


















Javaの並行プログラミング
スレッドとプロセスとは何か?
プロセスとは何か?
プロセスはプログラムの1回の実行過程であり、システムがプログラムを実行する基本単位なので、プロセスは動的です。システムが1つのプログラムを実行することは、そのプログラムの作成から実行、消滅までの過程となります。
Javaでは、main 関数を起動すると実際には JVM のプロセスを起動しており、main 関数があるスレッドはこのプロセス内の1つのスレッド、いわゆるメインスレッドです。
スレッドとは何か?
スレッドはプロセスと似ていますが、スレッドはプロセスよりも小さな実行単位です。あるプロセスは実行中に複数のスレッドを生成できます。クラスが同じでも複数のスレッドは、プロセスのヒープとメソッド領域のリソースを共有しますが、各スレッドは独自のプログラムカウンター、JVMスタック、ネイティブメソッドスタックを持っています。したがって、OS がスレッドを生成したり、各スレッド間で切替えを行う際の負担は、プロセスに比べて非常に小さくなり、これが理由でスレッドは「軽量なプロセス」とも呼ばれます。
Java のプログラムは生まれつきマルチスレッドです。JMX を使って通常の Java プログラムにはどのようなスレッドがあるかを確認するコードは以下のとおりです。
public class MultiThread { public static void main(String[] args) { // 获取 Java 线程管理 MXBean ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean(); // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息 ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false); // 遍历线程信息,仅打印线程 ID 和线程名称信息 for (ThreadInfo threadInfo : threadInfos) { System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName()); } }}上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
[5] Attach Listene r //添加事件[4] Signal Dispatcher // 分发处理给 JVM 信号的线程[3] Finalizer //调用对象 finalize 方法的线程[2] Reference Handler //清除 reference 线程[1] main //main 线程,程序入口このように、上の出力から見てわかるのは:Java プログラムの実行は main スレッドと他の複数のスレッドが同時に動作しているということです。
Java のスレッドとOS のスレッドの違いは何か?
JDK 1.2 以前は、Java のスレッドはグリーン・スレッド(Green Threads)と呼ばれるユーザー空間のスレッドで実装されており、JVM 自身がマルチスレッドの実行を模倣して OS には依存していませんでした。グリーン・スレッドは、OS が提供する機能を直接利用できなかったり、1つのカーネル・スレッド上でのみ動作してしまい、マルチコアを活用できないといった制限がありました。そのため、JDK 1.2 以降は Java のスレッドは原生スレッド(Native Threads)に基づく実装へと変更され、JVM は OS の原生カーネル・スレッドを直接使用して Java スレッドを実現し、OS のカーネルがスレッドのスケジューリングと管理を行います。
前述のように、ユーザースレッドとカーネルスレッドの違いは以下のとおりです:
- ユーザースレッド:ユーザー空間のプログラムが管理・スケジュールするスレッド。アプリケーション用に専用の領域で動作します。
- カーネルスレッド:OS のカーネルが管理・スケジュールするスレッド。カーネル空間で動作します(カーネルのみがアクセス可能)。
簡単にまとめると、現在の Java のスレッドは本質的には OS のスレッドそのものなのです。
スレッドモデルには、ユーザースレッドとカーネルスレッドの関連付け方があり、代表的なモデルは次の三つです:
- 1対1(一つのユーザースレッドが一つのカーネルスレッドに対応)
- 多対一(複数のユーザースレッドが一つのカーネルスレッドに対応)
- 多対多(複数のユーザースレッドが複数のカーネルスレッドに対応)
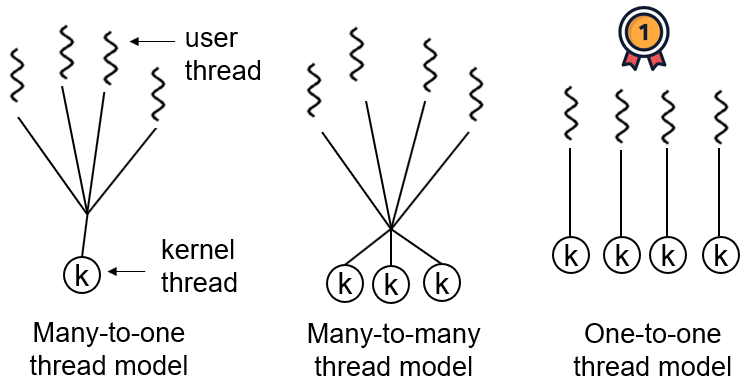
Windows や Linux などの主要なOS では、Java のスレッドは基本的に1対1のモデルを採用しています。Solaris は例外的なケースで、Solaris 自体が多対多のモデルをサポートしており、HotSpot VM は Solaris で多対多と1対1の両方をサポートします。
スレッドとプロセスの関係、違い、長所と短所を簡潔に説明してください?
JVM の観点から、プロセスとスレッドの関係を図解します。
下図は Java のメモリ領域です。以下の図を通じて JVM の視点からスレッドとプロセスの関係を説明します。
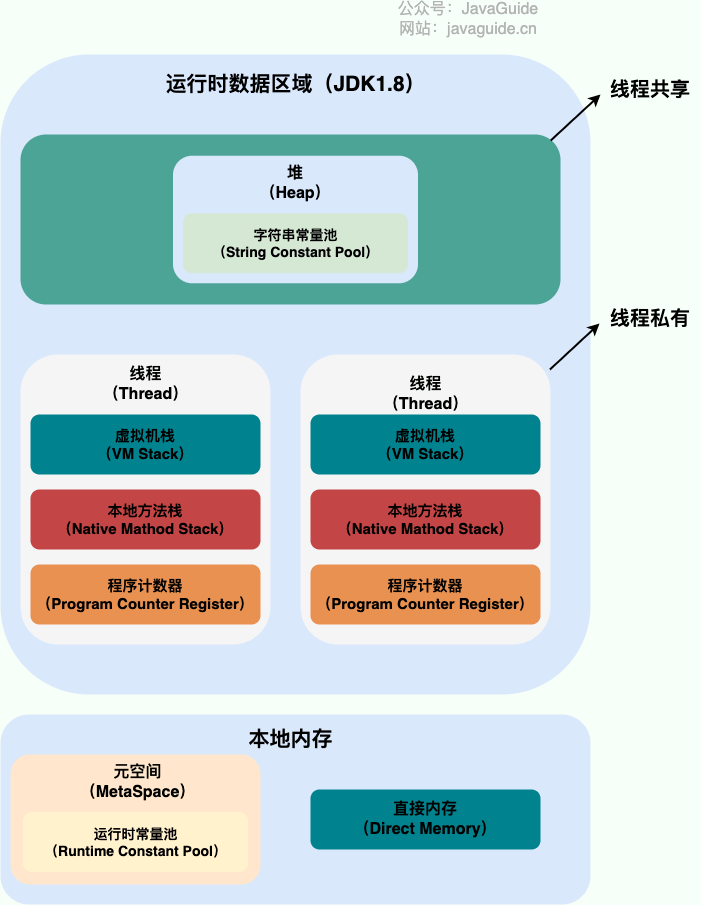
上図からわかるように、1つのプロセスには複数のスレッドを持つことができます。複数のスレッドはプロセスの堆と方法区(JDK1.8 以降のメタ空間)を共有しますが、各スレッドは自分のプログラムカウンター、仮想マシン・スタック、ネイティブメソッド・スタックを持っています。
要約:スレッドはプロセスを分割したより小さな実行単位です。スレッドとプロセスの最大の違いは、基本的には各プロセスは独立していますが、同じプロセス内のスレッド同士は互いに影響を及ぼす可能性がある点です。スレッドの実行オーバーヘッドは小さいですが、資源の管理と保護には不利です。対して、プロセスはその逆です。
以下はこの知識点の拡張内容です!
次の問題を考えます:なぜプログラムカウンター、仮想マシン・スタック、およびネイティブメソッド・スタックはスレッドごとに私有なのですか?なぜヒープとメソッド領域はスレッド間で共有されるのですか?
プログラムカウンターはなぜ私有なのか?
プログラムカウンターには以下の2つの主要な役割があります:
- バイトコード・インタプリタが命令を順次読み取るためにプログラムカウンターを変更して、コードのフロー制御を実現します(例:順次実行、分岐、ループ、例外処理)。
- マルチスレッド時には、現在のスレッドがどこを実行しているかを記録するため、スレッドが再度実行を再開したときに前回の実行位置を復元できます。
注意すべき点として、ネイティブメソッドを実行している場合、プログラムカウンターは undefined アドレスを記録します。Java コードを実行している場合のみ、プログラムカウンターには次の命令のアドレスが記録されます。
したがって、プログラムカウンターを私有化する主な理由は、スレッド切替後に正しい実行位置へ復元するためです。
仮想マシン栈とネイティブメソッド栈はなぜ私有なのか?
- 仮想マシン栈(JVMスタック):各 Java メソッドが実行される前に、局所変数表、オペランド・スタック、定数プール参照などの情報を格納するスタック・フレームを作成します。メソッド呼び出しから実行完了までの過程は、Java 仮想マシン栈の中でスタック・フレームが入出される過程に対応します。
- ネイティブメソッド栈:JVMスタックと役割は非常に似ています。違いは、仮想マシン栈はJava メソッド(すなわちバイトコード)の実行を支援するためのもので、ネイティブメソッド栈はJVM が使用するネイティブ・メソッドを支援するものです。HotSpot では JVM スタックとネイティブメソッド栈は統合されています。
したがって、スレッド内の局所変数が他のスレッドに見られないようにするために、JVMスタックとネイティブメソッド栈はスレッドごとに私有です。
一言で理解する堆とメソッド領域
ヒープとメソッド領域は全スレッドが共有する資源です。そのうち、ヒープはプロセス内で最大のメモリ領域であり、主に新しく作成されたオブジェクトを格納します(ほとんどすべてのオブジェクトはここに割り当てられます)。メソッド領域はロードされたクラス情報、定数、静的変数、JIT コンパイル後のコードなどのデータを格納します。
並行と並列の違い
- 並行(Concurrency):2つ以上の作業が同じ時間の区間内で実行される。
- 並列(Parallelism):2つ以上の作業が同じ時点で同時に実行される。
最も重要な点は、同時に実行されるかどうかです。
同期と非同期の違い
- 同期:呼び出しを発行した後、結果を得る前にその呼び出しは戻らず、待機します。
- 非同期:呼び出しを発行した後、結果を待たずにその呼び出しはすぐ返ります。
なぜマルチスレッドを使うのか?
まず全体的に:
- コンピュータの低位層から見ると:スレッドは軽量プロセスのようなもので、プログラム実行の最小単位です。スレッド間の切替・スケジューリングのコストはプロセスよりもはるかに低く、また多核 CPU の時代は複数のスレッドを同時に実行できるため、スレッドのコンテキスト切替のオーバーヘッドが減少します。
- 現代のインターネットの発展動向から:今のシステムはしばしば百万級、さらには千万級の並行性を要求します。マルチスレッドの並行プログラミングは高い並行性を持つシステムを開発する基礎であり、多数のスレッド機構を活用することでシステム全体の並列性と性能を大幅に向上させることができます。
さらに、計算機の下位層を掘り下げて検討すると:
- 単一コア時代:複数スレッドは、CPU と IO のリソースを効率良く活用するために役立ちます。IO を要求した際、1つのスレッドしか動作していない場合、そのスレッドが IO でブロックされると、プロセス全体がブロックされてしまいます。CPU と IO デバイスが1つしか動作していない場合、全体の効率はおよそ50%程度になります。複数スレッドを使えば、IO によってブロックされている間も他のスレッドが CPU を利用でき、資源利用の効率が向上します。
- 多核時代:多核時代の主眼は、プロセスが複数の CPU コアを活用する能力を高めることです。複雑なタスクを計算する場合、1つのスレッドだけだと CPU コアの数だけしか活用できません。複数のスレッドを作成して下位の複数の CPU に割り当てて実行すれば、リソース競合がない場合にはタスクの実行効率は顕著に向上します。理論的には(単核時の実行時間)/(CPU コア数)程度の改善です。
多 threading を使うと何が問題になるか?
並行プログラミングの目的は、プログラムの実行効率を高め、実行速度を向上させることですが、必ずしも速度を向上させるとは限りません。メモリリーク、デッドロック、スレッドの安全性の問題など、さまざまな問題に直面する可能性があります。
スレッドセーフとセーフでないのをどう理解するか?
並列環境で同じデータに対するアクセスが正確性と一貫性を保てるかを説明します。
- スレッドセーフとは、複数のスレッドが同時に同一データにアクセスしても、そのデータの正確性と一貫性を保証できる状態です。
- スレッドセーフでないとは、同時アクセス時にデータが混乱したり、誤りが生じたり、欠落が起き得る状態を意味します。
単一コア CPU で複数のスレッドを走らせると、必ず効率が上がるのか?
単一コア CPU で複数スレッドを同時実行するかどうかは、スレッドのタイプとタスクの性質に依存します。CPU 集約型と IO 集約型の2種類があります。
- CPU 集約型は大量の CPU リソースを占有します。複数スレッドが同時に動作すると、頻繁なスレッド切替が発生し、オーバーヘッドが増え、効率が低下します。
- IO 集約型は IO 操作を待つ時間が多く、CPU を占有しません。複数スレッドを使うと、IO 待ちの間の CPU の空き時間を活用でき、効率が向上します。
したがって、CPU コアが1つの場合、タスクが CPU 集約型なら多くのスレッドを使うと効率が落ち、IO 集約型なら多くのスレッドを使うと効率が上がる傾向があります。ただし、上限はシステムの容量に依存します。
スレッドのライフサイクルと状態を説明してください
Java のスレッドは実行中のライフサイクルの中で、特定の時点で以下の6つの異なる状態のいずれかにあります。
- NEW: 初期状態、スレッドが生成されたが
start()は呼ばれていない。 - RUNNABLE: 実行可能状態、
start()が呼ばれて実行待ちの状態。 - BLOCKED: ロック解放を待機しているブロック状態。
- WAITING: 他のスレッドが通知するなどして再開を待つ待機状態。
- TIMED_WAITING: 指定時間だけ待機する待機状態。時間が来れば自動的に RUNNABLE 状態に戻る。
- TERMINATED: 終了状態、スレッドが実行を終えた。
ライフサイクルの各状態は一定の順序で固定されているわけではなく、コードの実行に応じて状態間を切り替えます。
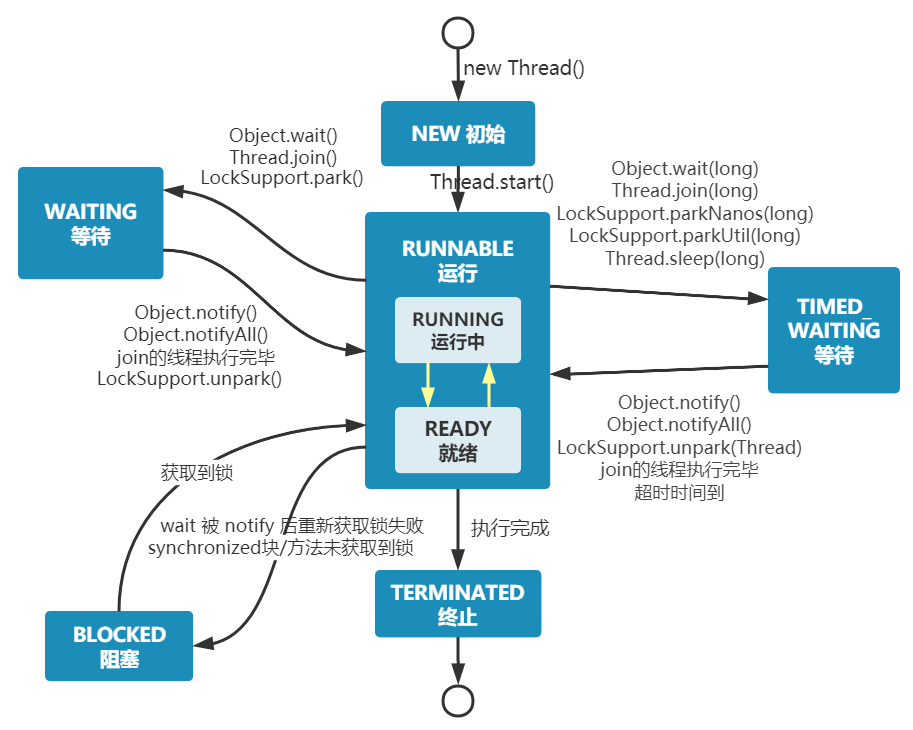
上の図から、スレッドは作成後にNEW(新規作成)、start()を呼ぶと実行を開始してREADY(実行可能)、CPU のタイムスライスを得ると**RUNNING(実行中)**となります。
- スレッドが
wait()を実行すると、スレッドは**WAITING(待機)**状態に入り、他のスレッドの通知を待って実行状態へ戻ります。 - **TIMED_WAITING(タイムアウト待機)**は待機状態にタイムアウトを追加した状態で、
sleep(long)やwait(long)で入ることができます。タイムアウトが終了すると RUNNABLE に戻ります。 synchronizedメソッド/ブロック内に入り、他のスレッドが同じロックを保持している場合、**BLOCKED(ブロック)**状態になります。run()を実行し終えると、スレッドは TERMINATED(終了) 状態になります。
スレッド・コンテキスト・スイッチングとは?
スレッドは実行中に自分固有の実行条件と状態(コンテキスト)を持ちます。次のような場合に、現在の CPU を占有しているスレッドから抜けて切替ります。
- 自発的に CPU を譲る(
sleep()、wait()などを呼ぶ) - タイムスライスの消費
- ブロック状態になる(IO 要求など)
- 終了・終了処理
このようなケースの多くでスレッドは切替り、現在のスレッドのコンテキストを保存して次のスレッドのコンテキストを復元します。これが所谓のコンテキスト切替です。
コンテキスト切替は、現代の OS の基本機能です。情報を保存して復元するたびに CPU、メモリなどの資源を消費するため、効率には影響します。頻繁な切替は全体の効率を低下させます。
スレッドデッドロックとは?デッドロックを回避するには?
デッドロックを理解する
デッドロックとは、複数のスレッドが同時にブロックされ、いずれかまたは全てのスレッドが資源の解放を待っている状態です。スレッドが無限にブロックされるため、プログラムは正常に終了できません。
例として、スレッド A が資源 2 を保持し、スレッド B が資源 1 を保持しているとします。彼らは互いに相手の資源を要求しており、相互に待機してデッドロックに陥ります。
デッドロックの4つの必要条件:
- 互斥条件:資源は同時に1つのスレッドのみが占有します。
- 要求と保持条件:スレッドが資源を要求してブロックされると、既に取得している資源を放さず保持します。
- 不剥奪条件:スレッドが取得した資源は、使用が完了するまで他のスレッドに奪われません。
- 循環待機条件:複数スレッドが資源を待つ循環的な関係を形成します。
デッドロックを予防・回避するには?
-
デッドロックを予防するには、デッドロックが生じるための条件を破壊します。
- 要求と保持条件を破壊する:資源を一括で申請します。
- 不剥奪条件を破壊する:部分資源を保持しているスレッドが他の資源を申請できない場合、保持している資源を解放します。
- 循環待機条件を破壊する:資源を一定の順番で申請するなどして循環待機を防ぐ。資源をある順序で申請し、解放は逆順で行います。循環待機条件を破壊します。
-
デッドロックを回避するには、資源割り当て時にアルゴリズム(例えば銀行家アルゴリズム)を用いて資源割り当てを評価し、安全状態へ導きます。
安全状態とは、システムがある特定のスレッド推進順序(P1、P2、P3……Pn)で各スレッドに必要資源を割り当て、各スレッドが最大資源要件を満たして完了できる状態を指します。<P1、P2、P3…Pn> の列を安全列と呼びます。
以下のコードはスレッド 2 の例です。デッドロックは生じません。
new Thread(() -> { synchronized (resource1) { System.out.println(Thread.currentThread() + "get resource1"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resource2"); synchronized (resource2) { System.out.println(Thread.currentThread() + "get resource2"); } } }, "线程 1").start();
new Thread(() -> { synchronized (resource1) { System.out.println(Thread.currentThread() + "get resource1"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resource2"); synchronized (resource2) { System.out.println(Thread.currentThread() + "get resource2"); } } }, "线程 2").start();上のコードがデッドロックを回避する理由を分析します。
スレッド 1 はまず resource1 のモニター・ロックを取得します。この時点でスレッド 2 は取得できません。次にスレッド 1 は resource2 のモニター・ロックを取得できます。スレッド 1 が resource1 と resource2 のモニター・ロックを解放すると、スレッド 2 が取得でき、実行を再開できます。これにより、循環待機条件が破壊され、デッドロックを回避します。
sleep() と wait() の比較
共通点
両者ともスレッドの実行を一時停止させます。
違い
sleep()はロックを解放しません。一方、wait()はロックを解放します。wait()は通常、スレッド間の通信・協調に用いられ、sleep()は実行の一時停止に使われます。wait()を呼ぶと、別のスレッドが同じオブジェクトのnotify()またはnotifyAll()を呼ぶまで自動的には目覚めません。sleep()は終了後に自動的に目覚めるか、wait(long timeout)を使えばタイムアウトで目覚めます。sleep()はThreadクラスの静的ネイティブ・メソッドですが、wait()はObjectクラスのネイティブ・メソッドです。
なぜ wait() は Thread に定義されていないのか?
wait() は、オブジェクトのロックを取得しているスレッドに待機を実装させ、現在のスレッドが所有しているオブジェクト・ロックを自動で解放します。各オブジェクト(Object)にはロックが存在し、現在のスレッドを解放して WAITING 状態へ入らせるには、該当するオブジェクトを操作する必要があり、現在のスレッド(Thread)を操作するわけではありません。
同様の問い:「なぜ sleep() は Thread に定義されているのか?」
sleep() は現在のスレッドを一時停止させるだけで、オブジェクト・クラスには関与せず、オブジェクト・ロックを得る必要がないからです。
Thread クラスの run メソッドを直接呼び出してよいか?
新しい Thread を作成するとスレッドは新規作成状態になります。start() を呼ぶとスレッドを起動し、実行可能状態になります。タイムスライスが割り当てられると実行を開始します。start() はスレッドの準備を行い、run() の内容を自動的に実行します。これが実際のマルチスレッド作業です。しかし、run() を直接実行すると、run() をマイ Java の通常のメソッドとして実行することになり、特定のスレッドで実行されることはないため、これはマルチスレッド作業とはなりません。
要約:start() を呼び出してスレッドを起動し、実行可能状態にします。run() を直接実行すると、マルチスレッドとして実行されません。
volatile キーワード
変数の可視性をどう保証するか?
Java では、volatile キーワードは変数の可視性を保証します。volatile を宣言した変数は共有かつ不安定で、毎回主記憶から読み取られます。
JMM(Java メモリ・モデル)
volatile キーワードは Java 言語特有のものではなく、C 言語にも存在します。その最も原始的な意味は CPU キャッシュを無効化することです。変数を volatile で修飾すると、コンパイラはこの変数の使用時に主記憶から読み取るべきだと示します。
volatile キーワードはデータの可視性を保証しますが、データの原子性を保証するものではありません。synchronized キーワードは可視性と原子性の両方を保証します。
命令再排序を禁止するには?
Java では、volatile キーワードは変数の可視性を保証するほか、JVM の命令再排序を防ぐ重要な役割も果たします。もし変数を volatile として宣言した場合、その変数の読み書き操作は、特定のメモリ・バリアを挿入することによって命令再排序を禁止します。
Java には Unsafe クラスがあり、以下の3つの差分を隠蔽するメモリ・バリアの関連メソッドが公開されています。
public native void loadFence();public native void storeFence();public native void fullFence();理論的には、これらの3つのメソッドを使って volatile の再排序禁止と同様の効果を得ることができますが、やや煩雑です。
ここで、面接でよく出る題材を例に、volatile キーワードが命令再排序を禁止する効果を説明します。
「シングルトン・パターンを知っていますか?手書きで作ってください。デュアルチェック・ロックによるシングルトンの原理を説明してください!」
- デュアルチェック・ロックでオブジェクトのシングルトンを実装(スレッドセーフ):
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() { }
public static Singleton getUniqueInstance() { // 先にオブジェクトが生成されているかどうかをチェック if (uniqueInstance == null) { // クラスオブジェクトをロック synchronized (Singleton.class) { if (uniqueInstance == null) { uniqueInstance = new Singleton(); } } } return uniqueInstance; }}uniqueInstance を volatile で修飾することはとても重要です。uniqueInstance = new Singleton(); は実際には3段階に分かれて実行されます:
uniqueInstanceにメモリ空間を割り当てるuniqueInstanceを初期化するuniqueInstanceが割り当てたメモリ・アドレスを指すようにする
しかし、JVM には命令再排序の特性があるため、実行順序が 1→3→2 になることがあります。単一スレッドの環境では問題になりませんが、マルチスレッド環境では、初期化されていないインスタンスをあるスレッドが取得してしまう可能性があります。例えば、T1 が 1 と 3 を実行した場合、T2 が getUniqueInstance() を呼ぶと uniqueInstance が非 null に見えるため返しますが、この時点で uniqueInstance はまだ初期化されていません。
volatile は原子性を保証するか?
volatile キーワードは変数の可視性を保証しますが、変数の操作自体の原子性を保証するものではありません。
以下のコードで示します。
public class VolatoleAtomicityDemo { public volatile static int inc = 0;
public void increase() { inc++; }
public static void main(String[] args) throws InterruptedException { ExecutorService threadPool = Executors.newFixedThreadPool(5); VolatoleAtomicityDemo volatoleAtomicityDemo = new VolatoleAtomicityDemo(); for (int i = 0; i < 5; i++) { threadPool.execute(() -> { for (int j = 0; j < 500; j++) { volatoleAtomicityDemo.increase(); } }); } // 上の処理の完了を待つ Thread.sleep(1500); System.out.println(inc); threadPool.shutdown(); }}通常、このコードは理論上は 2500 を出力するはずですが、実際には毎回 2500 より小さい値になります。
なぜかというと、volatile は可視性を保証しますが、inc++ は3つの操作からなる複合操作であり、原子性を保証しません:
incの値を読み取るincに 1 を加える- その新しい値をメモリに書き戻す
volatile ではこの3つの操作を一括して原子にすることはできません。これを防ぐには synchronized、Lock、あるいは AtomicInteger を使います。
synchronizedで改良:
public synchronized void increase() { inc++;}AtomicIntegerで改良:
public AtomicInteger inc = new AtomicInteger();
public void increase() { inc.getAndIncrement();}ReentrantLockで改良:
Lock lock = new ReentrantLock();public void increase() { lock.lock(); try { inc++; } finally { lock.unlock(); }}楽観锁と悲観锁
悲観锁とは?
悲観锁は最悪の事態を想定し、共有資源が毎回問題を起こすと考え、資源を取得する際には毎回ロックをかけます。他のスレッドが資源を取得したい場合は待機します。つまり、共有資源は毎回1つのスレッドのみが使用し、他のスレッドは待機して、使用後に他のスレッドへ資源を譲ります。
Java の synchronized や ReentrantLock などの排他ロックは、悲観锁の思想の実装です。
public void performSynchronisedTask() { synchronized (this) { // 同期が必要な操作 }}
private Lock lock = new ReentrantLock();lock.lock();try { // 同期が必要な操作} finally { lock.unlock();}高い同時実行の場面では、激しいロック競合がスレッドのブロックを引き起こし、大量のブロックされたスレッドがシステムのコンテキスト・スイッチを増やし、性能オーバーヘッドを増大させます。さらに、悲観锁はデッドロックの問題を引き起こす可能性があるため、コードの通常の実行に影響します。
楽観锁とは?
楽観锁は最良のケースを想定し、共有資源へアクセスするたびに問題が発生しないと仮定します。スレッドはロックを取らず、変更のコミット時に対象の資源(データ)が他のスレッドによって変更されていないかを検証します(バージョン番号機構や CAS アルゴリズムを利用します)。
Java の java.util.concurrent.atomic パッケージの原子変数クラス(例:AtomicInteger、LongAdder)は CAS(Compare And Swap)を用いた楽観锁の実装の一つです。
// LongAdder は高い同時実行時に AtomicInteger よりも性能が良くなることがある// コストはメモリ空間を多く消費する代わりに時間を節約できるLongAdder sum = new LongAdder();sum.increment();高い同時実行の場面では、楽観锁は競合が少ない読み取りが多い場面では有利ですが、衝突が頻繁に発生すると(書き込みが多い場合)失敗と再試行が頻繁に起き、CPU が過負荷になることがあります。また、再試行の失敗が多くなる問題を解決するために LongAdder などが用いられます。
- 悲観锁は書き込みが多い場合に適しており、失敗と再試行の回数を抑え、性能の安定性を上げやすい。一方で楽観锁は読み取りが多く競合が少ない場合に適しています。
楽観锁を実現するには?
楽観锁は通常、バージョン番号機構または CAS を用いて実現します。以下は一般的な概念です。
バージョン番号機構
データベースのテーブルに version フィールドを追加して、データが変更されるたびに version が増えます。スレッド A がデータを更新する際、読み取り時に version を読み取り、更新の際に読み取った version が現在のデータの version と等しければ更新します。そうでなければ再試行します。
簡単な例:口座情報テーブルに version、現在の残高が $100 の場合
- オペレーター A が読み取り、
version=1、口座残高から 100-$50)。 - オペレーター B も読み取り、
version=1、口座残高から 100-$20)。 - A が更新を提出し、
version=1 のままで更新が成功、versionが 2 に更新。 - B が更新を提出するも、データベースの現在の
versionは 2 に対し B の提出は 1 のため拒否。
このようにして、古いデータでの更新が新しい結果を覆い取ることを防ぎます。
CAS(Compare And Swap)アルゴリズム
CAS は「現在の値が期待値と一致する場合のみ、新しい値で更新する」原子的な操作です。3つのオペランドが関与します:
- V:更新対象となる変数
- E:期待される値(Expected)
- N:新しい値(New)
V が E と等しい場合のみ、原子的に V を N に更新します。等しくなければ更新は失敗します。
CAS は原子操作で、CPU の原子命令に依存します。Java には直接の CAS 実装はなく、C++ のインライン・アセンブリ(JNI)経由で実装されます。sun.misc.Unsafe クラスには compareAndSwapObject、compareAndSwapInt、compareAndSwapLong などの CAS 操作が提供されます。
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);楽観锁における問題
ABA 問題は楽観锁で最も一般的な問題です。
もし変数 V を最初に A で読み取り、更新前にも A のままであることを確認したとしても、それが他のスレッドによって A から別の値に変更され、再度 A に戻っている可能性があります。これが ABA 問題です。ABA 問題の解決は、変数の前にバージョン番号やタイムスタンプを追加することです。
後述の AtomicStampedReference は ABA 問題を解決するためのクラスです。compareAndSet() は、現在の参照が予期された参照と等しく、かつ現在のスタンプが予期されたスタンプと等しい場合に限り、参照とスタンプの値を更新します。
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp) { Pair<V> current = pair; return expectedReference == current.reference && expectedStamp == current.stamp && ((newReference == current.reference && newStamp == current.stamp) || casPair(current, Pair.of(newReference, newStamp)));}循環時間が長いとオーバーヘッドが大きい
CAS はしばしばスピン操作を用いて再試行を行います。長時間うまくいかない場合、CPU に大きなオーバーヘッドをもたらします。
JVM がハードウェアの pause 命令をサポートすれば、効率が向上します。pause には次の2つの役割があります。
- パイプラインの実行を遅延させ、CPU が過剰な実行リソースを消費しないようにします。遅延時間は実装に依存します。
- 循環を抜ける際のメモリ順序の乱れによって CPU パイプラインがクリアされるのを防ぎ、実行効率を向上させます。
1つの共有変数の原子操作のみ保証
CAS は単一の共有変数に対して有効です。複数の共有変数に跨る操作は CAS だけでは成り立ちません。しかし、JDK 1.5 以降、AtomicReference を用いて複数の変数を1つの共有変数にまとめて CAS 操作を行うことができます。
- locks を用いるか、
AtomicReferenceを用いて複数の共有変数を1つの共有変数にまとめて扱うことができます。
synchronized キーワード
synchronized とは? 何の役に立つのか?
synchronized は Java のキーワードで、日本語では「同期」と訳され、複数スレッド間のリソースアクセスの同期性を解決するためのものです。修飾されたメソッドやコードブロックは、いかなる時点でも1つのスレッドだけが実行できます。
初期の Java では、synchronized は「ヘビー・ロック」で、効率が低く、モニター・ロックは OS の Mutex Lock に依存しています。スレッドを待機・再開するには OS の協力が必要で、ユーザモードからカーネルモードへの切替えには時間がかかります。
しかし、Java 6 以降、synchronized には自スパイン・ロック、適応スパイン・ロック、ロック除去、ロック粗化、偏向ロック、軽量ロックなどの最適化が導入され、ロック操作のオーバーヘッドを大幅に削減しました。したがって、synchronized は実プロジェクトでも十分に使用可能で、JDK のソースコードや多数のオープンソース・フレームワークでも広く使用されています。
なお、偏向ロックについては JVM の複雑さを増す要因となるため、すべてのアプリに対して効果が出るわけではありません。JDK15 では偏向ロックはデフォルトでオフ、-XX:+UseBiasedLocking で有効化することはできます。JDK18 では偏向ロックは完全に廃止されています(コマンドラインから有効化できません)。
synchronized の使い方
synchronized の使い方は、大きく以下の3つです。
-
インスタンスメソッドを修飾する
synchronized void method() {// 业务代码} -
静的メソッドを修飾する
synchronized static void method() {// 业务代码}静的メンバーはいかなるインスタンスにも属さず、クラス全体で共有されます。
-
コードブロックを修飾する
synchronized(this) {// 业务代码}synchronized(object)は同期コード・ブロックへ入る前に指定されたオブジェクトのロックを取得します。synchronized(クラス.class)は、同期コードに入る前に指定されたクラスのロックを取得します。
要約:
static静的メソッドとsynchronized(class)コードブロックにはクラスロックがかかります。- インスタンスメソッドにはオブジェクトインスタンスのロックがかかります。
synchronized(String a)の使用は避けるべきです。文字列リテラル・プールにはキャッシュ機能があるためです。
コンストラクタは synchronized で修飾できるか?
結論:コンストラクタは synchronized で修飾できません。
コンストラクタ自体はスレッドセーフであり、同期されたコンストラクタという概念は存在しません。
synchronized の下層の原理は?
synchronized の下層の原理は JVM レベルの話です。
- 同期ブロックの場合
public class SynchronizedDemo { public void method() { synchronized (this) { System.out.println("synchronized 代码块"); } }}このクラスのバイトコードを javap で確認すると、monitorenter と monitorexit の命令が含まれています。monitorenter は同期コードの開始位置を指し、monitorexit は同期コードの終了位置を指します。
このバイトコードには monitorenter が1つ、monitorexit が2つ含まれます。これは、ロックが通常の実行時および例外が発生した場合の両方で正しく解放されるようにするためです。
monitorenter を実行すると、スレッドはオブジェクトのロックを取得します。ロックのカウンターが 0 の場合、ロックを取得可能となり、カウンターを 1 にします。
オブジェクト・ロックの所有者スレッドだけが monitorexit を実行してロックを解放できます。monitorexit を実行した後、ロック・カウンターを 0 に設定してロックを解放します。
synchronized修飾のメソッドの場合
public class SynchronizedDemo2 { public synchronized void method() { System.out.println("synchronized 方法"); }}この場合、monitorenter/monitorexit は存在せず、代わりに ACC_SYNCHRONIZED フラグが付与されます。JVM はこのフラグを使って同期メソッドかどうかを判断し、適切な同期呼び出しを行います。
インスタンス・メソッドの場合はインスタンスのロック、静的メソッドの場合はクラスのロックを取得します。
要約
synchronized の同期ブロックは monitorenter / monitorexit を使用して実現します。同期メソッドは ACC_SYNCHRONIZED フラグを使います。いずれもオブジェクトのモニター(monitor)を取得する点が本質です。
JDK1.6 以降の synchronized の最適化とロックのアップグレード原理は?
Java 6 以降、synchronized には多くの最適化が導入され、自スパイン・ロック、適応スパイン・ロック、ロック消去、ロック粗化、偏向ロック、軽量ロックなどの技術によって、ロック操作のオーバーヘッドを減らしました。これにより、synchronized のロックの効率は大幅に向上しました(ただし、JDK18 では偏向ロックは完全に廃止されています)。
ロックは無ロック状態、偏向ロック、軽量ロック、重量鎖の4つの状態を持ち、競合の度合いによって段階的にアップグレードします。降格は基本的に行われず、アップグレードのみが許される方針です。
synchronized と volatile の違いは?
volatileはスレッド同期の軽量化を実現し、一般的にsynchronizedよりも高いパフォーマンスを提供します。ただし、volatileは変数にのみ適用され、メソッドやコードブロックには適用できません。volatileはデータの可視性を保証しますが、原子性を保証しません。synchronizedは可視性と原子性の両方を保証します。volatileは主に変数の可視性を解決します。一方、synchronizedは複数スレッド間のリソースアクセスの同期性を解決します。
ReentrantLock
ReentrantLock とは?
ReentrantLock は Lock インタフェースを実装したリエントラントかつ独占的なロックで、synchronized と同様の挙動を提供します。ただし、ReentrantLock はより柔軟で、ポーリング、タイムアウト、割り込み、フェアロックとノンフェアロックなどの高度な機能を追加しています。
public class ReentrantLock implements Lock, java.io.Serializable {}ReentrantLock には内部クラス Sync があり、Sync は AQS(AbstractQueuedSynchronizer)を継承しています。ロックの取得と解放の多くの処理は Sync 内で実装されます。Sync には、公平ロック FairSync と非公平ロック NonfairSync の2つのサブクラスがあります。
ReentrantLock はデフォルトで非公平ロックを使用しますが、コンストラクタで公平ロックを指定することもできます。
// boolean 値を渡し、true は公平、false は非公平public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync();}上記のことから、ReentrantLock の下位は AQS によって実現されていることがわかります。
公平鎖と非公平鎖の違いは?
- 公平鎖:ロックが解放された後、先に待っていたスレッドが先にロックを得ます。性能は劣りますが、時間の順序性を保証します。
- 非公平鎖:ロックが解放された後、後から来たスレッドが先にロックを得る可能性があります。性能は高いですが、特定のスレッドが長時間ロックを取得できない可能性があります。
synchronized と ReentrantLock の違いは?
- どちらも再入可能なロックです。
synchronizedは JVM に実装され、K/V などの最適化は JVM 側で行われます。一方、ReentrantLockは API 層の実装で、ソースコードを確認して動作を理解できます。ReentrantLockは待機の中断、公平ロックの選択、複数の条件を結ぶ Condition の使用など、synchronizedにはない高度な機能を提供します。
もし上述の機能を使いたい場合は、ReentrantLock の使用を検討すると良いでしょう。
可中断ロックと不可中断ロックの違いは?
- 可中断ロック:ロックを取得する過程で中断可能。
ReentrantLockは可中断ロックです。lockInterruptibly()のようなメソッドがあります。 - 不可中断ロック:スレッドがロックを要求したら、ロックを取得するまで待つ必要があります。
synchronizedは不可中断ロックです。
ReentrantReadWriteLock
ReentrantReadWriteLock とは?
ReentrantReadWriteLock は ReadWriteLock を実装しており、複数のスレッドが同時に読み取りを行える一方で、書き込み時にはスレッドの安全性を保証します。読み取りロックは共有、書き込みロックは独占です。読み取りロックは複数のスレッドで同時に保持でき、書き込みロックは1スレッドのみ保持できます。
このロックも AQS に基づいて実装されます。
公平鎖と非公平鎖
ReentrantReadWriteLock も公平鎖と非公平鎖をサポートします。デフォルトは非公平です。明示的に指定することもできます。
// 公平ロックを指定public ReentrantReadWriteLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); readerLock = new ReadLock(this); writerLock = new WriteLock(this);}ReentrantReadWriteLock はどんな場面に適しているか?
ReentrantReadWriteLock は、読み込みが多く、書き込みが少ない場合に性能が向上します。複数のスレッドが同時に読み取りを行っても、書き込み待ちのスレッドを適切に排他できます。
共有ロックと排他ロックの違いは?
- 共有ロック:1つのロックを複数のスレッドが同時に取得できます。
- 排他ロック:1つのロックを1つのスレッドのみ取得できます。
読み取りロックを保持しているスレッドは書き込みロックを取得できるか?
- 読み取りロックを保持している状態で書き込みロックを取得することは通常できません。読み取りロックが占有されている場合、書き込みロックを取得しようとすると失敗します。
- 書き込みロックを保持している場合、読み取りロックを取得することは可能です。ただし、書き込みロックが占有されている場合、現在のスレッドが書き込みロックを保持していない状況で読み取りロックの取得は失敗します。
読み取りロックを書き込みロックへアップグレードできない理由は?
読み取りロックを書き込みロックへアップグレードすると、スレッド間の競合が発生し、書き込みロックは独占的です。アップグレードは性能を低下させる可能性があるため、基本的にはサポートされません。デッドロックのリスクもあります。
ThreadLocal
ThreadLocal とは何のためにあるのか?
通常、作成した変数はすべてのスレッドがアクセス・変更できます。各スレッドに専用のローカル変数を持たせたい場合、ThreadLocal が用いられます。ThreadLocal は各スレッドを自分専用の値にバインドすることで、スレッド間のデータ競合を回避します。
ThreadLocal クラスは、各スレッドが自分の値を持つようにすることを主な目的としており、ThreadLocal をデータ格納ボックスのように例えることができます。ThreadLocal を使って get()、set() を行うと、スレッドごとに異なるローカルコピーを取得・更新できます。
ThreadLocal を作成すると、スレッドごとにこの変数のローカルコピーが作成されます。これが ThreadLocal という名前の由来です。
ThreadLocal の使い方
上の説明を見て、ThreadLocal がどういうものか理解できたはずです。以下はプロジェクト内での実際の使用例です。
import java.text.SimpleDateFormat;import java.util.Random;
public class ThreadLocalExample implements Runnable{
// SimpleDateFormat はスレッドセーフではないので、各スレッドに独自のコピーが必要 private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException { ThreadLocalExample obj = new ThreadLocalExample(); for(int i=0 ; i<10; i++){ Thread t = new Thread(obj, ""+i); Thread.sleep(new Random().nextInt(1000)); t.start(); } }
@Override public void run() { System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern()); try { Thread.sleep(new Random().nextInt(1000)); } catch (InterruptedException e) { e.printStackTrace(); } // formatter のパターンはスレッドごとに変更されるが、他のスレッドには影響しない formatter.set(new SimpleDateFormat());
System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern()); }
}出力からわかるように、Thread-0 が formatter の値を変更しても、Thread-1 のデフォルトのフォーマット値は初期値のままです。他のスレッドも同様です。
このコードは Java 8 の知識を使っており、次のようにも書くことができます。Java 8 では withInitial() を導入し、Supplier をパラメータにする方式です。
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){ @Override protected SimpleDateFormat initialValue(){ return new SimpleDateFormat("yyyyMMdd HHmm"); }};ThreadLocal の原理は理解しているか?
ThreadLocal の原理は Thread クラスのソースを見て理解します。
public class Thread implements Runnable { //...... //このスレッドに関係する ThreadLocal の値。ThreadLocal クラスが管理 ThreadLocal.ThreadLocalMap threadLocals = null;
//このスレッドに関係する InheritableThreadLocal の値。InheritableThreadLocal が管理 ThreadLocal.ThreadLocalMap inheritableThreadLocals = null; //......}このように、Thread クラスには threadLocals と inheritableThreadLocals という ThreadLocalMap 型の変数があり、ThreadLocalMap は ThreadLocal の実装によるカスタム・ハッシュマップと理解できます。デフォルトではこの2つの変数は null で、現在のスレッドが ThreadLocal の set または get を呼び出した時に作成されます。実際には ThreadLocalMap に対する get()、set() を呼び出しています。
ThreadLocal の set() の例
public void set(T value) { // 現在のスレッドを取得 Thread t = Thread.currentThread(); // Thread の内部の threadLocals を取得 ThreadLocalMap map = getMap(t); if (map != null) // 保存する値をこのハッシュマップに格納 map.set(this, value); else createMap(t, value);}ThreadLocalMap getMap(Thread t) { return t.threadLocals;}このように、最終的な変数は現在のスレッドの ThreadLocalMap に格納され、ThreadLocal 自体には格納されません。ThreadLocal は単なる ThreadLocalMap のラップとして、値を渡します。ThreadLocal クラス内から Thread.currentThread() を取得した後、getMap(Thread t) によってそのスレッドの ThreadLocalMap オブジェクトにアクセスできます。
各 Thread には ThreadLocalMap があり、ThreadLocalMap は ThreadLocal をキーとして、値を Object として格納することができます。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { //......}例えば同じスレッド内で2つの ThreadLocal オブジェクトを宣言した場合、Thread の内部は唯一の ThreadLocalMap を使ってデータを格納します。ThreadLocalMap のキーは ThreadLocal オブジェクト、値は ThreadLocal が set した値です。
ThreadLocal のデータ構造は以下の図のとおりです。
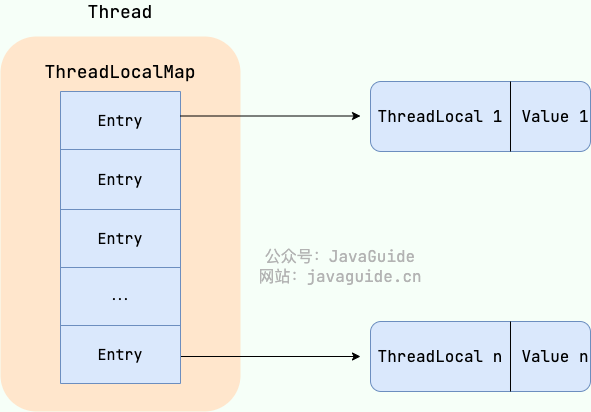
ThreadLocalMap は ThreadLocal の静的内部クラスです。
ThreadLocal のメモリリーク問題はどうして起こるのか?
ThreadLocalMap で使用されるキーは ThreadLocal の弱参照、値は強参照です。そのため、ThreadLocal が外部から強い参照を受けていない場合、ガベージコレクション時にはキーはクリーンされても値はクリーンされません。
このため ThreadLocalMap にはキーが null のエントリが現れます。特に何もしないと、値は GC によって解放されません。これがメモリリークの原因になります。ThreadLocalMap の実装ではこの状況を考慮しており、set()、get()、remove() の呼び出し時にキーが null のレコードをクリアします。使用後は remove() を手動で呼ぶと良いです。
static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value;
Entry(ThreadLocal<?> k, Object v) { super(k); value = v; }}WeakReference の説明:
弱参照はオブジェクトが弱い参照しか持っていない状態のことです。弱参照とソフト参照の違いは、弱参照のオブジェクトはガベージコレクタが走査する時点で、メモリが足りているかどうかに関係なく回収されます。弱参照は参照キューと組み合わせて使うことができ、対象オブジェクトがガベージコレクションで回収された場合、弱参照は参照キューに追加されます。
スレッド・プール
スレッド・プールとは?
スレッド・プールとは、スレッドのリソース・プールを管理する仕組みです。タスクが来た時には、プールからスレッドを取得して処理を行い、処理が完了したらスレッドを解放せず、次のタスクを待機させます。
なぜスレッド・プールを使うのか?
プール化の考え方は広く用いられており、スレッド・プールだけでなく、データベース接続プール、HTTP 接続プールなどもこの思想を応用しています。プール化の趣旨は、資源の取得コストを削減し、資源の利用効率を高めることにあります。
スレッド・プールは資源の制限と管理を提供します。それぞれのプールは、完了済みタスクの数などの基本的な統計情報を保持しています。
以下は「Java concurrency の Arts of Concurrency」から引用した、スレッド・プールを使う利点です:
- リソースの消費を抑える。作成したスレッドを再利用して、スレッド作成・破棄に伴う負荷を軽減します。
- 応答速度を向上させる。タスクが到着した際、スレッドの作成を待つことなく直ちに実行できます。
- スレッドの管理性を向上させる。スレッドは希少資源であり、無制限に作成するとシステム資源を消費し、安定性も低下します。スレッド・プールを使うと統一的に割り当て・調整・監視ができます。
スレッド・プールの作成方法
- ThreadPoolExecutor のコンストラクタを使って作成する(推奨)。
- Executor フレームワークのユーティリティクラス「Executors」を使って作成。
以下のように、さまざまなタイプの ThreadPoolExecutor を作成できます:
- FixedThreadPool: 固定数のスレッドを持つプール。スレッド数は一定。新しいタスクが来ると、空いているスレッドがある場合はすぐ実行。ない場合は、タスクはキューに待機します。キューが満杯になることはありません。
- SingleThreadExecutor: 1つだけスレッドを持つプール。追加のタスクはキューに待機し、先入先出で実行されます。
- CachedThreadPool: 必要に応じてスレッド数を拡張するプール。初期サイズは0。新しいタスクが来ると、空いているスレッドがなければ新しいスレッドを作成します。しばらく新しいタスクが来ない場合はコア・スレッドがタイムアウトして廃棄され、サイズが縮小します。
- ScheduledThreadPool: 指定した遅延後にタスクを実行したり、定期的に実行したりするスレッド・プール。
なぜ内蔵のスレッド・プールを使わないのか?
Alibaba の Java 開発マニュアルの「並行処理」 section には、スレッド資源はスレッド・プールを通じて提供され、アプリケーション内で自前でスレッドを直接作成してはいけないと明記されています。
- 理由:スレッドを作成・破棄する際のコストを削減し、資源の不足を回避するためです。スレッド・プールを使わないと、同じ種類のスレッドが大量に作成され、OOM(Out of Memory)や過度なコンテキスト・スイッチを引き起こす可能性があります。
また、Executors の直接利用には欠点があり、内蔵のスレッド・プールを使うと以下の問題が起こり得ます:
- FixedThreadPool や SingleThreadExecutor は無限の LinkedBlockingQueue を利用するため、キュー長が Integer.MAX_VALUE まで肥大化し、OOM のリスクがある。
- CachedThreadPool は SynchronousQueue を使用するため、タスクが多く実行が遅いと大量のスレッドを作成し、OOM のリスクがある。
- ScheduledThreadPool は DelayedWorkQueue という無限に大きくなる遅延ブロック・キューを使用するため、OOM のリスクがある。
スレッド・プールのパラメータの意味は?
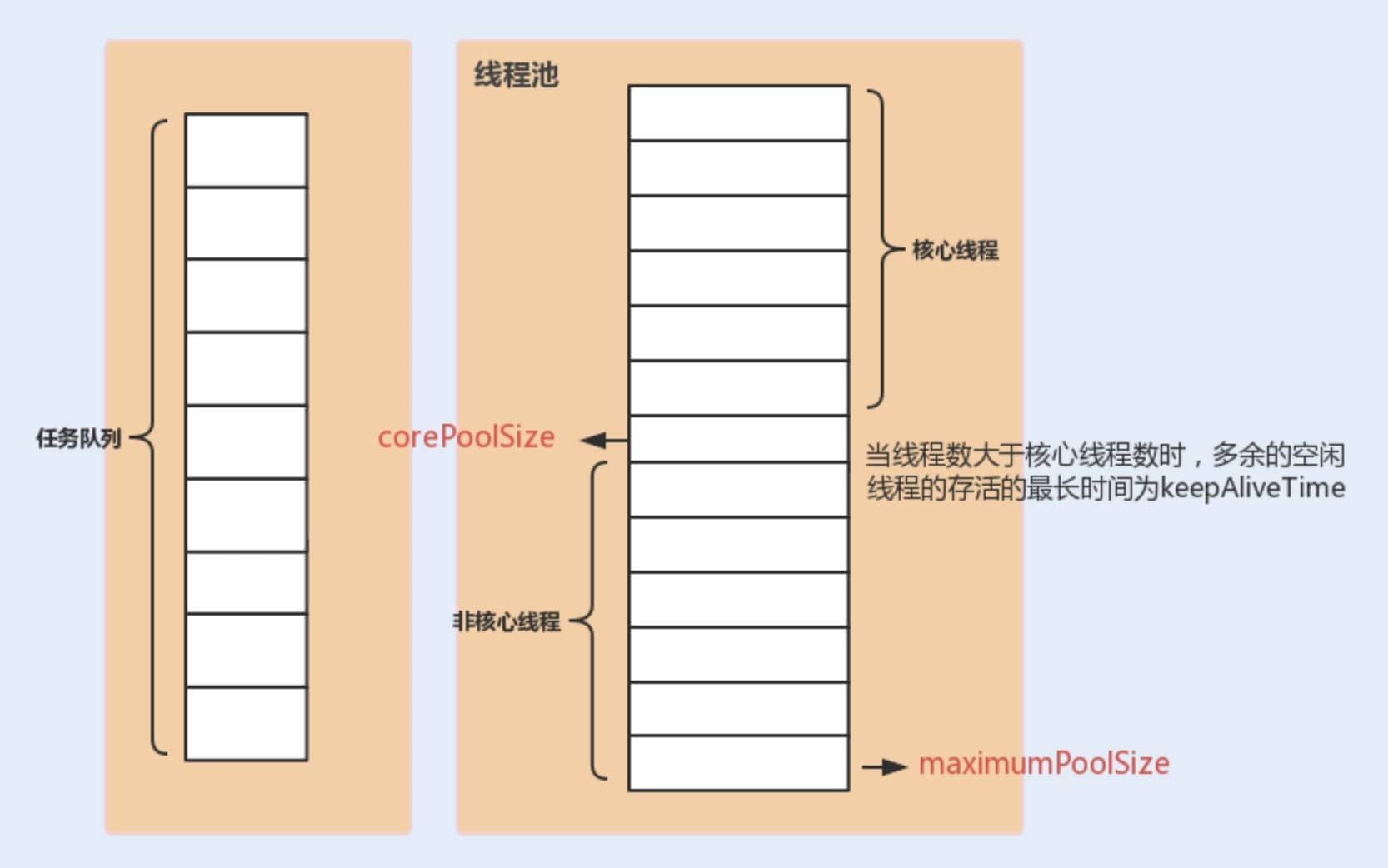
ThreadPoolExecutor の3つの最も重要なパラメータは以下です:
- corePoolSize(コア・プールサイズ):キューが容量に達するまでは、同時に実行できるスレッドの最大数。
- maximumPoolSize(最大スレッド数):キューが容量に達したら、同時に実行できるスレッドの最大数。
- workQueue(タスク・キュー):新しいタスクが来た場合、現在の実行スレッド数がコア・サイズに達しているかどうかを判断します。達している場合、タスクはキューへ格納されます。
その他のパラメータ:
- keepAliveTime:コア数を超えたスレッドのうち、アイドル状態の長さ。これが長いほど非コア・スレッドが長く生存します。
- unit:keepAliveTime の時刻単位。
- threadFactory:新しいスレッドを生成する際に使用されるファクトリ。
- handler:拒否戦略。タスクが過多で処理できない場合の対応を定義します。
以下の図は、スレッド・プールの各パラメータの関係を理解するのに役立ちます。
スレッド・プールの飽和戦略にはどんなものがあるか?
現在のスレッド数が最大スレッド数に達し、かつキューも満杯の場合、ThreadPoolExecutor はいくつかの戦略を提供します:
AbortPolicy:新しいタスクを拒否し、RejectedExecutionExceptionを投げます。CallerRunsPolicy:自分自身のスレッドでタスクを実行します。実行不能なら、タスクを呼び出し側が実行します。これにより新規タスクの提出速度が低下します。DiscardPolicy:新しいタスクを破棄します。DiscardOldestPolicy:最も古い未処理のタスクを破棄します。
例として、Spring の ThreadPoolTaskExecutor や直接 ThreadPoolExecutor のコンストラクタを使って作成する場合、デフォルトは AbortPolicy です。キューが満杯の場合は RejectedExecutionException が投げられます。もしタスクを失いたくない場合は CallerRunsPolicy を使います。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { // 直接メイン・スレッドで実行、スレッド・プールのスレッドではなく r.run(); } } }スレッド・プールでよく使われるブロック・キューは?
新しいタスクが来た際、現在の実行スレッド数がコア・スレッド数に達しているかどうかで判断します。キューには様々なタイプがあり、それぞれの特徴が異なります。
- 容量が Integer.MAX_VALUE の LinkedBlockingQueue(無界): FixedThreadPool と SingleThreadExecutor で使用され、キューが満杯になることは基本的にありません。
- SynchronousQueue(同期キュー): CachedThreadPool で使用。容量はなく、要素を保持しません。利用可能なスレッドがあれば即座に使用し、なければ新しいスレッドを生成します。最大スレッド数は Integer.MAX_VALUE まで到達しうるため、OOM のリスクがあります。
- DelayedWorkQueue(遅延ブロックキュー): ScheduledThreadPool と SingleThreadScheduledExecutor で使用。要素は遅延時間でソートされ、最大容量は Integer.MAX_VALUE です。巨大な要求が来ても、容量を超えない限りはブロックされません。
スレッド・プールがタスクを処理する流れは?
- 現在の実行スレッド数がコア・スレッド数より少ない場合、新しいスレッドを作成してタスクを実行します。
- 現在の実行スレッド数がコア・スレッド数と等しいか、それ以上で、最大スレッド数未満なら、タスクをキューへ入れて待機させます。
- タスクをキューへ投げても実行できない場合、現在の実行スレッド数が最大スレッド数未満なら新しいスレッドを作成します。
- 現在の実行スレッド数が最大スレッド数と等しく、さらに新しいスレッドを作成すると、タスクは拒否され、拒否戦略が
RejectedExecutionHandler.rejectedExecution()を呼び出します。
スレッド・プールの名前を付けるには?
起動時に名前を付ける(スレッド・プール名のプレフィックスを設定する)と、問題の特定がしやすくなります。
デフォルトでは、スレッド名は pool-1-thread-n のようになります。実務では、次の2つの方法でスレッド名を付けることが一般的です。
- Guava の
ThreadFactoryBuilderを使う - 自分で
ThreadFactoryを実装する
ThreadFactory threadFactory = new ThreadFactoryBuilder() .setNameFormat(threadNamePrefix + "-%d") .setDaemon(true).build();ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory);あるいは自分で ThreadFactory を実装します。
import java.util.concurrent.ThreadFactory;import java.util.concurrent.atomic.AtomicInteger;
/** * ThreadFactory that names threads for easier debugging. */public final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger(); private final String name;
/** * Create a thread factory with a given base name */ public NamingThreadFactory(String name) { this.name = name; }
@Override public Thread newThread(Runnable r) { Thread t = new Thread(r); t.setName(name + " [#" + threadNum.incrementAndGet() + "]"); return t; }}スレッド・プールのサイズはどう決めるべきか?
多くの人は、スレッド・プールのサイズを大きくする方が良いと考えがちですが、スレッド数を増やしすぎると、文脈切替のコストが増え、オーバーヘッドが増大します。適切なサイズを決定するには、CPU の実効利用度とタスクの性質を考慮する必要があります。
- CPU 集約型タスク(N+1): コア数 N に対して、N+1 程度が目安かもしれません。追加の 1 は、ページアウトなどの遅延をカバーするためです。
- IO 集約型タスク(2N): IO 待ちの時間に対して、より多くのスレッドを割り当てることでパフォーマンスを改善できる場合があります。
判断の厳密な式としては、最適スレッド数 = N (CPUコア数) * (1 + WT/ST) です。WT はスレッド待機時間、ST はスレッド計算時間です。
- 最適なスレッド数は、WT/ST が高いと多く、低いと少なくなります。
- 実運用では VisualVM などのツールを使って WT/ST の比率を観察すると良いです。
動的にスレッド・プールのパラメータを変更するには?
Meituan の記事「Javaのスレッド・プールの実装原理とMeituanでの実践」では、スレッド・プールのコアパラメータを動的に変更する設計を解説しています。ここではコア・パラメータを動的に設定できるようにするアプローチが述べられています。三つのコアパラメータは次のとおりです。
corePoolSize:コア・スレッド数。最小同時実行数を定義します。maximumPoolSize:キューが満杯になった時、最大同時実行スレッド数を定義します。workQueue:新しいタスクが来たとき、現在の実行スレッド数がコア数に達していれば、タスクはキューへ置かれます。
この3つのパラメータは ThreadPoolExecutor の最も重要なパラメータであり、タスク処理戦略を大きく決定します。
また、corePoolSize にも注意が必要です。実行中に setCorePoolSize() を呼ぶと、現在の作業スレッド数が corePoolSize を超えていれば、それを回収します。
Meituan の方法では、ResizableCapacityLinkedBlockingQueue のような可変容量のキューを自作して実現するケースもあります。実務では、既存のオープンソース・プロジェクトを活用することもあります(以下の例)。
- Hippo4j:非同期スレッド・プールのフレームワーク、スレッド・プールの動的変更、監視、アラームをサポート。コード変更なしで導入可能。
- Dynamic TP:軽量な動的スレッド・プール。監視・アラート機能を内蔵。
タスクの優先度に応じて実行するスレッド・プールを設計するには?
通常、スレッド・プールはキューとして異なるブロック・キューを使用します。例として、FixedThreadPool は無界の LinkedBlockingQueue を使用するため、キューが満杯になることはなく、最大スレッド数はコア数と等しくなります。
優先度タスクを扱う場合、タスク・キューとして PriorityBlockingQueue を使うことが考えられます(ThreadPoolExecutor のコンストラクタには workQueue のパラメータがあり、タスク・キューを渡せます)。
ただし、以下のリスクがあります:
PriorityBlockingQueueは無界であるため、過剰なリクエストが蓄積して OOM の原因になる。- 優先度の低いタスクが長時間実行されず、飢餓問題が起こる可能性がある。
- 要素のソートとスレッドセーフの確保(ReentrantLock を使用する)によって、性能が低下する可能性がある。
この問題を回避するためには、PriorityBlockingQueue を拡張して offer のロジックを上書きし、挿入エントリ数が閾値を超えた場合には false を返す、などの工夫を行います。
飢餓問題は、待機時間が長いタスクを隔定的に削除して再挿入する、あるいは優先度を上げるなどの設計で解決することができます。
なお、実運用では、タスクの優先度と実行時間のトレードオフを検討して、適切な設計を行うことが重要です。
Future
Future とは何の役に立つのか?
Future クラスは、非同期思想を実用する代表的な例です。長時間かかるタスクを実行する場面で、プログラムが待機してしまうことを避け、処理を並行して進めることができます。特定のタスクを実行すると、そのタスクをサブ・スレッドに任せて、他の作業を行い、完了後に Future から結果を取得します。これがマルチスレッド領域のクラシックな Future パターンです。
Java 8 で導入された CompletableFuture は、Future の不便な点を解消します。CompletableFuture はより便利で強力な Future 機能だけでなく、関数型プログラミング、非同期タスクのオーケストレーション・組み合わせ(複数の非同期タスクを連結して、連鎖的な呼び出しを作成)などを提供します。
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {}ここから、CompletableFuture は同時に Future と CompletionStage のインタフェースを実装していることがわかります。
CompletionStage は、非同期計算の「段階」を表します。多くの計算は複数の段階に分けられます。その場合、すべての段階を組み合わせて、非同期計算のパイプラインを形成します。
CompletionStage のメソッドは多く、CompletableFuture の関数型能力はこのインタフェースに与えられています。これらのメソッドのパラメータには Java 8 で導入された関数型プログラミングが多数使用されています。
AQS
AQS とは?
AQS は AbstractQueuedSynchronizer(抽象キューイング・シンクロナイザ)の略で、java.util.concurrent.locks パッケージに属しています。
AQS は抽象クラスであり、ロックと同期機構の構築に用いられます。
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {}AQS は、ロックと同期器を構築するための共通機能を提供します。そのため、AQS を用いることで広く使われる多くの同期器を簡潔かつ高効率に構築できます。例えば ReentrantLock、Semaphore、ReentrantReadWriteLock、SynchronousQueue などはすべて AQS をベースにしています。
AQS の原理は?
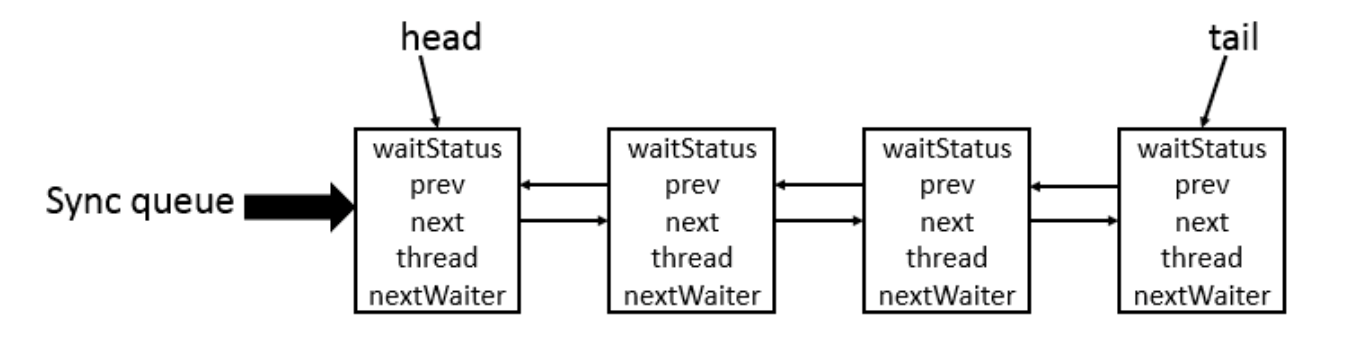
AQS の核心思想は「要求された共有資源が空いている場合、現在の要求元スレッドを有効な作業スレッドとして設定し、資源をロック状態にする。もし資源が占有されている場合は、スレッドをブロックして待機させ、解放時に再開する」というものです。この仕組みは CLH(Craig、Landin、Hagersten)キュー・ロックを用いて実現され、ロックを取得できないスレッドをキューに追加します。
CLH キューは仮想的な双方向キューで、ノードは1つのスレッドを表し、スレッドの参照、ノードの状態、前ノード、後続ノードを保持します。
CLH キュー構造は以下の図のとおりです。
AQS の核心原理図:
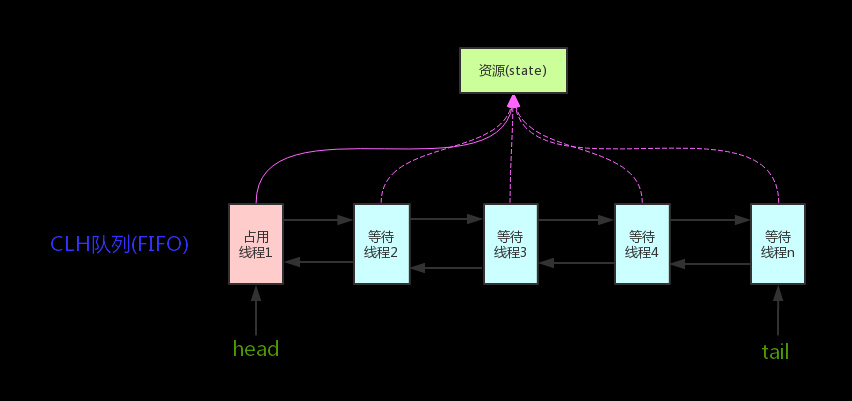
AQS は state という int 型の同期状態を表す変数を持ち、内蔵のスレッド待機キューを通じて資源取得スレッドを待機させます。
state は volatile で宣言され、現在の臨界資源の取得状況を示します。
// 共有変数、volatile で宣言してスレッド可視性を保証private volatile int state;状態情報 state は、protected な getState()、setState()、compareAndSetState() を用いて操作できます。これらのメソッドはすべて final 修飾されており、サブクラスでオーバーライドできません。
// 現在の同期状態の値を返すprotected final int getState() { return state;} // 同期状態の値を設定するprotected final void setState(int newState) { state = newState;}// 現在の同期状態の値が想定値と同じ場合に、更新値で原子的に設定するprotected final boolean compareAndSetState(int expect, int update) { return unsafe.compareAndSwapInt(this, stateOffset, expect, update);}例として、ReentrantLock を取ると、state の初期値は 0(未ロック)です。lock() の時に tryAcquire() が呼ばれ、ロックを独占して state を 1 にします。以後、他のスレッドが tryAcquire() を呼ぶと失敗します。unlock() で state が 0 へ戻るまで、他のスレッドの取得が可能になります。ここで、同じスレッドは再度 lock() を呼べば state が増加しますが、同じ回数だけ解放する必要があります。これが再入可能の概念です。
CountDownLatch を例にすると、タスクを N 個のサブ・スレッドで実行し、それぞれが終了時に countDown() を呼ぶと、state が CAS で 1 ずつデクリメントされ、全てのスレッドが完了すると待機しているスレッドが再開します。
Semaphore は何に使うか?
synchronized と ReentrantLock は、1 回の時には 1 つのスレッドだけ資源へアクセスさせる排他ロックを提供します。一方、Semaphore は特定の資源に同時にアクセスできるスレッド数を制御するための信号量です。
Semaphore の使用は簡単で、複数のスレッドが共有資源を取得する場合の同時獲得数を制限できます。
final Semaphore semaphore = new Semaphore(5);semaphore.acquire(); // 1 つの許可を取得semaphore.release(); // 許可を開放この場合、初期値が 5 のため、5 つの許可を同時に保持でき、それ以外は待機します。なお、公平 モードと 非公平 モードを切り替えることができます。
CountDownLatch とは?
CountDownLatch は、count 個のスレッドがある所にブロックされ、全てのスレッドが完了するとブロックが解除されます。CountDownLatch は一度きりのカウントダウン・ゲートで、構築時にカウントを設定すると以後変更できません。
CountDownLatch の原理は?
CountDownLatch は共用ロックの実装で、state は初期値 count で設定されます。countDown() を呼ぶと、state を CAS で 1 減らし、0 になれば待機中のスレッドを解放します。await() は state が 0 になるまで待機します。
CountDownLatch を用いた例
public class CountDownLatchExample1 { // 処理するファイルの数 private static final int threadCount = 6;
public static void main(String[] args) throws InterruptedException { // 固定スレッド数のスレッド・プールを作成 ExecutorService threadPool = Executors.newFixedThreadPool(10); final CountDownLatch countDownLatch = new CountDownLatch(threadCount); for (int i = 0; i < threadCount; i++) { final int threadnum = i; threadPool.execute(() -> { try { // ファイル処理のビジネス処理 //...... } catch (InterruptedException e) { e.printStackTrace(); } finally { // 1 ファイル完了を表す countDownLatch.countDown(); }
}); } countDownLatch.await(); threadPool.shutdown(); System.out.println("finish"); }}改善案として、CompletableFuture を使う方法があります。Java 8 の CompletableFuture は多くの非同期操作を扱いやすく、非同期・連結・組み合わせ・全体の完了待機などを簡単に記述できます。
CompletableFuture<Void> task1 = CompletableFuture.supplyAsync(()->{ // 自作ビジネス処理 });......CompletableFuture<Void> task6 = CompletableFuture.supplyAsync(()->{ // 自作ビジネス処理 });......CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
try { headerFuture.join();} catch (Exception ex) { //......}System.out.println("all done. ");上のコードはさらに最適化可能です。タスクが多い場合には、個々の task を列挙するのは現実的ではありません。ループでタスクを追加する方法を検討します。
// ファイルの場所List<String> filePaths = Arrays.asList(...)// 全ファイルを非同期処理List<CompletableFuture<String>> fileFutures = filePaths.stream() .map(filePath -> doSomeThing(filePath)) .collect(Collectors.toList());// それらをまとめるCompletableFuture<Void> allFutures = CompletableFuture.allOf( fileFutures.toArray(new CompletableFuture[fileFutures.size()]));CyclicBarrier は何に使うか?
CyclicBarrier は CountDownLatch に非常に似ており、スレッド間の技術的待機を実現します。違いはその機能の複雑さと強さにあります。
CountDownLatch は AQS に基づく実装ですが、CyclicBarrier は ReentrantLock(ReentrantLock も AQS の同期器の一部)と Condition に基づいています。
CyclicBarrier の直訳は「循環の障壁」で、グループのスレッドが「到着」して barrier に達したときに待機を解除し、全員が barrier を通れるようにします。
CyclicBarrier の原理は?
CyclicBarrier は内部で count 変数をカウントとして使用します。parties 引数で初期化され、スレッドが await() を呼ぶとカウントを減らします。カウントが 0 になると、 barrier 内で指定されたタスクを実行します。
- デフォルトのコンストラクタ
CyclicBarrier(int parties)は、 barrier のスレッド数を表すpartiesを受け取り、await()は barrier に到着したことを通知します。 await()が呼ばれるとdowait(false, 0L)が実行されます。 barrier に到着したスレッドが全員揃うまで待機します。全員が揃った時 barrier が開き、待機していたスレッドが解放されます。
この章の続きや、他の詳細は公式ドキュメントを参照してください。
[以下、本文は Markdown のフォーマットに従い、コードブロックはそのまま保持します]
この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります