのURL:https://github.com/alibaba/transmittable-thread-local。
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります