


















マイクロサービスの理解
モノリシックアーキテクチャ
ビジネスのすべての機能を1つのプロジェクトに集中して開発し、1つのパッケージとしてデプロイする。
利点:
- アーキテクチャが単純
- デプロイコストが低い
欠点:
- 結合度が高い(保守が難しい、アップグレードが難しい)
分散アーキテクチャ
ビジネス機能に基づいてシステムを分割し、各ビジネス機能モジュールを独立したプロジェクトとして開発します。これを1つのサービスと呼ぶ。
利点:
- サービス間の結合を低減
- サービスのアップグレードと拡張に有利
欠点:
- サービス呼び出し関係が複雑になる
分散アーキテクチャは確かにサービスの結合を低減しますが、サービスを分割する際には考えるべき問題が多くあります:
- サービス分割の粒度をどう定義するか?
- サービス間はどう呼び出すのか?
- サービスの呼び出し関係をどう管理するのか?
人々は分散アーキテクチャを制約するための実効的な標準を制定する必要があります。
マイクロサービス
マイクロサービスのアーキテクチャの特徴:
- 単一責務:マイクロサービスは粒度がより小さく、各サービスが唯一のビジネス能力を持ち、単一責務を実現します
- 自治:チーム独立、技術独立、データ独立、独立デプロイとデリバリー
- サービス指向:サービスは統一された標準インターフェースを提供し、言語や技術に依存しない
- 隔離性が高い:サービス呼び出しは隔離・フォールトトレランス・降格を適切に実施し、連鎖的な問題を回避
上述の特性は、分散アーキテクチャに対して標準を設定し、サービス間の結合をさらに低減し、サービスの独立性と柔軟性を提供することを目的としています。高い内聚、低い結合を実現します。
したがって、マイクロサービスは、良好なアーキテクチャ設計を経た、分散アーキテクチャのソリューションとみなすことができます。
SpringCloud
SpringCloudは現在国内で最も広く使われているマイクロサービスフレームワークです。公式サイト:https://spring.io/projects/spring-cloud。
SpringCloudはさまざまなマイクロサービス機能コンポーネントを統合し、SpringBootを基盤としてこれらのコンポーネントの自動設定を実現することで、良好な「箱から出してすぐ使える」体験を提供します。
コンポーネントには:
- サービス登録・発見:
Eureka、Nacos、Consul - サービスリモート呼び出し:
OpenFeign、Dubbo - サービストレースモニタリング:
Zipkin、Sleuth - 統一設定管理:
SpringCloudConfig、Nacos - 統一ゲートウェイルーティング:
SpringCloudGateway、Zuul - レート制御、降格、保護:
Hystix、Sentinel
サービスの分割と遠隔呼び出し
サービス分割の原則:
- 異なるマイクロサービス間で同じビジネスを重複して開発しない
- マイクロサービスごとにデータを独立させ、他のマイクロサービスのデータベースへアクセスしない
- マイクロサービスは自分のビジネスをインターフェースとして公開し、他のマイクロサービスから呼び出せるようにする
サービス間の遠隔呼び出し
RestTemplateを呼び出して実現します
-
起動時にRestTemplateのインスタンスを登録する
@Beanpublic RestTemplate restTemplate() {return new RestTemplate();} -
サービス側の呼び出し
@Autowiredprivate RestTemplate restTemplate;public Order queryOrderById(Long orderId) {// 1.注文を取得Order order = orderMapper.findById(orderId);// 2. ユーザーをリモート照会String url = "<http://localhost:8081/user/>" + order.getUserId();User user = restTemplate.getForObject(url, User.class);// 3. orderに格納order.setUser(user);// 4. 返却return order;}
提供者と消費者
サービス呼び出し関係には2つの異なる役割があります:
サービス提供者:他のマイクロサービスから呼び出されるサービス。(他のマイクロサービスへ接口を提供)
サービス消費者:他のマイクロサービスを呼び出すサービス。(他のマイクロサービスが提供するインターフェースを呼び出す)
Eureka登録センター
Eurekaの構成と役割
登録センターは、消費者がリモート呼び出しを行う際、複数のインスタンスとして実行されているサービス提供者を解決するために使用します。
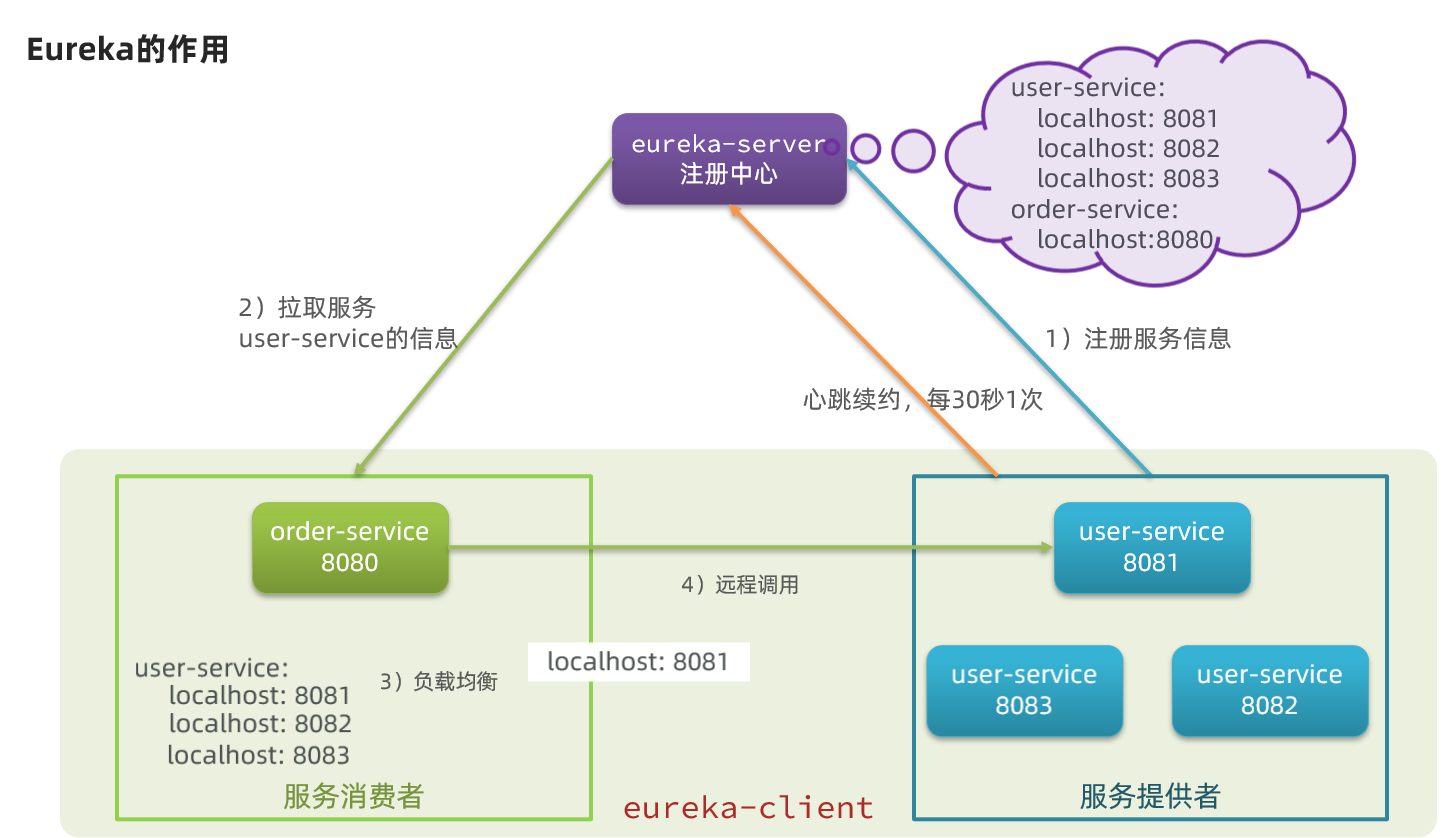
- 問題1:order-serviceはuser-serviceのインスタンスアドレスをどう知るのか?
- user-serviceのインスタンスが起動すると、自分の情報をeureka-server(Eurekaサーバ)に登録します。これをサービス登録と呼ぶ
- eureka-serverはサービス名とサービスインスタンスアドレスのリストの対応を保持します
- order-serviceはサービス名に基づいてインスタンスアドレスリストを取得します。これをサービス発見またはサービスプルと呼ぶ
- 問題2:order-serviceは複数のuser-serviceインスタンスのうちどの具体的なインスタンスを選ぶのか?
- order-serviceはインスタンスリストからロードバランシングアルゴリズムを用いて1つのインスタンスアドレスを選ぶ
- そのインスタンスアドレスに対してリモート呼び出しを行う
- 問題3:order-serviceはあるuser-serviceインスタンスが依然として健全か、落ちていないかをどう知るのか?
- user-serviceは一定の間隔(デフォルト30秒)でeureka-serverに心拍を送信して自分の状態を報告する
- 心拍が一定時間受信されない場合、eureka-serverはマイクロサービスインスタンスを故障とみなし、サービスリストから除外する
- サービスを取得する際、故障したインスタンスは除外される
Eureka-Serverの構築
- Eureka-Serverサービスを作成
親プロジェクトの下にサブモジュールを作成し、Mavenプロジェクトとする
- Eureka依存を導入 - server
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency>- 起動クラスを作成
@EnableEurekaServerアノテーションを付与して、Eureka登録センター機能を有効化する
@SpringBootApplication@EnableEurekaServerpublic class EurekaApplication { public static void main(String[] args) { SpringApplication.run(EurekaApplication.class, args); }}- 設定ファイルを作成
server: port: 10086spring: application: name: eureka-servereureka: client: service-url: defaultZone: <http://127.0.0.1:10086/eureka>- サービスを起動
設定したEurekaサービスパスにアクセス
サービス登録
- 依存導入 - client
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>- 設定ファイル
spring: application: name: userserviceeureka: client: service-url: defaultZone: <http://127.0.0.1:10086/eureka>- 複数のサービスインスタンスを起動
SpringBootの起動設定を複製し、VMオプションで-Dserver.port=8082を設定
サービス発見
消費者であるorder-serviceの前述2点は提供者と同様です。
- サービス取得とロードバランシング
ロードバランシング:restTemplateのBeanに@LoadBalancedアノテーションを追加すればよい
@Bean@LoadBalancedpublic RestTemplate restTemplate(){ return new RestTemplate();}取得するサービス:
public Order queryOrderById(Long orderId) { // 1.注文を取得 Order order = orderMapper.findById(orderId); // 2. 远程查询User// String url = "<http://localhost:8081/user/>" + order.getUserId(); String url = "<http://userservice/user/>" + order.getUserId(); User user = restTemplate.getForObject(url, User.class); // 3. 存入order order.setUser(user); // 4.返回 return order;}springは自動的にeureka-server端からuserserviceというサービス名のインスタンスリストを取得し、その後ロードバランシングを実行します。
Ribbonロードバランシング
ロードバランシングの原理
SpringCloudの下層はRibbonと呼ばれるコンポーネントを利用してロードバランシング機能を実現しています。
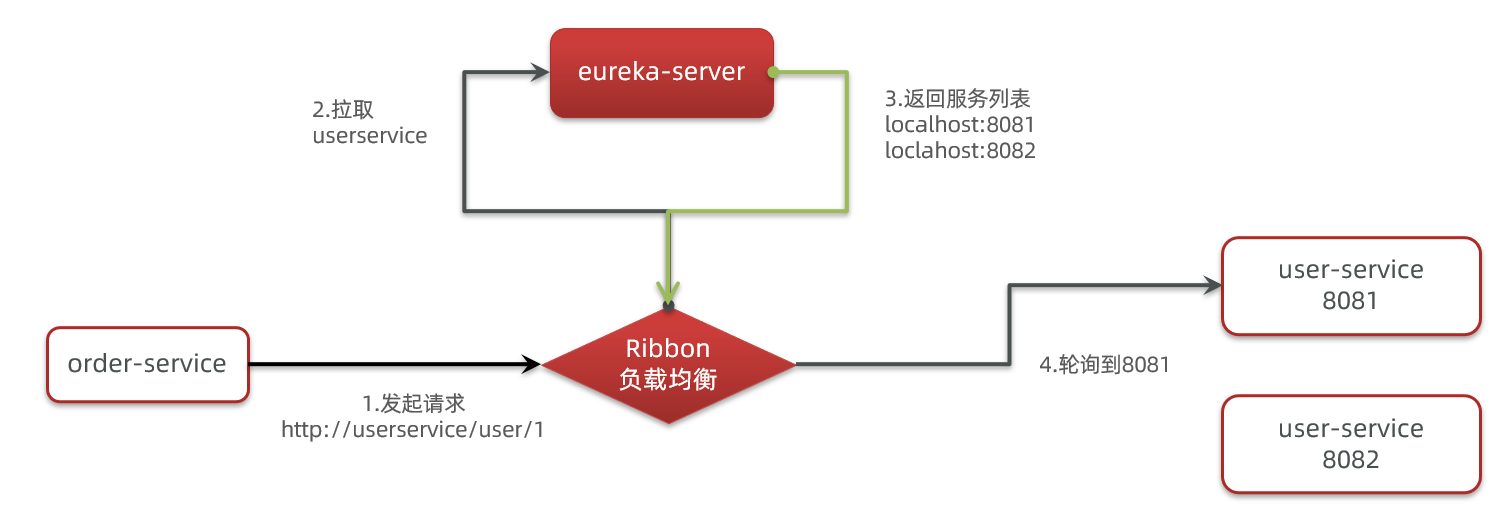
SpringCloudの実装
SpringCloudRibbonの下層はインターセプターを用いて、RestTemplateが発行するリクエストを横取りし、アドレスを変更します。
基本的な流れは次のとおりです:
- 私たちの
RestTemplateリクエスト http://userservice/user/1 をインターセプト RibbonLoadBalancerClientはリクエストのurlからサービス名を取得、つまりuser-serviceDynamicServerListLoadBalancerはuser-serviceに基づいてeurekaからサービスリストを取得- eurekaがリストを返す、localhost<8081>、localhost<8082>
IRuleは内蔵のロードバランシングルールを用いてリストから1つを選択、例えば localhost<8081>RibbonLoadBalancerClientはリクエストURLを修正し、localhost<8081を>userserviceの代わりに置換して、http://localhost:8081/user/1 にして実際のリクエストを送信
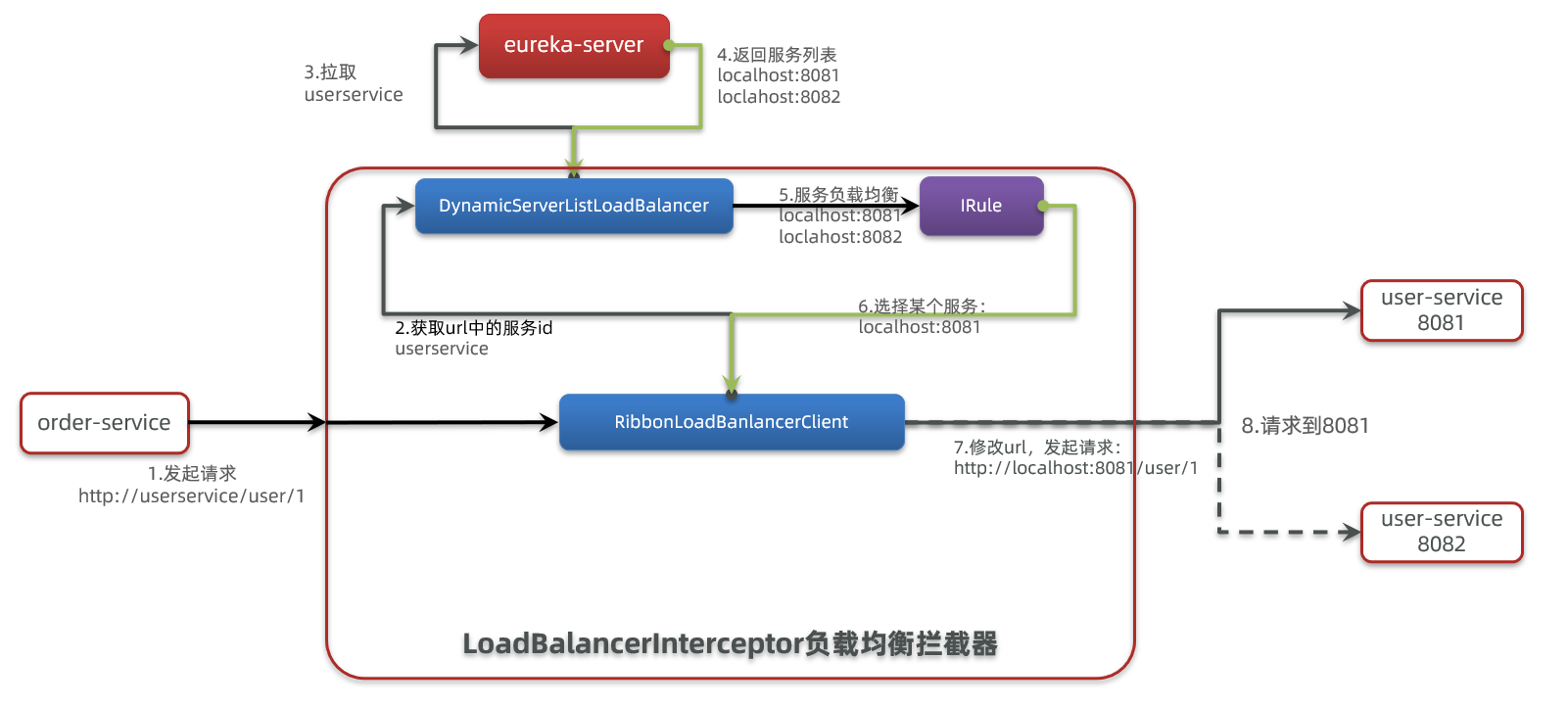
ロードバランシング戦略
ロードバランシングのルールはすべてIRuleインタフェースに定義されており、IRuleにはさまざまな実装クラスがあります。
| 内蔵ロードバランス規則クラス | 規則の説明 |
|---|---|
| RoundRobinRule | サービスリストを単純に循環させてサーバを選択します。Ribbonのデフォルトのロードバランシング規則です。 |
| AvailabilityFilteringRule | 以下の2つのサーバを無視します: (1)デフォルトでは、このサーバが3回接続失敗すると「回避」状態に設定されます。回避状態は30秒継続し、再接続失敗時には回避の継続時間が幾何的に増加します。 (2)同時接続数が過大なサーバ。もしサーバの同時接続数が過大であれば、AvailabilityFilteringRule規則を適用しているクライアントもそれを無視します。並列接続数の上限は、クライアントの |
| WeightedResponseTimeRule | 各サーバに重みを割り当て、サーバの応答時間が長いほどそのサーバの重みを小さくします。この規則はサーバをランダムに選択しますが、重みが選択に影響します。 |
| ZoneAvoidanceRule | 利用可能なゾーンを基にサーバを選択します。ゾーンを機房やラックなどとして分類し、ゾーン内の複数のサービスを循環させます。 |
| BestAvailableRule | 回避済みのサーバを除外し、並列数が最も低いサーバを選択します。 |
| RandomRule | 使用可能なサーバをランダムに選択します。 |
| RetryRule | リトライ機構の選択ロジック |
カスタムロードバランシング戦略
IRuleを実装することでロードバランシング規則を変更できます。2つの方法:
- コード方式:order-serviceの
OrderApplicationクラスで新しいIRuleを定義します。
@Beanpublic IRule randomRule(){ return new RandomRule();}- 設定ファイル方式:order-serviceのapplication.ymlファイルに新しい設定を追加して規則を変更します:
userservice: # 負荷均衡規則を設定するマイクロサービス、この場合はuserservice ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # ロードバランス規則餓死ロード(先読みロード)
Ribbonはデフォルトでレイジーロードを採用しており、初回アクセス時にLoadBalanceClientを作成するため、リクエスト時間が長くなることがあります。
一方、先読みロードはプロジェクト起動時に作成され、初回アクセス時の待機を軽減します。以下の設定で有効化します:
ribbon: eager-load: enabled: true clients: userserviceNacos登録センター
Nacosは阿里巴巴の製品で、現在はSpringCloudの1つのコンポーネントです。国内ではEurekaより機能豊富で、人気も高いです。
公式文書Nacos 快速開始を参照して導入します。
NacosはSpringCloudAlibabaのコンポーネントであり、SpringCloudAlibabaもSpringCloudで定義されているサービス登録・サービス発見の規範に従います。したがってNacosの使用とEurekaの使用にはマイクロサービスにとって大きな違いはありません。
主な相違点は次のとおりです:
- 依存関係が異なる
- サービスアドレスが異なる
Nacosへのサービス登録
依存関係の導入
cloud-demoプロジェクトのpom.xmlの<dependencyManagement>でSpringCloudAlibabaの依存を導入します:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.6.RELEASE</version> <type>pom</type> <scope>import</scope></dependency>次にuser-serviceとorder-serviceのpomにnacos-discovery依存を導入します:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>nacosアドレスの設定
user-serviceとorder-serviceのapplication.ymlにnacosアドレスを追加します:
spring: cloud: nacos: server-addr: localhost:8848再起動
マイクロサービスを再起動すると、nacos管理画面にマイクロサービス情報が表示されます。
サービス分級ストレージモデル
1つのサービスには複数のインスタンスがあり、これらのインスタンスが全国各地の異なるデータセンターに分布している場合、Nacosは同一データセンター内のインスタンスを1つのクラスターとして区分します。
マイクロサービス同士のアクセスは、可能な限り同じクラスターのインスタンスへアクセスするべきです。なぜならローカルアクセスの方が速いためです。もし同一クラスター内で利用不能になった場合にのみ、他のクラスターへアクセスします。
- 設定
application.ymlファイルを修正し、クラスター設定を追加します:
spring: cloud: nacos: server-addr: localhost:8848 discovery: cluster-name: HZ # クラスター名Nacosには同一クラスターからインスタンスを優先的に選ぶNacosRuleの実装が用意されています。
userservice: ribbon: NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # ロードバランス規則- ウェイト設定
実際のデプロイでは、サーバ機器の性能差などがあり、性能の良い機械がより多くのユーザーリクエストを処理することを望みます。
ただしデフォルトではNacosRuleは同一クラスター内でランダムに選択され、機械の性能を考慮しません。
したがって、Nacosはアクセス頻度を制御するウェイト設定を提供します。ウェイトが大きいほどアクセス頻度が高くなります。
-
環境分離
Nacosはnamespaceを使って環境分離を実現します。
- Nacosには複数のnamespaceを持つことができます
- namespaceにはgroup、serviceなどを含むことができます
- 異なるnamespace同士は互いに見えません
-
サービスインスタンス
Nacosのサービスインスタンスは2種類のタイプに分かれます:
- 一時インスタンス:インスタンスが停止して一定時間経過するとサービスリストから除外されます(デフォルトのタイプ)。
- 永続インスタンス:インスタンスが停止してもサービスリストから除外されません(永久インスタンスとも呼ばれます)。
サービスインスタンスを永久インスタンスとして設定する:
spring: cloud: nacos: discovery: ephemeral: false # 非一時インスタンスに設定NacosとEurekaの違い
NacosとEurekaの全体的な構造は概要としては似ており、サービス登録、サービス取得、心拍待機といった点は共通です。
- NacosとEurekaの共通点
- サービス登録とサービス取得をサポート
- サービス提供者の心拍を用いた健全性検知をサポート
- NacosとEurekaの違い
- Nacosはサーバ側が提供者の状態をアクティブに検出します:一時インスタンスは心拍モード、非一時インスタンスは能動的検出モードを採用
- 一時インスタンスの心拍が異常だと除外されるが、非一時は除外されない
- Nacosはサービスリスト変更のプッシュ通知モードを提供し、サービスリストの更新がよりタイムリー
- NacosクラスターはデフォルトでAPモードを採用します。クラスター内に非一時インスタンスが存在する場合はCPモードを採用します。EurekaはAPモード
Nacos設定管理
マイクロサービスのインスタンスが増え、数十・数百となると、個別に設定を変更するのは大変です。統一的な設定管理ソリューションが必要です。集中管理されたすべてのインスタンスの設定を管理でき、設定変更時にはマイクロサービスに通知して設定をホット更新できる仕組みが求められます。
Nacosは、一方で設定を集中管理し、他方で設定変更時にマイクロサービスへ通知して設定のホット更新を実現します。
マイクロサービスから設定を取得
マイクロサービスはNacosで管理されている設定を取得し、ローカルのapplication.yml設定とマージしてプロジェクト開始を完了します。
ただし application.yml をまだ読んでいない場合、どうやってNacosアドレスを知ることができるのでしょうか?
そこでSpringは新しい設定ファイル bootstrap.yaml を導入します。これは application.yml の前に読み込まれます。
- nacos-config依存を導入
<!--nacos設定管理依存--><dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency>- bootstrap.ymlを追加
spring: application: name: userservice # サービス名 profiles: active: dev #開発環境、ここはdev cloud: nacos: server-addr: localhost:8848 # Nacosアドレス config: file-extension: yaml # ファイル拡張子ここでは spring.cloud.nacos.server-addr からNacosアドレスを取得し、${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension} をファイルIDとして設定を読み込みます。
- Nacos設定を読み取る
@Value("${pattern.dateformat}")private String dateformat;
@GetMapping("now")public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));}設定のホット更新
Nacosの設定を変更しても、マイクロサービスを再起動せずに設定を有効にできる、つまり設定のホット更新です。
-
方法1:
@RefreshScopeを追加 -
方法2
@Valueの代わりに@ConfigurationPropertiesを使います。- user-service に、
patterrn.dateformat属性を読み取るクラスを追加:
- user-service に、
package cn.itcast.user.config;
import lombok.Data;import org.springframework.boot.context.properties.ConfigurationProperties;import org.springframework.stereotype.Component;
@Component@Data@ConfigurationProperties(prefix = "pattern")public class PatternProperties { private String dateformat;}1. `UserController` でこのクラスを `@Value` の代わりに使う:@Autowiredprivate PatternProperties patternProperties;
@GetMapping("now")public String now(){ return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));}設定の共有
実際には、マイクロサービス起動時にはNacosから複数の設定ファイルを読み込みます。例えば:
[spring.application.name]-[spring.profiles.active].yaml、例:userservice-dev.yaml[spring.application.name].yaml、例:userservice.yaml
[spring.application.name].yamlは環境情報を含まないため、複数の環境間で共有できます。
設定の共有の優先順位:
Nacosとサービスローカルの両方に同じ属性がある場合、優先順位には違いがあります:

Nacosクラスタ
Nginxで複数のNacosサーバをロードバランシングする
Nacosのconfにあるcluster.confを設定し、Nacosクラスタのアドレスを追加します。
Feign遠隔呼出
RestTemplateを使った遠隔呼出のコードには次の問題があります:
- コードの可読性が低く、統一的なプログラミング体験ではない
- パラメータが多いURLの保守が難しい
Feignは宣言的なHTTPクライアントで、HTTPリクエストの送信を優雅に実現するためのものです。上記の問題を解決します。
FeignをRestTemplateの代替として
- 依存関係を導入
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId></dependency>- アノテーションを追加
起動クラスに@EnableFeignClientsを追加
- Feignクライアントを作成
サービス内にインターフェースを新規作成:
@FeignClient("userservice")public interface UserClient { @GetMapping("/user/{id}") User findById(@PathVariable("id") Long id);}このクライアントは、サービス名:userservice、リクエスト方法:GET、リクエストパス:/user/{id}、リクエストパラメータ:Long id、戻り値タイプ:User など、SpringMVCのアノテーションを用いてリモート呼出情報を宣言します。こうしてFeignは、RestTemplateを使わずにHTTPリクエストを送信するのを支援します。
- 呼出
サービスクラスからこのメソッドを呼び出します:
@Autowiredprivate UserClient userClient;
public Order queryOrderById(Long orderId) { // 1.注文を取得 Order order = orderMapper.findById(orderId); // 2. 远程查询User User user = userClient.findById(order.getUserId()); // 3. 存入order order.setUser(user); // 4.返回 return order;}カスタム設定
Feignには多くのカスタム設定があり、以下の表のとおりです:
| 種類 | 効能 | 説明 |
|---|---|---|
| feign.Logger.Level | ログレベルの変更 | NONE、BASIC、HEADERS、FULL の4段階を含む |
| feign.codec.Decoder | 応答結果のデコーダ | HTTPリモート呼出の結果を解析、例えばJSON文字列をJavaオブジェクトへ |
| feign.codec.Encoder | リクエストパラメータのエンコード | リクエストパラメータをエンコードし、HTTPリクエストで送信しやすくする |
| feign. Contract | サポートする注釈形式 | デフォルトはSpringMVCの注釈 |
| feign. Retryer | 失敗時のリトライ機構 | リクエスト失敗時のリトライ機構、デフォルトはなし、ただしRibbonのリトライを使用する場合があります |
一般的にはデフォルト値で十分なことが多いですが、カスタム時には@Beanを作成してデフォルトBeanを上書きするだけで済みます。
設定ファイルによるカスタマイズ
設定ファイルを用いてFeignのログレベルを個別のサービスに適用します:
feign: client: config: userservice: # 特定のマイクロサービスに対する設定 loggerLevel: FULL # ログレベルまたはすべてのサービスに適用するには:
feign: client: config: default: # ここに書くとグローバル設定、サービス名を指定すれば特定のマイクロサービス向け loggerLevel: FULL # ログレベルログレベルは以下の4段階です:
- NONE:ログ情報を一切記録しない。デフォルト値。
- BASIC:リクエストのメソッド、URL、レスポンスのステータスコード、実行時間のみ記録
- HEADERS:BASICに加え、リクエストとレスポンスのヘッダ情報を追加で記録
- FULL:ヘッダ情報、リクエストボディ、メタデータを含む、すべてのリクエストとレスポンスの詳細を記録。
コード方式
Javaコードでログレベルを変更するには、まずクラスを宣言し、次にLogger.Levelのオブジェクトを宣言します:
public class DefaultFeignConfiguration { @Bean public Logger.Level feignLogLevel(){ return Logger.Level.BASIC; // ログレベルはBASIC }}全体で有効にしたい場合は、起動クラスの@EnableFeignClientsにこの設定を適用します:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class)局所的に有効にしたい場合は、対応する@FeignClientアノテーションに適用します:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class)Feignの利用最適化
FeignはHTTPリクエストを発行する下位層が他のフレームワークに依存します。その下位クライアント実装には以下のものがあります:
- URLConnection:デフォルト実装、接続プールをサポートしません
- Apache HttpClient:接続プールをサポート
- OKHttp:接続プールをサポート
したがって、Feignの性能を向上させる主な手段は、デフォルトのURLConnectionの代わりに接続プールを使用することです。
ここではApacheのHttpClientを用いて説明します。
- 依存関係を導入
order-serviceのpomにApacheのHttpClient依存を導入します:
<!--httpClientの依存 --><dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId></dependency>- 接続プールを設定
order-serviceのapplication.ymlに設定を追加します:
feign: client: config: default: # defaultはグローバル設定 loggerLevel: BASIC # ログレベル、BASICは基本的なリクエストとレスポンス情報 httpclient: enabled: true # FeignによるHttpClientのサポートを有効化 max-connections: 200 # 最大コネクション数 max-connections-per-route: 50 # ルートごとの最大コネクション数要約すると、Feignの最適化は以下の点です。
- ログレベルはできるだけBASICを用いる
- HttpClientまたはOKHttpを用いてURLConnectionを置換する
- feign-httpClient依存を導入
- 設定ファイルでhttpClient機能を有効化し、コネクションプールのパラメータを設定
最適な実装
Feignのクライアントとサービス提供者のコントローラのコードは非常に似ており、このような重複したコードを簡略化する方法は以下のとおりです。
継承方式
同じコードを継承で共有できます:
- APIインターフェースを定義し、定義したメソッドをSpring MVCのアノテーションで宣言します。
- Feignクライアントとコントローラはこのインターフェースを統合します
利点:
- シンプル
- コードの共有を実現
欠点:
- サービス提供者とサービス消費者は密結合
- パラメータリストの注釈のマッピングは継承されないため、コントローラ側で再度メソッド・パラメータリスト・注釈を宣言する必要があります
抽出方式
FeignのClientを独立モジュールとして抽出し、インターフェースに関するPOJOやデフォルトのFeign設定をこのモジュールに集約して、すべての消費者に提供します。
例えば、UserClient、User、Feignのデフォルト設定を1つのfeign-apiパッケージに抽出し、すべてのマイクロサービスがこの依存パッケージを参照すれば直接使用できます。
抽出に基づくベストプラクティスの実装
-
抽出
モジュールfeign-apiを作成
OpenFeign依存を追加
サービス内のメソッドをコピー
-
order-serviceでfeign-apiを使用
依存関係を追加:
<dependency> <groupId>cn.itcast.demo</groupId> <artifactId>feign-api</artifactId> <version>1.0</version></dependency>- パッケージスキャンの問題
-
方法1:
Feignがスキャンするパッケージを指定します:
-
@EnableFeignClients(basePackages = "cn.itcast.feign.clients")-
方法2:
読み込むClientインターフェースを指定します:
@EnableFeignClients(clients = {UserClient.class})Gatewayサービスゲートウェイ
Spring Cloud GatewayはSpring Cloudの全新プロジェクトで、Spring 5.0、Spring Boot 2.0、Project Reactor などのリアクティブプログラミングとイベントストリーム技術を基盤として開発されたゲートウェイです。マイクロサービスアーキテクチャに対して、統一的で簡便なAPIルーティング管理を提供することを目的としています。
なぜゲートウェイが必要か
Gatewayは私たちのサービスの守護神で、すべてのマイクロサービスの統一エントリポイントです。
ゲートウェイのコア機能特性:
- 認可制御:ゲートウェイはマイクロサービスの入口として、リクエスト許可があるかを検証します。なければ遮断します。
- ルーティングとロードバランシング:すべてのリクエストはゲートウェイを経由しますが、ゲートウェイはビジネスを処理せず、何らかのルールに基づいてリクエストを特定のマイクロサービスへ転送します。この過程をルーティングと呼びます。ルーティング先サービスが複数ある場合は、ロードバランシングが必要です。
- レート制御:リクエストの流量が多すぎる場合、ゲートウェイは下位のマイクロサービスが処理できる速度に応じてリクエストを通すように制御します。
SpringCloudにはゲートウェイの実装として2つがあります:
- gateway
- zuul
ZuulはServletベースの実装で、ブロッキング型です。一方、SpringCloudGatewayはSpring5が提供するWebFluxをベースとしたリアクティブ実装で、より高いパフォーマンスを実現します。
入門
- SpringBootプロジェクトgatewayを作成し、ゲートウェイの依存関係を導入
<!--网关--><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--nacosサービス发现依存--><dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>- 起動クラスを作成
@SpringBootApplicationpublic class GatewayApplication {
public static void main(String[] args) { SpringApplication.run(GatewayApplication.class, args); }}- 基礎設定とルーティング規則を作成
ルーティング設定には以下が含まれます:
- ルートID:ルートの一意識別子
- ルーティング先(uri):ルーティングのターゲット先。httpは固定アドレス、lbはサービス名に基づくロードバランシング
- ルート述語(predicates):ルートの条件
- ルーティングフィルター(filters):リクエストやレスポンスを処理する
server: port: 10010 # ゲートウェイポートspring: application: name: gateway # サービス名 cloud: nacos: server-addr: localhost:8848 # nacosアドレス gateway: routes: # ゲートウェイルーティング設定 - id: user-service # ルートID、任意で唯一であればOK uri: lb://userservice # ルーティング先、lbはロードバランシング、後にサービス名を続ける predicates: # ルーティング述語、ルーティングルールの条件 - Path=/user/** # パスに従ったマッチング、/user/で始まる場合に一致- ゲートウェイサービスを起動してテスト
ゲートウェイを再起動し、http://localhost:10010/user/1 にアクセスすると、/user/**ルールに一致し、リクエストは uri: http://userservice/user/1 に転送され、結果を得られます。
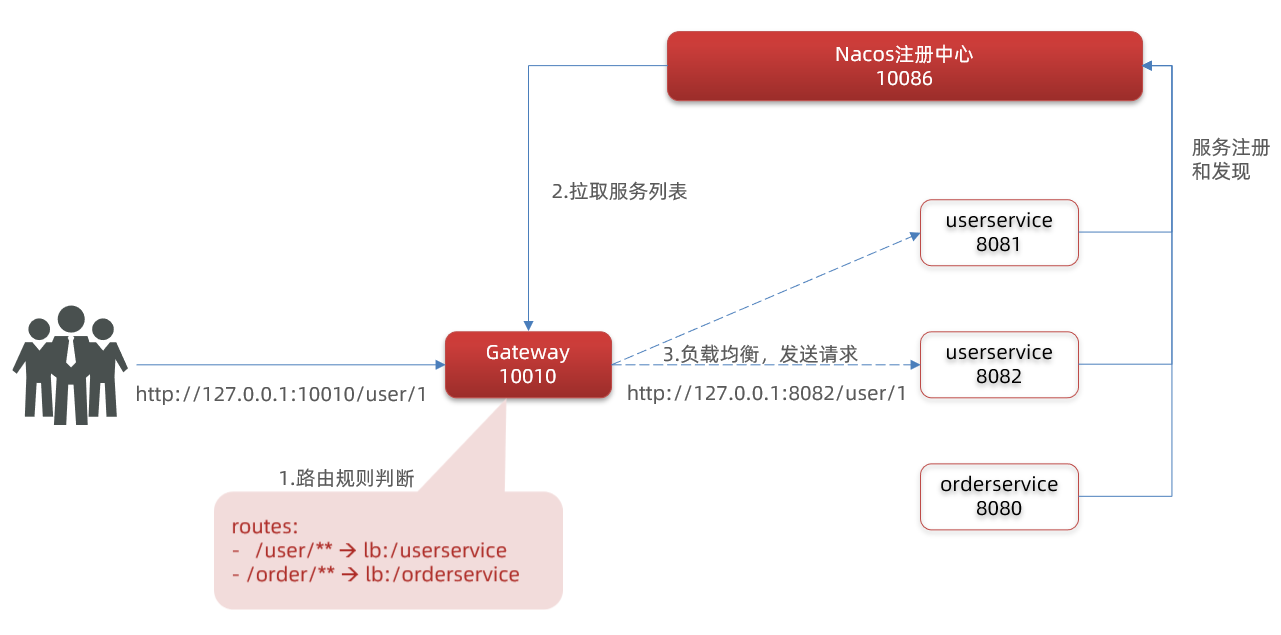
断言ファクトリ
設定ファイルに書かれた断言ルールは文字列として扱われ、Predicate Factoryによって読み取られ、ルート判断の条件に変換されます。
例:Path=/user/** はパス照合であり、このルールはorg.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactoryクラスが処理します。SpringCloudGatewayにはこのような断言ファクトリが他にも十数種類あります:
| 名称 | 説明 | 例 |
|---|---|---|
| After | 指定時間以降のリクエスト | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 指定時間以前のリクエスト | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 2つの時間点の間のリクエスト | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | リクエストには特定のcookieが含まれている必要がある | - Cookie=chocolate, ch.p |
| Header | リクエストには特定のヘッダが含まれている必要がある | - Header=X-Request-Id, \d+ |
| Host | 要求は特定のホスト(ドメイン)へアクセスする必要がある | - Host=.somehost.org,.anotherhost.org |
| Method | リクエスト方式が特定のもの | - Method=GET,POST |
| Path | リクエストパスが指定のルールに適合 | - Path=/red/{segment},/blue/** |
| Query | リクエストパラメータが特定のパラメータを含む | - Query=name, Jackまたは- Query=name |
| RemoteAddr | リクエスタのIPが指定範囲内 | - RemoteAddr=192.168.1.1/24 |
| Weight | 重み処理 |
フィルター・ファクトリ
GatewayFilterはゲートウェイに提供されるフィルターで、ゲートウェイに入るリクエストとマイクロサービスから返ってくるレスポンスを処理します
- ルートのリクエストやレスポンスを加工して、例えばリクエストヘッダを追加する
- ルート下のフィルター設定は、そのルートのリクエストにのみ有効
ルートフィルターの種類
Springは31種類のルートフィルター・ファクトリを提供します:
| 名称 | 説明 |
|---|---|
| AddRequestHeader | 現在のリクエストに1つのリクエストヘッダを追加 |
| RemoveRequestHeader | リクエストから1つのヘッダを削除 |
| AddResponseHeader | レスポンス結果に1つのレスポンスヘッダを追加 |
| RemoveResponseHeader | レスポンス結果から1つのレスポンスヘッダを削除 |
| RequestRateLimiter | リクエストの流量を制限 |
リクエストヘッダーフィルター
以下ではAddRequestHeaderを例に説明します。
要件:すべてのuserserviceへのリクエストに対して1つのリクエストヘッダを追加します:Truth=dreaife is freaking awesome!
ルーティングのgatewayサービスのapplication.ymlを修正してルートフィルターを追加します:
spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** filters: # フィルター部 - AddRequestHeader=Truth, dreaife is freaking awesome! # リクエストヘッダを追加このフィルターは現在userserviceルートに書かれているため、userserviceへアクセスするリクエストにのみ有効です。
デフォルトフィルター
すべてのルートに適用したい場合は、フィルター工場をdefaultに書くことができます。フォーマットは以下のとおりです:
spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** default-filters: # デフォルトのフィルター項目 - AddRequestHeader=Truth, dreaife is freaking awesome!グローバルフィルター
グローバルフィルターの作用
グローバルフィルターの役割も、ゲートウェイに入るすべてのリクエストとマイクロサービスのレスポンスを処理します。違いは、GatewayFilterは設定によって定義され、処理ロジックは固定ですが、GlobalFilterのロジックは自分でコードを書いて実現します。
GlobalFilterを実装するには、GlobalFilterインターフェースを実装します。
public interface GlobalFilter { /** * 現在のリクエストを処理する。必要に応じて`{@link GatewayFilterChain}` を使ってリクエストを次のフィルターへ渡します * * @param exchange リクエストのコンテキスト。Request、Responseなどの情報を取得可能 * @param chain リクエストを次のフィルターへ委譲するためのチェーン * @return {@code Mono<Void>} 現在のフィルターの処理を終了することを示す */ Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);}フィルター内でカスタムロジックを書くことで、以下の機能を実現できます:
- ログイン状態の判定
- 権限チェック
- リクエストのレート制御など
カスタムグローバルフィルター
要件:グローバルフィルターを定義し、リクエストをインターセプトして、リクエストのパラメータが以下の条件を満たすかを判断します:
- パラメータにauthorizationが含まれているか
- authorizationの値がadminか
いずれも満たせば通過、それ以外は遮断します
package cn.itcast.gateway.filters;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;import org.springframework.cloud.gateway.filter.GlobalFilter;import org.springframework.core.annotation.Order;import org.springframework.http.HttpStatus;import org.springframework.stereotype.Component;import org.springframework.web.server.ServerWebExchange;import reactor.core.publisher.Mono;
@Order(-1)@Componentpublic class AuthorizeFilter implements GlobalFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 1.リクエストパラメータ取得 MultiValueMap<String, String> params = exchange.getRequest().getQueryParams(); // 2. authorizationパラメータを取得 String auth = params.getFirst("authorization"); // 3.検証 if ("admin".equals(auth)) { // 通過 return chain.filter(exchange); } // 4.遮断 // 4.1.アクセス禁止、ステータスコードを設定 exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN); // 4.2.処理を終了 return exchange.getResponse().setComplete(); }}フィルターの実行順序
リクエストがゲートウェイに入ると、現在のルートのフィルター、DefaultFilter、GlobalFilterの3種類のフィルターに遭遇します。
リクエストがルートに従って処理されると、現在のルートフィルターとDefaultFilter、GlobalFilterを組み合わせて1つのフィルター連鎖(コレクション)を作成し、順番に実行します。
順序付けのルールは次のとおりです:
- 各フィルターはint型のorder値を指定する必要があります。order値が小さいほど優先度が高く、実行順が前になります。
- GlobalFilterはOrderedインターフェースを実装するか、
@Orderアノテーションを付与してorder値を指定します。 - ルートフィルターとdefaultFilterのorderはSpringによって指定され、デフォルトは宣言順に1ずつ増加します。
- フィルターのorder値が同じ場合は、defaultFilter > ルートフィルター > GlobalFilter の順に実行されます。
クロスオリジン問題
クロスオリジン:ドメイン名が異なる場合を指します。主に以下を含みます:
- 異なるドメイン名: www.taobao.com、www.taobao.org、www.jd.com、miaosha.jd.com
- 同一ドメイン、ポートが異なる場合:localhost<8080> と localhost<8081>
クロスオリジン問題は、ブラウザがサービスへ送るクロスドメインのAjaxリクエストを禁止することで、リクエストがブラウザでブロックされる問題です。
解決策:CORS
gatewayサービスのapplication.ymlに以下の設定を追加します:
spring: cloud: gateway: globalcors: # グローバルのクロスオリジン処理 add-to-simple-url-handler-mapping: true # optionsリクエストのブロックを回避 corsConfigurations: '[/**]': allowedOrigins: # 許可するクロスオリジンリクエスト先サイト - "<http://localhost:8090>" allowedMethods: # 許可するクロスオリジンのAjaxリクエスト方式 - "GET" - "POST" - "DELETE" - "PUT" - "OPTIONS" allowedHeaders: "*" # リクエストで許可されるヘッダ情報 allowCredentials: true # クッキーの送受を許可するか maxAge: 360000 # このクロスオリジン検出の有効期限この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります