


















コレクションの概要
Java コレクションの概要
Java のコレクション、 つまりコンテナは、主に二つのインターフェースから派生します:一つは Collection インターフェース、主に単一の要素の格納に使用されます;もう一つは Map インターフェース、主にキーと値のペアの格納に使用されます。Collection インターフェースには、以下の三つの主要なサブインターフェースがあります:List、Set、Queue。
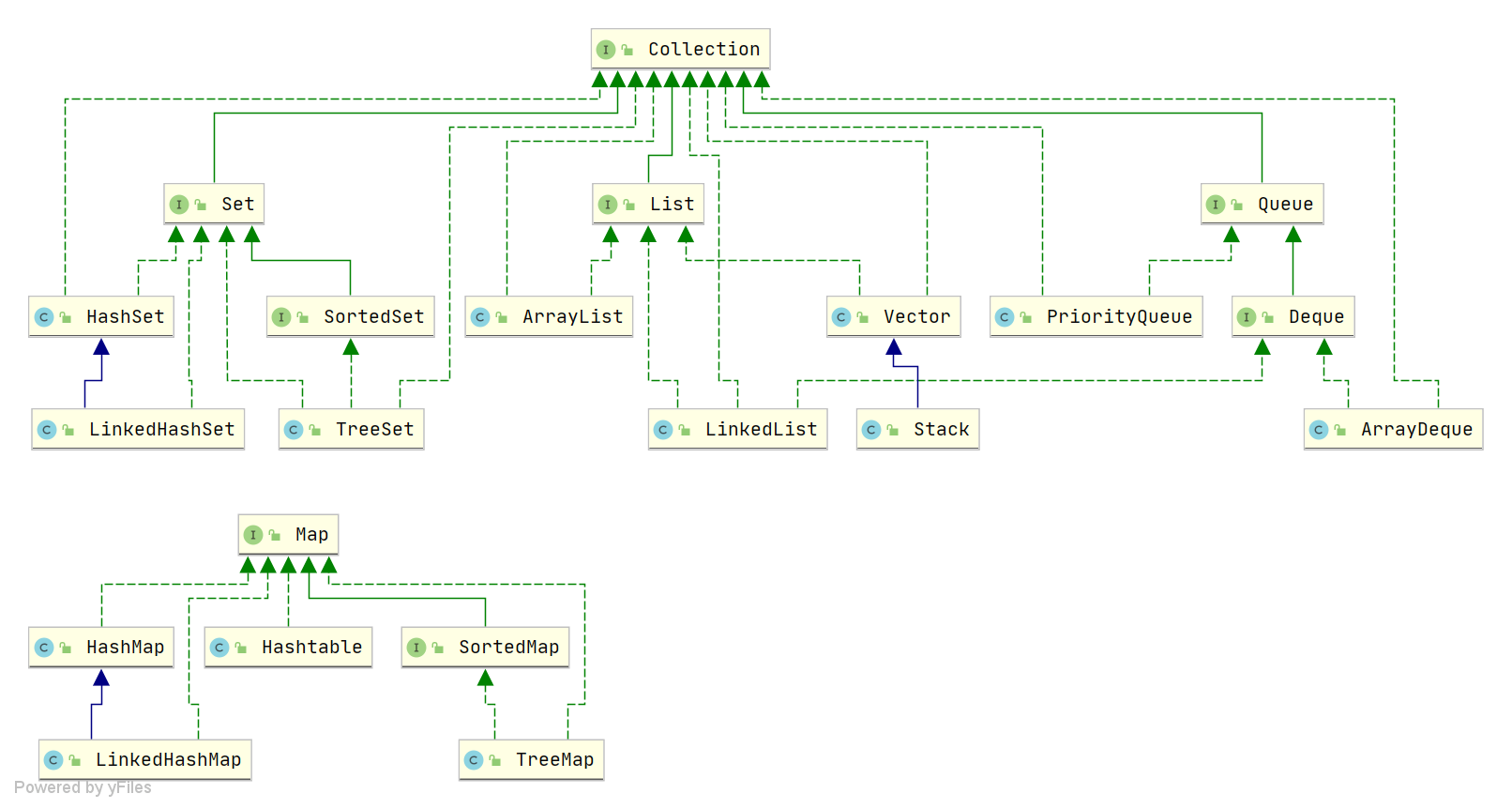
List, Set, Queue, Map の四者の違いについて
- List(順序の扱いの頼れる味方):格納される要素は有序で、重複可能である。
- Set(独自性を重視):格納される要素は重複不可。
- Queue(待ち行列機能を実現するキュー):特定の待機規則に従って先後順を決定し、格納される要素は有序で、重複してよい。
- Map(キーを用いて検索の専門家):キーと値のペア(key-value)を格納します。数学の関数 y=f(x) のように、“x” が key、“y” が value を表します。key は無序で重複不可、value は無序で重複可。各キーは最大で一つの値にマッピングされます。
コレクションフレームワークの基盤データ構造の要約
List
- ArrayList:Object[] 配列。
- Vector:Object[] 配列。
- LinkedList:双方向リスト(JDK1.6 以前は循環リンクリスト、JDK1.7 で循環がなくなった)。
Set
- HashSet(無序、唯一性): HashMap を基盤として実装され、底層は HashMap を使用して要素を保存します。
- LinkedHashSet: LinkedHashSet は HashSet のサブクラスで、内部は LinkedHashMap によって実装されています。
- TreeSet(有序、唯一性):赤黒木(自己平衡のソート済み二分木)。
Queue
- PriorityQueue: Object[] 配列を用いて小頂点ヒープを実現。
- DelayQueue: PriorityQueue。
- ArrayDeque: 拡張可能な動的双方向配列。
Map
- HashMap:JDK1.8 以前は HashMap は配列+リストで構成されており、配列が主体、リストはハッシュ衝突を解決するための拉链法。JDK1.8 以降、衝突解決には大きな変化があり、リンクリストの長さが閾値(デフォルトは8)を超えると赤黒木へ変換して検索時間を短縮します。なお、現在の配列の長さが64未満のときは先に配列拡張を選択してから赤黒木へ変換します。
- LinkedHashMap:LinkedHashMap は HashMap を継承しており、底層は引き続き拉链式ハッシュ構造(配列とリンクリストまたは赤黒木)です。さらに、上記構造の上に双方向リストを追加して、挿入順序と/またはアクセス順序を保持します。
- Hashtable:配列+リンクリストで構成。配列が主体、リンクリストはハッシュ衝突を解決するために存在します。
- TreeMap:赤黒木(自己平衡のソート済み二分木)。
どうやって集合を選ぶべきか?
私たちは主に集合の特性に基づいて適切な集合を選びます。
- キー値から要素値を取得する必要がある場合は Map インターフェース下の集合を選択します。並べ替えが必要なら TreeMap、不要なら HashMap、スレッドセーフを保証する場合は ConcurrentHashMap を選択します。
- 要素値のみを格納する場合は Collection インターフェースを実装したコレクションを選択します。要素の一意性を保証する必要がある場合は Set を実装したコレクション(例:TreeSet または HashSet)を選択します。不要なら List を実装した ArrayList や LinkedList を選択し、実装クラスの特性に基づいて選択します。
なぜ集合を使うのか?
データ型が同じ一群のデータを格納する必要があるとき、配列は最も一般的で基本的なコンテナの一つですが、実際には配列でオブジェクトを格納する際にいくつかの欠点があります。実際の開発では、格納データの型は多様で量も不確定です。このとき Java のコレクションが活躍します。配列と比較して、Java のコレクションは複数のデータオブジェクトを格納するためのより柔軟で効率的な方法を提供します。Java のコレクションフレームワークのさまざまな集合クラスとインターフェースは、異なる型と数のオブジェクトを格納でき、多様な操作方法を備えています。配列と比較して、サイズが可変で、ジェネリックスをサポートし、組み込みアルゴリズムを備える点がコレクションの利点です。要約すると、Java のコレクションはデータの格納と処理の柔軟性を高め、現代のソフトウェア開発における多様なデータ需要に適応し、高品質なコードの作成をサポートします。
List
ArrayList と Array(配列)の違い?
ArrayList は内部的に動的配列を基盤として実装され、Array(静的配列)よりも柔軟に使用できます。
- ArrayList は実データに応じて動的に容量を拡張または縮小しますが、Array は作成後に長さを変更できません。
- ArrayList はジェネリクスを使って型安全を確保できますが、Array はできません。
- ArrayList はオブジェクトのみを格納します。基本型を扱う場合は対応するラッパークラス(例: Integer、Double など)を使用します。Array は基本型データを直接格納することも、オブジェクトを格納することもできます。
- ArrayList は挿入・削除・走査などの通常の操作をサポートし、add()、remove() などの豊富な API 操作を提供します。Array は固定長の配列で、下位のインデックスで要素を参照するだけで、動的な追加・削除はできません。
- ArrayList の作成時にはサイズを指定する必要はありませんが、Array は作成時にサイズを指定する必要があります。
ArrayList と Vector の違い?
- ArrayList は List の主要実装クラスで、内部は Object[] を使用して格納します。頻繁な検索作業に適しており、スレッドセーフではありません。
- Vector は List の古い実装クラスで、内部は Object[] を使用して格納します。スレッドセーフです。
Vector と Stack の違い?
- Vector と Stack はどちらもスレッドセーフで、同期処理には synchronized を用います。
- Stack は Vector を継承しており、後入先出のスタックで、Vector はリストです。
Java の並行プログラミングの発展に伴い、Vector と Stack は廃止されつつあり、並行コレクション(例:ConcurrentHashMap、CopyOnWriteArrayList など)を使用するか、手動でスレッドセーフな操作を実装して安全なマルチスレッド操作を提供することが推奨されます。
ArrayList に null 値を追加できますか?
ArrayList には任意の型のオブジェクトを含めることができます。null 値も含まれます。ただし、ArrayList に null を追加することは推奨されません。null 値は意味が薄く、コードの保守性を低下させ、例えば null チェックを忘れると NullPointerException を引き起こす可能性があります。
ArrayList<String> listOfStrings = new ArrayList<>();listOfStrings.add(null);listOfStrings.add("java");System.out.println(listOfStrings);ArrayList の挿入と削除の時間計算量は?
- 挿入
- 先頭への挿入:すべての要素を後ろへ1つずつ移動する必要があるため、時間計算量は O(n)。
- 末尾への挿入:ArrayList の容量が限界に達していなければ、末尾へ追加する時間計算量は O(1)。容量が限界で拡張が必要なら、1回 O(n) の操作で元の配列を新しい大きな配列へコピーしてから要素を追加します。
- 指定位置への挿入:対象位置より後ろのすべての要素を後方へ1つ移動してから新しい要素を指定位置に置くため、平均で n/2 個の要素を移動する必要があり、O(n)。
- 削除
- 先頭削除:すべての要素を前方へ1つ移動する必要があるため、O(n)。
- 末尾削除:末尾の要素を削除する場合、O(1)。
- 指定位置削除:対象要素以降の要素を前方へ移動して空白を埋めるため、平均で n/2 個の要素を移動し、O(n)。
LinkedList の挿入と削除の時間計算量は?
- 先頭への挿入/削除:ヘッドのポインターを変更するだけで済むため、O(1)。
- 末尾への挿入/削除:テールのポインターを変更するだけで済むため、O(1)。
- 指定位置への挿入/削除:指定位置まで移動してからポインターを変更する必要があるため、平均で n/2 個の要素を移動し、O(n)。
ここでは簡単な例を挙げます。ノード 9 を削除する場合、まずリストを走査して該当ノードを見つけます。次に、対応するノードのポインターの変更を実行します。
LinkedList は RandomAccess インターフェースを実装できないのはなぜ?
RandomAccess はマーク付きインターフェースで、これを実装したクラスはランダムアクセスをサポートすることを示します。LinkedList の内部データ構造はリストで、メモリアドレスは連続していないため、インデックスで素早く位置を特定してアクセスすることができず、ランダム高速アクセスをサポートしていません。そのため RandomAccess を実装できません。
ArrayList と LinkedList の違いは?
- スレッドセーフ性の保証: ArrayList と LinkedList はどちらも同期されておらず、スレッドセーフではありません。
- 内部データ構造: ArrayList は内部で Object[] を使用します。LinkedList は内部で双方向リストを使用します(JDK1.6 以前は循環リンクリスト、JDK1.7 で循環がなくなりました。なお、双方向リストと双方向循環リストの違いに注意)。
- 挿入・削除が要素位置の影響を受けるか:
- ArrayList は配列で格納するため、挿入・削除の時間計算量は要素の位置に影響されます。例えば add(E e) は末尾への追加のケースでは O(1) ですが、指定位置 i へ挿入・削除すると O(n) になります。なぜなら、位置 i 以降の(n-i)個の要素を前後へ移動する必要があるからです。
- LinkedList はリスト構造のため、先頭・末尾への挿入・削除は位置に関係なく O(1) です(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast())。ただし、指定位置への挿入・削除(add(int index, E element)、remove(Object o)、remove(int index))は O(n) です。なぜなら、指定位置へ移動する必要があるからです。
- 高速なランダムアクセスのサポート: LinkedList は高速なランダム要素アクセスをサポートせず、ArrayList は RandomAccess を実装してサポートします。高速なランダムアクセスとは、要素の番号で要素を素早く取得すること(get(int index) に対応)。
- メモリ空間の占有: ArrayList の空間の無駄は、リストの末尾にある程度の容量を先読みして確保する点に現れ、LinkedList の空間コストは、各要素が次の直接的な後続と前続、およびデータを格納するため、一般に ArrayList より多くの空間を必要とします。
私たちのプロジェクトでは、通常 LinkedList を使うことはなく、LinkedList が必要とされる場面はほとんど ArrayList に置き換えることが可能で、通常はパフォーマンスが良いです。
また、LinkedList を「リンクリストだから挿入・削除に最適」と安易に考えないでください。上でも述べたように、LinkedList はヘッダ/テールへの挿入・削除でほぼ O(1) ですが、その他のケースでは挿入・削除の平均時間計算量は O(n) となります。
補足内容: 双方向リンクリストと双方向循環リンクリスト
- 双方向リンクリスト:2つのポインタを含み、1つは前のノードを指す prev、もう1つは次のノードを指す next。
- 双方向循環リンクリスト:最後のノードの next が head を指し、head の prev が最後のノードを指す、連結した環を形成します。
補足内容: RandomAccess インターフェース
ソースコードを見てみると RandomAccess インターフェースには何も定義されていません。ですので、私の見解では RandomAccess インターフェースは単なるマーカーです。何をマークするのかというと、それを実装するクラスがランダムアクセス機能を持つことを示します。 binarySearch() メソッドでは、引数 list が RandomAccess のインスタンスかどうかを判定します。もしそうなら indexedBinarySearch() メソッドを、そうでなければ iteratorBinarySearch() メソッドを呼び出します。
ArrayList は RandomAccess インターフェースを実装していますが、LinkedList は実装していません。なぜかというと、基盤データ構造が関係しているからです!ArrayList は内部で配列を使用し、LinkedList は内部でリストを使用します。配列は自然にランダムアクセスをサポートし、時間計算量は O(1) です。これが高速なランダムアクセスと呼ばれます。リンクリストは特定の位置の要素へアクセスするには走査が必要で、時間計算量は O(n) であり、速いランダムアクセスをサポートしません。ArrayList が RandomAccess インターフェースを実装していることは、彼が高速なランダムアクセス機能を持っていることを示します。 RandomAccess インターフェースは単なるマーカーであり、ArrayList が RandomAccess を実装しているからといって必ずしも高速なランダムアクセスが可能になるわけではありません!
ArrayList の拡張(拡張)機構について
まず ArrayList のコンストラクタから
ArrayList には初期化方法が3つあります。コンストラクタのソースコードは以下のとおりです(JDK8):
/** * 默认初期容量サイズ */private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/** * 默认のコンストラクタ、初期容量10で空リストを構築する(引数なしコンストラクタ) */public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
/** * 初期容量を指定するコンストラクタ。(ユーザーが容量を指定) */public ArrayList(int initialCapacity) { if (initialCapacity > 0) {//初期容量が0より大きい場合 //initialCapacity サイズの配列を作成 this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) {//初期容量が0の場合 //空配列を作成 this.elementData = EMPTY_ELEMENTDATA; } else {//初期容量が負の場合、例外を投げる throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity); }}
/** *构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回 *如果指定的集合为null,throws NullPointerException。 */public ArrayList(Collection<? extends E> c) { elementData = c.toArray(); if ((size = elementData.length) != 0) { // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class); } else { // replace with empty array. this.elementData = EMPTY_ELEMENTDATA; }}無引数コンストラクタで ArrayList を作成すると、実際には空の配列を初期化します。実際に配列へ要素を追加する操作が行われる時に初めて容量が割り当てられます。つまり、配列に最初の要素を追加すると容量が 10 へ拡張されます。
補足:JDK6 の new 無参構造の ArrayList オブジェクトは、長さ 10 の Object[] 配列 elementData を直接作成しました。
一歩ずつ分析 ArrayList 拡張機構
無参構造関数で作成された ArrayList を例に、add メソッドを分析します。
/*** 将指定された要素をこのリストの末尾に追加します。*/public boolean add(E e) { // 要素を追加する前に ensureCapacityInternal メソッドを呼び出す ensureCapacityInternal(size + 1); // modCount をインクリメント!! // ここで配列へ要素を代入する処理になる elementData[size++] = e; return true;}注意:JDK11 では ensureCapacityInternal() と ensureExplicitCapacity() メソッドは削除されました
ensureCapacityInternal メソッドのソースは以下のとおりです:
// 最小容量 minCapacity を与えられた場合の必要容量を計算するprivate static int calculateCapacity(Object[] elementData, int minCapacity) { // 現在の配列が空配列(初期状態)であればデフォルト容量と最小容量の大きい方を必要容量として返す if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { return Math.max(DEFAULT_CAPACITY, minCapacity); } // それ以外は minCapacity を返す return minCapacity;}
// 内部容量を指定の最小容量に達するように確保するprivate void ensureCapacityInternal(int minCapacity) { ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}
// 容量が足りるかどうかを判断するprivate void ensureExplicitCapacity(int minCapacity) { modCount++; // 現在の配列容量が minCapacity より小さい場合、拡張を実行 if (minCapacity - elementData.length > 0) // growメソッドを呼び出して拡張 grow(minCapacity);}詳しく分析すると:
- 最初の 1 個目の要素を add する時、elementData.length は 0 です(空のリストのままのため)。この時 ensureCapacityInternal() が実行されるので、minCapacity は 10 になります。このとき minCapacity - elementData.length > 0 が成立し、grow(minCapacity) が呼び出されます。
- 2 番目の要素を add する時、minCapacity は 2 ですが、1 個目の要素を追加した後に容量が 10 に拡張されているため、minCapacity - elementData.length > 0 は成立せず、grow(minCapacity) は呼ばれません。
- 11 番目の要素を追加する時には minCapacity が 11 となり、elementData.length は 10 を超えます。grow メソッドを呼び出して拡張します。
grow メソッド
/** * 要割り当ての最大配列サイズ */private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/** * ArrayList 拡張の核心メソッド。 */private void grow(int minCapacity) { // oldCapacity は旧容量、newCapacity は新容量 int oldCapacity = elementData.length; // oldCapacity を右シフト1しており、oldCapacity / 2 に相当 // ビット演算の方が除算より速いため、結果として新容量を旧容量の1.5倍に更新します int newCapacity = oldCapacity + (oldCapacity >> 1);
// 新容量が最小必要容量より小さい場合、minCapacity を新容量とする if (newCapacity - minCapacity < 0) newCapacity = minCapacity;
// 新容量が MAX_ARRAY_SIZE を超える場合、hugeCapacity() を呼び出して minCapacity と MAX_ARRAY_SIZE を比較 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity);
// minCapacity はサイズに近いことが多いのでこの最適化は有効: elementData = Arrays.copyOf(elementData, newCapacity);}int newCapacity = oldCapacity + (oldCapacity >> 1) なので、ArrayList は容量を 1.5 倍ずつ拡張します(oldCapacity が偶数なら 1.5 倍、そうでなければ±1 近くで 1.5 倍程度)。
grow() メソッドの例を通して見ると:
- 要素が 1 個目のとき、oldCapacity は 0、最初の if が成立し minCapacity が 10 となる。second if は MAX_ARRAY_SIZE 未満のため成立せず、容量は 10、add は true を返し、size は 1 になります。
- 11 番目の要素を追加する時、newCapacity は 15 となり minCapacity(11)より大きいので first if は成立せず、MAX_ARRAY_SIZE 未満なので hugeCapacity は呼ばれず、容量は 15、size は 11 となります。
ここで重要な点を補足します:
- Java の length プロパティは配列を指します。宣言した配列の長さを知りたい場合は length を使います。
- Java の length() メソッドは文字列を指します。文字列の長さを知りたい場合は length() を使います。
- Java の size() メソッドはジェネリックコレクションを指します。コレクションの要素数を知りたい場合は size() を呼び出します。
hugeCapacity() メソッド
private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); // minCapacity と MAX_ARRAY_SIZE を比較 // minCapacity が最大を超えた場合は Integer.MAX_VALUE を新配列のサイズとする // MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;}Set
Comparable と Comparator の違い
Comparable インターフェースと Comparator インターフェースは、Java でのソートに使用されるインターフェースです。クラスのオブジェクト同士を比較して順序付けを行う点で重要です。
- Comparable インターフェースは java.lang パッケージにあり、compareTo(Object obj) メソッドを持ってソートを行います。
- Comparator インターフェースは java.util パッケージにあり、compare(Object obj1, Object obj2) メソッドを持ってソートを行います。
通常、コレクションに対して独自のソートを適用したい場合は compareTo() メソッドをオーバーライドするか、compare() メソッドを持つ Comparator を使用します。あるコレクションに対して2種類のソートを実現したい場合、例えば song オブジェクトの曲名とアーティスト名の両方で別のソートを行う場合、compareTo() のオーバーライドと自作の Comparator の利用、または2つの Comparator を用いて曲名順とアーティスト名順を実装します。後者は Collections.sort() の2引数版のみで実現できます。
Comparator によるカスタムソート
ArrayList<Integer> arrayList = new ArrayList<Integer>();arrayList.add(-1);arrayList.add(3);arrayList.add(3);arrayList.add(-5);arrayList.add(7);arrayList.add(4);arrayList.add(-9);arrayList.add(-7);System.out.println("原始配列:");System.out.println(arrayList);// void reverse(List list):反転Collections.reverse(arrayList);System.out.println("Collections.reverse(arrayList):");System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序Collections.sort(arrayList);System.out.println("Collections.sort(arrayList):");System.out.println(arrayList);// 定制排序の使用Collections.sort(arrayList, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2.compareTo(o1); }});System.out.println("定制排序後:");System.out.println(arrayList);無秩序性と重複不可性の意味は何か
- 無秩序性はランダム性と等しくはない。無秩序性とは、底層配列にデータを追加する順序が配列インデックスの順序ではなく、データのハッシュ値に基づいて決定されることを指します。
- 重複不可性とは、追加される要素が equals() の判定で false を返す場合、equals() と hashCode() の両方を再定義する必要があることを指します。
HashSet、LinkedHashSet、TreeSet の違いと共通点
- HashSet、LinkedHashSet、TreeSet はすべて Set インターフェースの実装クラスで、要素の一意性を保証します。いずれもスレッドセーフではありません。
- HashSet、LinkedHashSet、TreeSet の主な違いは、基盤データ構造が異なる点です。HashSet はハッシュテーブル(HashMap を基盤とする)を使用します。LinkedHashSet は LinkedHashMap を基盤とし、挿入・取得順序を保持します。TreeSet は赤黒木(自動平衡なソート済み二分木)を基盤とし、要素は有序です。自然順序かカスタムソートかで分類されます。
- 基盤データ構造が異なるため、用途も異なります。HashSet は挿入・取得の順序を保証しない場面、LinkedHashSet は挿入順の順序を保証する場面、TreeSet は要素をカスタムソートルールで並べたい場面で有効です。
Queue
Queue と Deque の違い
Queue は片側キューで、片側からのみ要素を挿入し、もう一方の端から削除します。実装上は一般的に先入れ先出し(FIFO)ルールに従います。
Queue は Collection のインターフェースを拡張します。容量の問題により操作が失敗した場合の処理方法の差異により、2つのカテゴリのメソッドに分けられます。1つは操作失敗時に例外を投げるもので、もう1つは特別な値を返します。
| Queue インターフェース | 例外を投げる | 特殊値を返す |
|---|---|---|
| 末尾への挿入 | add(E e) | offer(E e) |
| 先頭の削除 | remove() | poll() |
| 先頭要素の参照 | element() | peek() |
Deque は両端キューで、両端のいずれかで挿入・削除が可能です。
Deque は Queue のインターフェースを拡張し、先頭と末尾での挿入・削除のメソッドを追加します。失敗時の処理方法の違いにより、同様に2つのカテゴリに分かれます。
| Deque インターフェース | 例外を投げる | 特殊値を返す |
|---|---|---|
| 先頭への挿入 | addFirst(E e) | offerFirst(E e) |
| 末尾への挿入 | addLast(E e) | offerLast(E e) |
| 先頭の削除 | removeFirst() | pollFirst() |
| 末尾の削除 | removeLast() | pollLast() |
| 先頭要素の参照 | getFirst() | peekFirst() |
| 末尾要素の参照 | getLast() | peekLast() |
実際には Deque は push() や pop() などの他のメソッドも提供しており、スタックの模倣にも使用できます。
ArrayDeque と LinkedList の違い
ArrayDeque と LinkedList はいずれも Deque インターフェースを実装しており、両方ともキュー機能を提供しますが、違いは何でしょうか?
- ArrayDeque は可変長の配列とダブルポインタを用いて実装され、LinkedList はリストを用いて実装されます。
- ArrayDeque は NULL データを格納できませんが、LinkedList は格納できます。
- ArrayDeque は JDK1.6 で導入され、LinkedList は JDK1.2 から存在します。
- ArrayDeque の挿入には拡張が生じる場合がありますが、アベレージの挿入は依然として O(1) です。LinkedList は拡張を必要としませんが、データを挿入するたびに新しいヒープ領域を確保する必要があるため、平均性能は低くなる傾向があります。
性能の観点から、キューの実装には ArrayDeque を選ぶ方が LinkedList より良いです。さらに ArrayDeque はスタックの実装にも利用できます。
PriorityQueue について
PriorityQueue は JDK1.5 で導入され、Queue との違いは要素の出隊順が優先順位に関連している点です。常に最高優先度の要素が先に出隊します。
- PriorityQueue は二分ヒープのデータ構造を利用して実装され、底層は可変長の配列を用いてデータを格納します。
- ヒープ要素の「上昇」および「沈下」を通じて、要素の挿入とヒープトップの削除を O(log n) の時間計算量で実現します。
- PriorityQueue は非スレッドセーフで、NULL および非比較可能(non-comparable)なオブジェクトの格納をサポートしていません。
- PriorityQueue はデフォルトで小さな値を優先しますが、構築時に Comparator を渡すことにより、要素の優先順位の先後をカスタマイズできます。
PriorityQueue は面接などでアルゴリズムの練習時に頻出され、典型的な問題としてヒープソート、K番目の数の取得、重み付きグラフの走行などが挙げられます。そのため、使いこなすことが求められます。
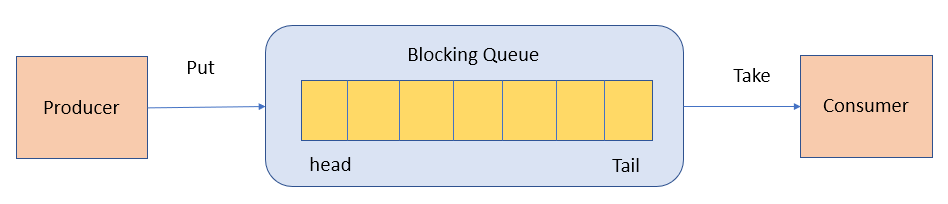
BlockingQueue とは?
BlockingQueue(ブロッキングキュー)は Queue を継承するインターフェースです。BlockingQueue がブロックされる理由は、キューに要素がない場合は要素が入るまでブロックを続け、またキューが満杯で新しい要素を投入できる状態になるまで待機する機能をサポートしている点です。
public interface BlockingQueue<E> extends Queue<E> { // ...}BlockingQueue は生産者-消費者モデルでよく用いられます。生産者スレッドはキューにデータを追加し、消費者スレッドはキューからデータを取り出して処理します。
BlockingQueue の実装クラスは何がある?
Java でよく使われるブロッキングキューの実装クラスは以下のとおりです:
- ArrayBlockingQueue:配列を用いた有界ブロッキングキュー。容量を作成時に指定する必要があり、公平性と非公平性の両方のロックアクセス機構をサポートします。
- LinkedBlockingQueue:単方向リンクリストを用いた任意の有界ブロッキングキュー。容量を作成時に指定可能で、指定しなければ Integer.MAX_VALUE がデフォルトです。ArrayBlockingQueue と異なり、非公平なロックアクセス機構のみをサポートします。
- PriorityBlockingQueue:優先順位付けされた無界ブロッキングキュー。要素は Comparable を実装するか、コンストラクタで Comparator を渡す必要があり、null 要素の挿入はできません。
- SynchronousQueue:同期キューで、要素を格納することはありません。挿入操作は対応する削除操作を待機し、削除操作も挿入操作を待機します。したがって、SynchronousQueue は通常、スレッド間のデータの直接伝達に使用されます。
- DelayQueue:遅延キュー。要素は指定された遅延時間が経過したときのみキューから取り出せます。
ArrayBlockingQueue と LinkedBlockingQueue の違いは?
ArrayBlockingQueue と LinkedBlockingQueue は Java の並行パッケージでよく使われるブロッキングキュー実装で、いずれもスレッドセーフです。しかし、以下の違いもあります:
- 基盤実装:ArrayBlockingQueue は配列を基盤とします。LinkedBlockingQueue はリンクリストを基盤とします。
- 有界性:ArrayBlockingQueue は有界で、作成時に容量を指定する必要があります。LinkedBlockingQueue は作成時に容量を指定しなくても良く、デフォルトは Integer.MAX_VALUE、つまり無界です。ただし、容量を指定して有界にすることも可能です。
- ロックの分離:ArrayBlockingQueue のロックは分離されていません。生産と消費は同じロックを使用します。LinkedBlockingQueue のロックは分離されており、生産は putLock、消費は takeLock を使用します。これにより生産者と消費者スレッド間のロック競合を防ぎます。
- メモリ使用量:ArrayBlockingQueue は事前に配列メモリを割り当てる必要があり、LinkedBlockingQueue はノードメモリを動的に割り当てます。これにより、ArrayBlockingQueue は作成時に一定のメモリを消費しますが、通常実メモリよりも大きくなる傾向があり、LinkedBlockingQueue は要素の増加に応じてメモリを徐々に使用します。
Map(重要)
HashMap と Hashtable の違い
- スレッドセーフ性: HashMap は非スレッドセーフ、Hashtable はスレッドセーフです。Hashtable の内部のほとんどのメソッドは synchronized 修飾されているためです。(スレッドセーフを保証したい場合は ConcurrentHashMap を使用してください)
- 効率: スレッドセーフの問題のため、HashMap の方が Hashtable より効率的です。Hashtable は基本的に廃止されつつあり、コードでの使用は避けてください。
- Null のキーと値の扱い: HashMap は null のキーと値を格納できますが、キーとしての null は1個のみ、値としての null は複数格納可能です。Hashtable は null キーと null 値を許容せず、そうすると NullPointerException がスローされます。
- 初期容量と拡張規則の違い:
- 初期値を指定しない場合、Hashtable のデフォルト初期サイズは 11、拡張時は容量が元の 2n+1 になります。HashMap のデフォルト初期サイズは 16。以降、拡張時は容量が元の2倍になります。
- 初期容量を指定した場合、Hashtable はそのサイズを直接使用しますが、HashMap は 2 のべき乗のサイズへ拡張します。
- 底層データ構造:JDK1.8 以降の HashMap はハッシュ衝突解決に大きな変化があり、リンクリストの長さが閾値(デフォルトは8)を超えると赤黒木へ変換して検索時間を短縮します(ただし現在の配列長が64未満のときはまず配列拡張を選択してから変換します)。Hashtable にはこのような仕組みはありません。
HashMap と HashSet の違い
HashSet の元となる実装を見たことがあるなら、HashSet の底層は HashMap を基盤としていることが分かるでしょう。(HashSet のソースは非常に少なく、clone()、writeObject()、readObject() 以外はほとんど HashMap のメソッドを直接呼び出します)。
| HashMap | HashSet |
|---|---|
| Map インターフェースを実装 | Set インターフェースを実装 |
| キーと値のペアを格納 | 要素のみを格納 |
| put() を呼び出して要素を追加 | add() を呼び出してセットに要素を追加 |
| HashMap はキー(Key)で hashcode を計算 | HashSet はメンバーオブジェクトの hashcode 値を用いて計算、hashcode が同じ場合は equals() で同一性を判断 |
HashMap と TreeMap の違い
TreeMap は HashMap に対して、キー順序による自動ソートという追加機能を提供します。
TreeMap と HashMap は AbstractMap を継承しますが、TreeMap は NavigableMap インターフェースと SortedMap インターフェースを実装しています。
- NavigableMap インターフェースを実装することで、TreeMap は集合内の要素をキーで検索する能力を持ちます。
- SortedMap インターフェースを実装することで、TreeMap は要素をキーの順序で並べ替える能力を持ちます。デフォルトはキーの昇順ですが、比較器を指定することもできます。
要約すると、HashMap に比べ TreeMap は、キーに基づくソート機能と集合内要素の検索機能を追加で持つ点が特徴です。
HashSet が重複を検出する方法は?
オブジェクトを HashSet に追加すると、HashSet はまず对象の hashCode を計算して追加位置を決定します。さらに、他の追加済みオブジェクトの hashCode と比較します。hashCode が異なれば重褄はないと判断します。ただし、同じ hashCode 値を持つ要素が見つかった場合には、equals() を呼び出して hashCode が等しい要素が実際に同じかどうかを検査します。もし同じなら、追加操作は成功しません。
JDK1.8 では、HashSet の add() は単に HashMap の put() を呼び出すだけで、戻り値を見て重複があるかどうかを判断します。HashSet のソースを見てみましょう:
// Returns: true if this set did not already contain the specified element// 返回值:set に指定要素が含まれていなければ truepublic boolean add(E e) { return map.put(e, PRESENT)==null;}つまり、JDK1.8 では HashSet がすでに同一要素を含んでいるかどうかに関係なく、要素を直接追加します。ただし、add() の戻り値で挿入前に同一要素が存在したかを示します。
HashMap の底層実装
JDK1.8 以前
JDK1.8 以前は HashMap は配列とリストの組み合わせ、つまり ライ Hash(チェーン法)です。HashMap はキーの hashCode を用いてハッシュ値を得た後、(n - 1) & hash の演算で現在の要素の格納場所を判断します(n は配列の長さ)。もし現在の場所に要素があれば、その要素のハッシュ値とキーが同一かを判定します。等しければ上書き、そうでなければチェーン法で衝突を解決します。
所谓扰动函数とは HashMap の hash メソッドを指します。ハッシュコードの衝突を抑制するためのものです。
static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4);}JDK1.8 HashMap
JDK 1.8 の hash メソッドは JDK 1.7 のそれより簡略化されていますが、原理は変わっていません。
static final int hash(Object key) { int h; // key.hashCode():ハッシュ値、すなわち hashcode // ^:ビットごとの排他的 OR // >>>: 符号なし右シフト、符号ビットを無視、空きは 0 で補完 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }1.8 の hash メソッドは 1.7 のものより若干高速ですが、衝突の処理自体は同じ原理です。
「拉链法」ことは:リンクリストと配列を組み合わせた構造です。つまり、配列の各格子にリンクリストを格納するという形です。衝突が発生した場合には、衝突した値をリンクリストに追加します。
JDK1.8 以降
以前のバージョンと比較すると、JDK1.8 以降ではハッシュ衝突の解決方法に大きな変化があり、リンクリストの長さが閾値(デフォルトは 8)を超えた場合、リンクリストを赤黒木へ変換して検索時間を短縮します(現在の配列長が 64 未満の場合は先に配列を拡張してから変換します)。
TreeMap、TreeSet および JDK1.8 以降の HashMap の底層は全て赤黒木を用います。赤黒木は二分探索木の欠陥を解決するための構造で、二分探索木が状況によって線形構造へ退化するのを回避します。
HashMap のリンクリストを赤黒木へ変換するプロセスをソースコードとともに見ていきます。
- putVal メソッド内でリンクリストを赤黒木へ変換する判定ロジック。リンクリストの長さが 8 を超える場合、treeifyBin(赤黒木への変換)ロジックを実行します。
for (int binCount = 0; ; ++binCount) { // リストの最後のノードに到達 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 要素数が TREEIFY_THRESHOLD (8) 以上 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st // 赤黒木への変換(直接赤黒木へは変換しない) treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e;}- treeifyBin メソッドで本当に赤黒木へ変換するか判断します。
final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; // 現在の配列長が 64 未満ならまずは配列を拡張 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); }}リンクリストを赤黒木へ変換する前に、現在の配列長が 64 未満ならまず配列を拡張します。
HashMap の長さがなぜ 2 のべき乗なのか
HashMap の目的はデータを高効率で取得することです。ハッシュ値の範囲は -2147483648 〜 2147483647 と大きい範囲ですが、実際にはこの 40 億程度の範囲を そのまま配列のインデックスとして使えるわけではありません。インデックスを求めるには「(n - 1) & hash」という演算を用います(n は配列長)。このように、HashMap の長さが 2 のべき乗になる理由は、ハッシュ値を配列のインデックスとして割り当てる際の計算を効率化するためです。
この設計をどう思いつくかというと、換言すると「余り(% 演算)」を用いるよりも、2 のべき乗長を使い「hash & (length - 1)」でインデックスを求める方が高速であるためです。これが HashMap の長さが 2 のべき乗になる理由です。
HashMap の多重スレッド操作によるデッドループの問題
JDK1.7 以前の HashMap では、多スレッド環境での拡張時にデッドループが発生する可能性がありました。1つのバケツ(桶)に複数の要素を拡張する必要がある場合、複数スレッドが同時にリンクリストを操作すると、ヘッド挿入法が原因でノードが誤った位置を指してしまい、循環するリンクリストを形成して検索が無限ループに陥ることがありました。
この問題を解決するため、JDK1.8 ではヘッド挿入法を廃し、尾部挿入法を採用してリンクリストの倒立を回避し、挿入されるノードを常にリストの末尾に配置するようにしました。しかし、それでも並行性のある状況で HashMap の使用は推奨されず、データの上書きなどの問題が発生する可能性があります。並行環境では ConcurrentHashMap を使用することを推奨します。
HashMap がスレッドセーフでない理由は?
JDK1.7 およびそれ以前のバージョンでは、多重スレッド環境での HashMap の拡張時にデッドループとデータ損失の問題が発生しました。
JDK1.8 以降、HashMap では複数のキー/値が同じバケツに割り当てられることがあります。複数のスレッドが put を実行することでデータが上書きされるリスクがあり、サイズの上昇にともなって局所的な上書きが起こる可能性があります。
以下のような例が挙げられます:
- 2つのスレッド 1,2 が同時に put 操作を実行し、ハッシュ衝突が発生する。
- 時間片の切替えにより、スレッド 1 がハッシュ衝突の判断後に中断され、スレッド 2 が挿入を完了する。
- 後にスレッド 1 が再開し、既に衝突が解決済みのため直ちに挿入を行い、スレッド 2 の挿入データを上書きしてしまう。
別のケースとして size が正しく増加しないことによるデータの上書きが起こることもあります。複数スレッドが同時に put を行う場合、size が 1 増えるだけで済むためです。
多くの場合、並行環境では ConcurrentHashMap の利用を推奨します。
ConcurrentHashMap は複合操作の原子性を保証しますか?
ConcurrentHashMap はスレッドセーフであり、複数のスレッドが同時に読み取り/書き込みを行ってもデータの一貫性を保つよう設計されています。しかし、すべての複合操作が原子で保証されるわけではありません。混同しないでください!
複合操作とは、 put、get、remove、containsKey などの複数の基本操作から構成される操作のことです。例えば、あるキーが存在するかを first checking containsKey(key) し、その結果に基づいて put(key, value) する、といったケースです。このような操作は実行途中で他のスレッドに中断され得るため、期待通りには動作しません。
どうすれば ConcurrentHashMap の複合操作の原子性を確保できるかというと、putIfAbsent、compute、computeIfAbsent、computeIfPresent、merge などの原子的な複合操作を提供する手段を使用します。これらのメソッドは、キーと値を受け取り、新しい値を計算して map に更新します。
このようなケースではロックを使って同期を取ることも可能ですが、ConcurrentHashMap の設計趣旨に反するため推奨されません。可能な限り、これらの原子性の複合操作を使用して原子性を保証してください。
Collections ツール類(重要ではない)
Collections ツールクラスのよく使われるメソッド:
- ソート
- 検索・置換操作
- 同期制御(不要、スレッドセーフな集合が必要な場合は JUC パッケージの並行コレクションを検討してください)
ソート操作
void reverse(List list) // 反転void shuffle(List list) // シャッフル(ランダム)void sort(List list) // 自然順序の昇順でソートvoid sort(List list, Comparator c) // カスタムソート、ソートロジックは Comparator によって決定void swap(List list, int i , int j) // 2つのインデックスの要素を交換void rotate(List list, int distance) // 回転。distance が正なら list の後ろの distance 個の要素を前に移動、負なら前の distance 個を後ろに移動検索・置換操作
int binarySearch(List list, Object key) // List を二分探索、List は有序でなければならないint max(Collection coll) // 自然順で最大要素を返すint max(Collection coll, Comparator c) // カスタムソートで最大要素を返すvoid fill(List list, Object obj) // 指定した要素でリスト内の全要素を置換int frequency(Collection c, Object o) // 出現回数を数えるint indexOfSubList(List list, List target) // target が list 内で最初に出現するインデックスを返す。見つからなければ -1boolean replaceAll(List list, Object oldVal, Object newVal) // 旧要素を新要素で置換同期制御
Collections は複数の synchronizedXxx() メソッドを提供します。これにより、指定したコレクションをスレッド同期化されたコレクションとしてラップし、複数スレッド間の同時アクセス時にスレッドセーフ問題を解決します。
我々は HashSet、TreeSet、ArrayList、LinkedList、HashMap、TreeMap がすべてスレッドセーフでないことを知っています。Collections はそれらをスレッド同期化されたコレクションとしてラップする静的メソッドを複数提供します。
以下の方法は効率が非常に低く、推奨されません。スレッドセーフなコレクションが必要な場合は、JUC パッケージの並行コレクションを検討してください。
synchronizedCollection(Collection<T> c) // 指定の collection をスレッドセーフな Collection にラップして返すsynchronizedList(List<T> list) // 指定の List をスレッドセーフな List にラップして返すsynchronizedMap(Map<K,V> m) // 指定の Map をスレッドセーフな Map にラップして返すsynchronizedSet(Set<T> s) // 指定の Set をスレッドセーフな Set にラップして返すこの記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります