


















本文は黒馬のredis動画を基に作成しました
redis実戦-モールシステム
- SMSログイン:Redisでセッションを共有して実現
- 商人検索キャッシュ:キャッシュのキャッシュ撃穿、キャッシュ透過、キャッシュ崩壊などの問題を理解する
- クーポン秒殺:Redisのカウンター機能を使い、Luaと組み合わせて高性能なRedis操作を実現すると同時に、Redisの分散ロックの原理を理解する。Redisの3つのメッセージキューを含む
- 近くの商店:RedisのGEOHashを活用して地理座標の操作を実現
- UV統計:Redisを用いて統計機能を実現
- ユーザーサインイン:RedisのBitmapデータ統計機能
- 友達フォロー:Set集合を基にしたフォロー、フォロー解除、相互フォローなどの機能
- 店を探る:Listを基にいいねリストの操作を実現、さらにSortedSetを用いていいねのランキング機能を実現
プロジェクト構造モデル:
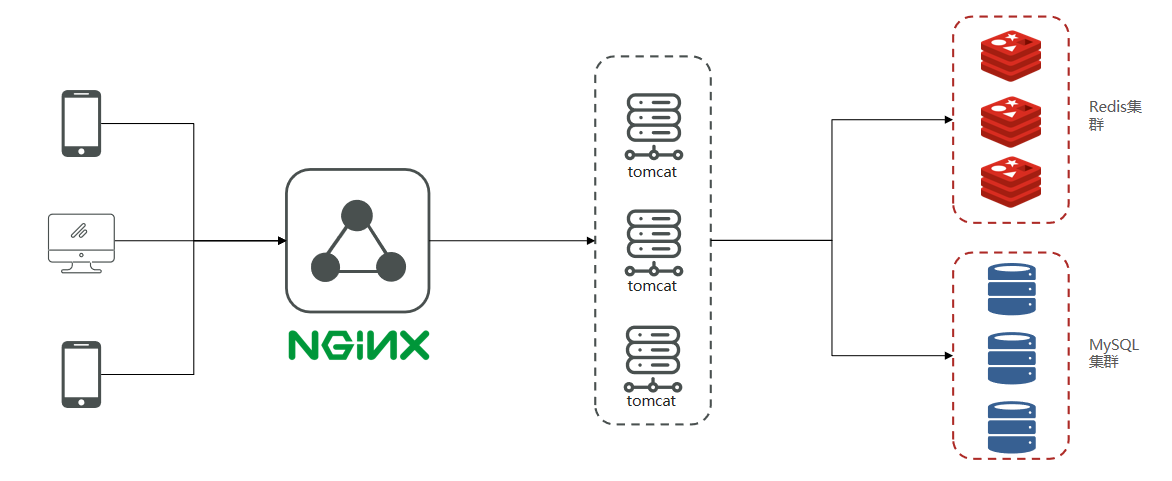
スマホ端末またはアプリからリクエストを発し、私たちのnginxサーバにアクセスします。nginxは7層モデルに基づくHTTPプロトコルを使用し、Luaを使ってTomcatを経由せずRedisにアクセスすることも可能ですし、静的リソースサーバとしても機能します。数万の同時接続を楽に処理し、下流のTomcatサーバへロードバランスで振り分け、トラフィックを分散します。我々が知っている通り、4コア8GBのTomcatは、最適化と単純なビジネス処理の支援を受けても、最大で約1000程度の同時実行を処理します。nginxのロードバランシングと流量分散を経て、クラスターがプロジェクト全体を支えます。同時に、フロントエンドプロジェクトをデプロイした後のnginxは、動的資源と静的資源を分離でき、Tomcatサーバの負荷をさらに低減します。これらの機能はすべてnginxが機能することで実現しますので、nginxはプロジェクト全体で重要な要素です。
Tomcatが並行トラフィックを支えるようになった後、Tomcatを直接MySQLにアクセスさせる場合、経験則としてエンタープライズ向けMySQLサーバは、ある程度の同時実行が増えると、一般的には16コアまたは32コアのCPU、32GBまたは64GBのメモリを必要とします。エンタープライズ級のMySQLにSSDを組み合わせると、想定される並行度はおおよそ4000~7000程度、1万を超える同時接続になると、瞬時にMySQLサーバのCPUとディスクが満杯となり、クラッシュしやすくなります。したがって高い並行シナリオではMySQLクラスターを採用します。さらにMySQLの負荷を低減し、アクセス性能を向上させるため、Redisを導入します。また、Redisクラスターを使用してRedisが外部に対してより良いサービスを提供します。
SMSログイン
セッションを介した検証コード実装
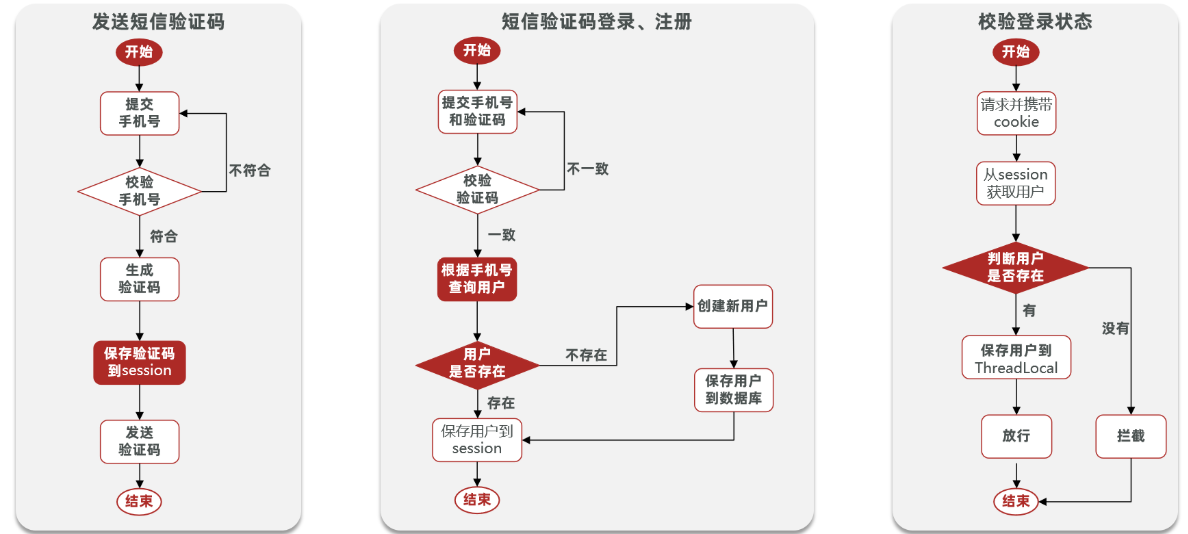
- 検証コードを送信
@Override public Result sendCode(String phone, HttpSession session) { // 1.電話番号の検証 if (RegexUtils.isPhoneInvalid(phone)) { // 2.条件を満たさない場合、エラーメッセージを返す return Result.fail("手机号格式错误!"); } // 3.条件を満たす場合、検証コードを生成 String code = RandomUtil.randomNumbers(6);
// 4.セッションに検証コードを保存 session.setAttribute("code",code); // 5.検証コードを送信 log.debug("发送短信验证码成功,验证码:{}", code); // OKを返す return Result.ok(); }- ログイン
@Override public Result login(LoginFormDTO loginForm, HttpSession session) { // 1.電話番号の検証 String phone = loginForm.getPhone(); if (RegexUtils.isPhoneInvalid(phone)) { // 2.条件を満たさない場合、エラーメッセージを返す return Result.fail("手机号格式错误!"); } // 3.検証コードの検証 Object cacheCode = session.getAttribute("code"); String code = loginForm.getCode(); if(cacheCode == null || !cacheCode.toString().equals(code)){ //3.不一致、エラー return Result.fail("验证码错误"); } // 一致、電話番号でユーザーを検索 User user = query().eq("phone", phone).one();
//5.ユーザーの存在を判断 if(user == null){ // 存在しない場合、作成 user = createUserWithPhone(phone); } //7.セッションにユーザー情報を保存 session.setAttribute("user",user);
return Result.ok(); }- ログインインターセプター
インターセプターコード
public class LoginInterceptor implements HandlerInterceptor {
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //1.セッションを取得 HttpSession session = request.getSession(); //2.セッション内のユーザーを取得 Object user = session.getAttribute("user"); //3.ユーザーの存在を判定 if(user == null){ //4.存在しない場合、インターセプト response.setStatus(401); return false; } //5.存在する場合、ThreadLocalへ保存 UserHolder.saveUser((User)user); //6.通過 return true; }}拡張を有効化
@Configurationpublic class MvcConfig implements WebMvcConfigurer {
@Resource private StringRedisTemplate stringRedisTemplate;
@Override public void addInterceptors(InterceptorRegistry registry) { // ログインインターセプター registry.addInterceptor(new LoginInterceptor()) .excludePathPatterns( "/shop/**", "/voucher/**", "/shop-type/**", "/upload/**", "/blog/hot", "/user/code", "/user/login" ).order(1); // トークン更新インターセプター registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0); }}- 安全返却オブジェクトの変更
//7.保存ユーザー情報をsessionへsession.setAttribute("user", BeanUtils.copyProperties(user,UserDTO.class));
//5.存在時、ThreadLocalへユーザー情報を保存UserHolder.saveUser((UserDTO) user);Redisを代替するセッション実装
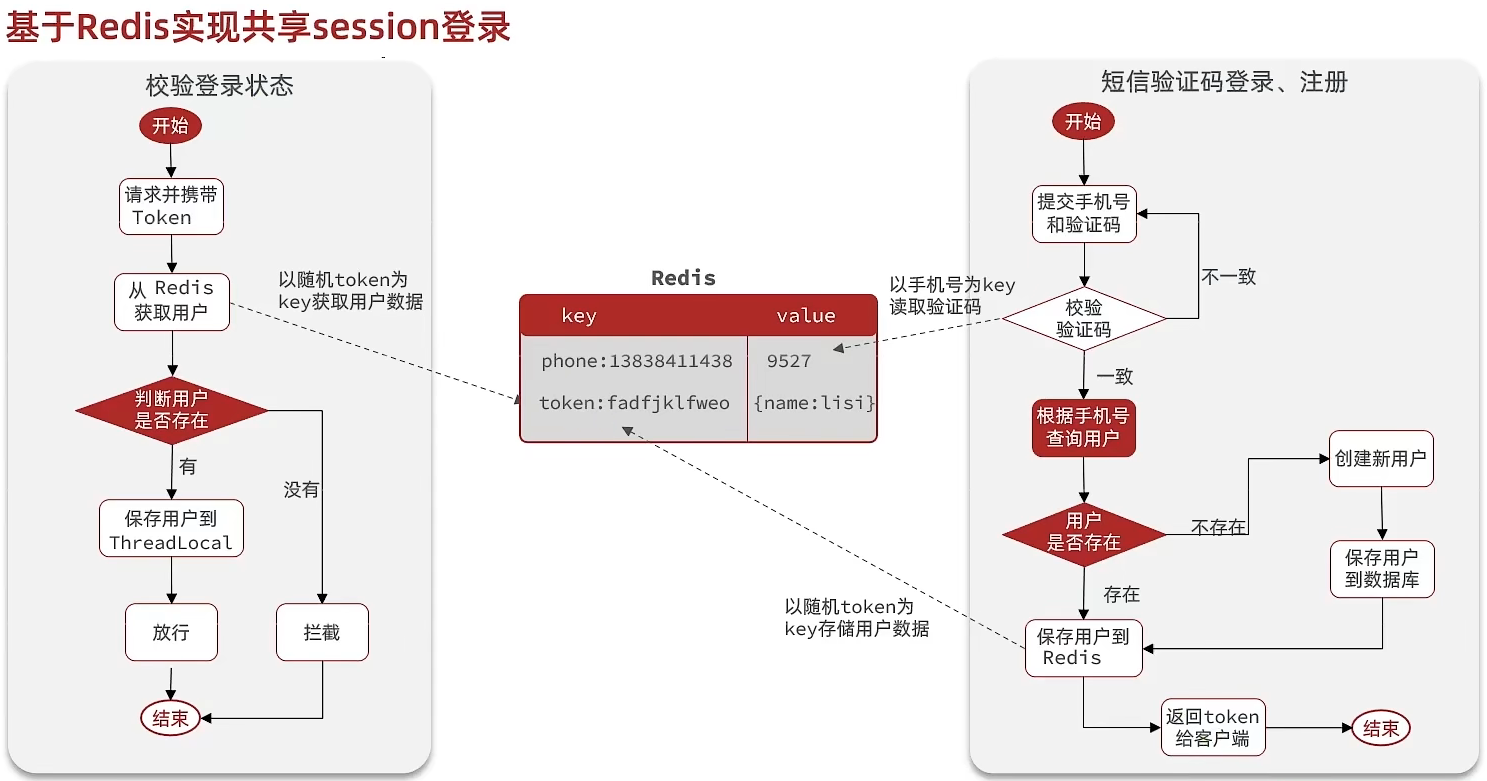
@Overridepublic Result login(LoginFormDTO loginForm, HttpSession session) { // 1.電話番号の検証 String phone = loginForm.getPhone(); if (RegexUtils.isPhoneInvalid(phone)) { // 2.不適合の場合エラーを返す return Result.fail("手机号格式错误!"); } // 3.Redisから検証コードを取得して検証 String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone); String code = loginForm.getCode(); if (cacheCode == null || !cacheCode.equals(code)) { // 不一致、エラー return Result.fail("验证码错误"); }
// 4.一致、電話番号でユーザーを検索 User user = query().eq("phone", phone).one();
// 5.判断して存在しなければ新規作成 if (user == null) { user = createUserWithPhone(phone); }
// 7.ユーザー情報をRedisに保存 // 7.1.トークンをランダム生成、ログイントークンとして使用 String token = UUID.randomUUID().toString(true); // 7.2.UserオブジェクトをHashMapへ変換して保存 UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class); Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(), CopyOptions.create() .setIgnoreNullValue(true) .setFieldValueEditor((fieldName, fieldValue) -> fieldValue.toString())); // 7.3.保存 String tokenKey = LOGIN_USER_KEY + token; stringRedisTemplate.opsForHash().putAll(tokenKey, userMap); // 7.4.有効期限を設定 stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.トークンを返す return Result.ok(token);}状态ログインのリフレッシュ
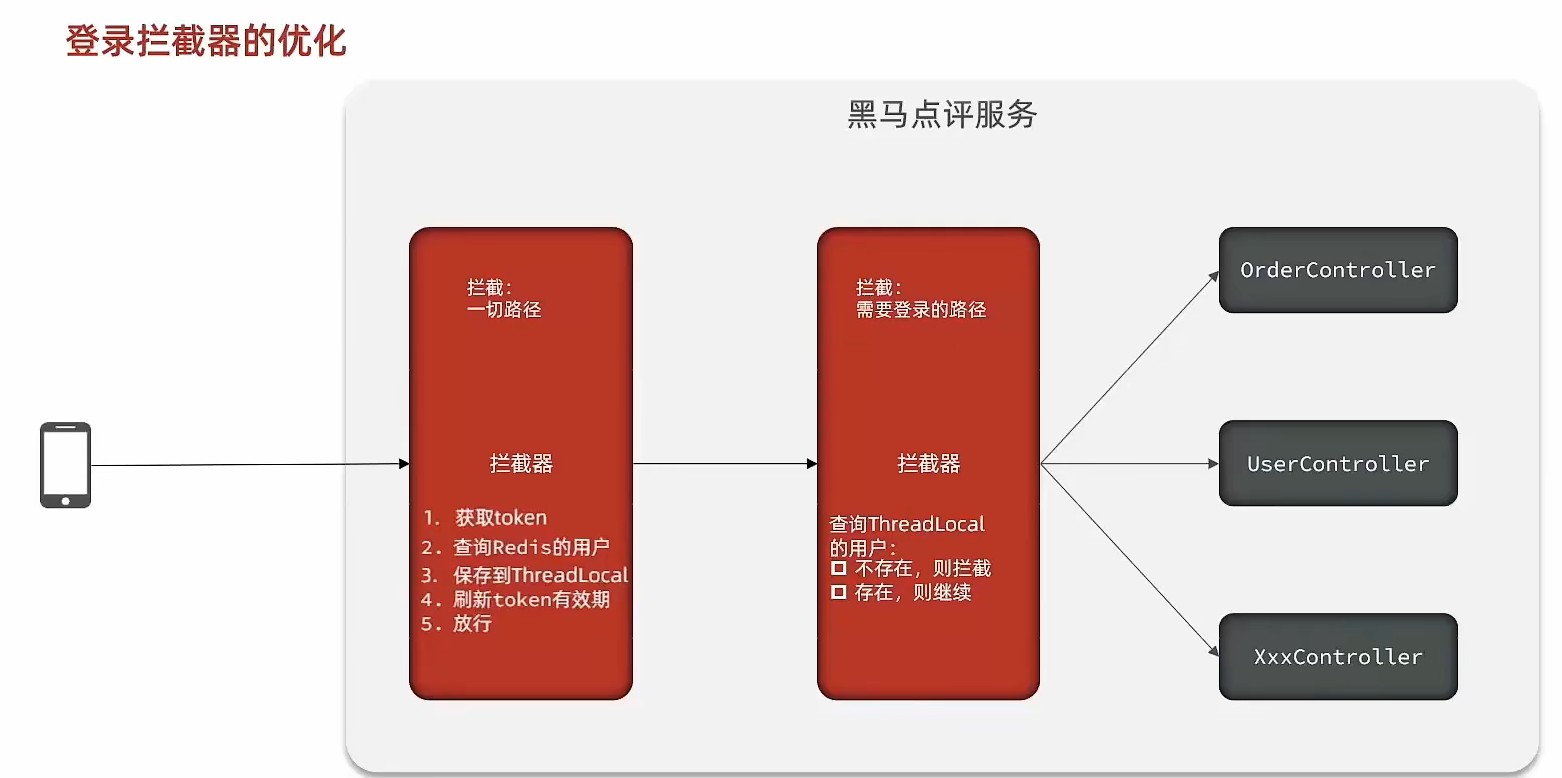
RefreshTokenInterceptor
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; }
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1.リクエストヘッダからtokenを取得 String token = request.getHeader("authorization"); if (StrUtil.isBlank(token)) { return true; } // 2.TOKENを基にRedisのユーザーを取得 String key = LOGIN_USER_KEY + token; Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key); // 3.ユーザーが存在するか if (userMap.isEmpty()) { return true; } // 5.HashデータをUserDTOへ変換 UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false); // 6.存在する場合、ThreadLocalへ保存 UserHolder.saveUser(userDTO); // 7.トークン有効期限を更新 stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES); // 8.直ちにリクエストを通過 return true; }
@Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { // ユーザーを削除 UserHolder.removeUser(); }}LoginInterceptor
public class LoginInterceptor implements HandlerInterceptor {
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1. ThreadLocalにユーザーが存在するかを判断 if (UserHolder.getUser() == null) { // ない場合、401を設定して遮断 response.setStatus(401); return false; } // ある場合、通過 return true; }}商户検索キャッシュ
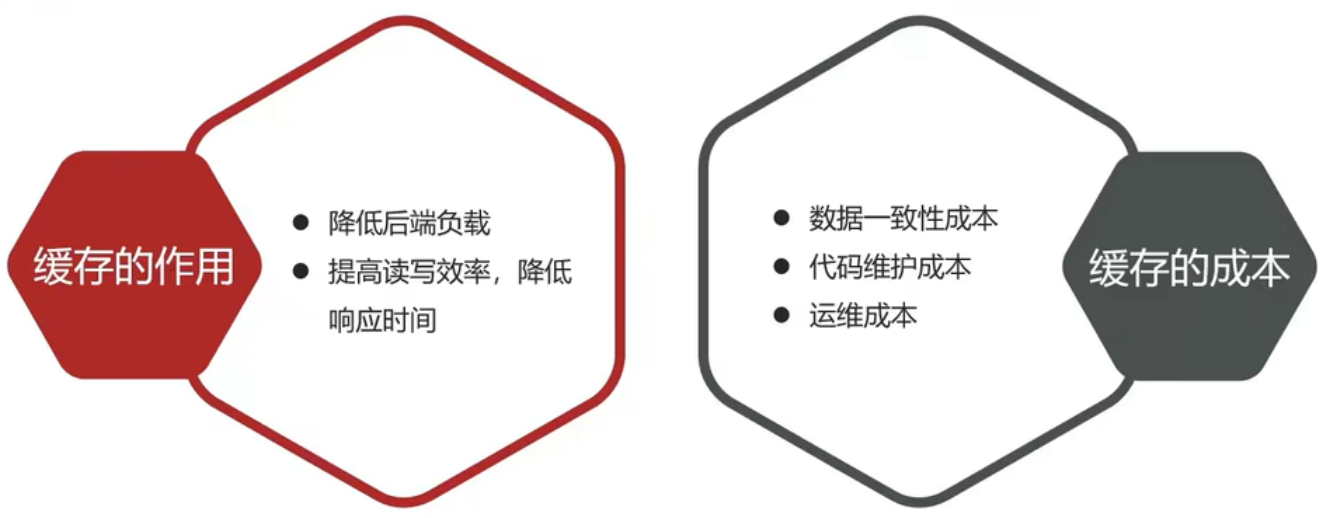
**キャッシュ(Cache)は、データの交換のためのバッファであり、一般にキャッシュとは「バッファ内のデータ」のことを指します。通常、データベースから取得したデータをローカルのコードに格納します(例:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发
例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存
例3:Static final Map<K,V> map = new HashMap(); 本地缓存)そのままです)そのため Staticで修飄されているので、クラスがロードされる際にメモリへロードされ、ローカルキャッシュとして機能します。また final修飾によって参照とオブジェクトの関係が固定され、代入によるキャッシュの無効化を心配する必要が少なくなります。
ブラウザキャッシュ:主にブラウザ側に存在するキャッシュ
- *アプリケーション層キャッシュ:Tomcatのローカルキャッシュ(先に述べたmap)やRedisをキャッシュとして使用することができます
- *データベースキャッシュ:データベースにはバッファプールという領域があり、データの追加・変更・検索はまずMySQLのキャッシュへロードされます
- *CPUキャッシュ:現代のコンピュータで最も大きい課題はCPUの性能向上にもかかわらず、メモリの読み書き速度が追いついていない点です。したがって現在の状況に適応するため、CPUのL1、L2、L3キャッシュを追加しました
商户缓存
標準の操作は、データベースを問合せる前にまずキャッシュを問合せます。キャッシュデータが存在すればキャッシュから直接返します。キャッシュデータが存在しない場合はデータベースを問合せ、データをRedisに格納します。
@Overridepublic Result queryById(Long id) { String key = RedisConstants.CACHE_SHOP_KEY + id; String shopJson = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isNotBlank(shopJson)) { Shop shop = JSONUtil.toBean(shopJson,Shop.class); return Result.ok(shop); } Shop shop = getById(id); if(shop == null) { return Result.fail("店铺不存在!"); } stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);}キャッシュとデータベースの二重書き
- キャッシュ更新
- メモリ淘汰:Redisは自動的に行います。Redisのメモリが設定したmax-memoryに達すると、自動的に淘汰機構を発動して重要でないデータを削除します(戦略は自分で設定可能)
- タイムアウト除去:RedisにTTLを設定した場合、期限切れデータを削除してキャッシュの継続利用を容易にします
- アクティブ更新:キャッシュを手動で削除する方法を呼び出します。通常はキャッシュとデータベースの不一致問題を解決するため
- データベースキャッシュの不一致
Cache Aside Patternは手動コード方式。キャッシュの呼び出し元がデータベースを更新した後、キャッシュを更新します。いわゆるダブルライト方式です。
Read/Write Through Patternはシステム自体が実行します。データベースとキャッシュの問題をシステム自体で処理します。
Write Behind Caching Patternは、呼出元がキャッシュのみを操作し、他のスレッドがデータベースを非同期に処理して最終的に一貫性を実現します。
- 人工的なコーディング方式
- キャッシュを削除するべきか、更新するべきか?
- 更新キャッシュ:データベースを更新するたびキャッシュを更新します。無効な書き込み操作が多い
- キャッシュを削除:データベースを更新する際にキャッシュを無効化し、クエリ時に再度キャッシュを更新
- キャッシュとデータベースの操作を同時に成功させるには?
- 単一システムでは、キャッシュとデータベース操作を1つのトランザクションに置く
- 分散システムではTCC等の分散トランザクションを活用
- 先にデータベースを操作し、次にキャッシュを削除
- キャッシュを削除するべきか、更新するべきか?
商铺のキャッシュとデータベースの二重書きの整合性
ShopControllerのビジネスロジックを修正して、以下の要件を満たすようにします:
IDで店舗を検索した場合、キャッシュがヒットしない場合はデータベースを検索し、データベースの結果をキャッシュへ書き込み、TTLを設定します
IDで店舗を更新した場合、まずデータベースを更新し、その後キャッシュを削除します
// クエリ時に期限を取得stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 更新メソッドの追加@Override@Transactionalpublic Result update(Shop shop) { Long id = shop.getId(); if (id == null) { return Result.fail("店铺id不能为空"); } updateById(shop);
stringRedisTemplate.delete(RedisConstants.CACHE_SHOP_KEY + id); return Result.ok();
}キャッシュ透過
- キャッシュ透過:キャッシュ透過とは、キャッシュにもデータベースにも要求されるデータが存在しない状態を指します。この場合、キャッシュは有効にはなりません。全てのリクエストがデータベースに到達します。
よくある解決策は2つです:
-
キャッシュの空オブジェクト
クライアントが存在しないデータにアクセスする場合、最初にRedisを参照しますが、データがRedisに存在しません。この場合データベースにもデータが存在しなく、データ透過が起こります。データがデータベースにも存在しない場合でも、Redisにこのデータを保存します。次回同じデータを参照する際にはRedisで見つかるため、キャッシュには再びアクセスされず、データベースへのアクセスを回避できます。
- 利点:実装は簡単、保守性が高い
- 欠点:
- 追加のメモリ消費
- 短期的な一貫性の崩れの可能性
-
ブルームフィルター
ブルームフィルターはハッシュの考え方を用いて問題を解決します。巨大な2進配列を用い、ハッシュで現在検索対象のデータが存在するかを判断します。ブルームフィルターが存在すると判断した場合、そのデータは存在するものとして通過します。このリクエストはRedisへ行きます。Redisのデータが期限切れであっても、データベースには必ずそのデータが存在します。データベースでデータを取得してRedisへ戻します。ブルームフィルターが存在しないと判断した場合は直接戻します。
- 利点:メモリ使用量が少なく、余分なキーがない
- 欠点:
- 実装が複雑
- 誤判定の可能性がある
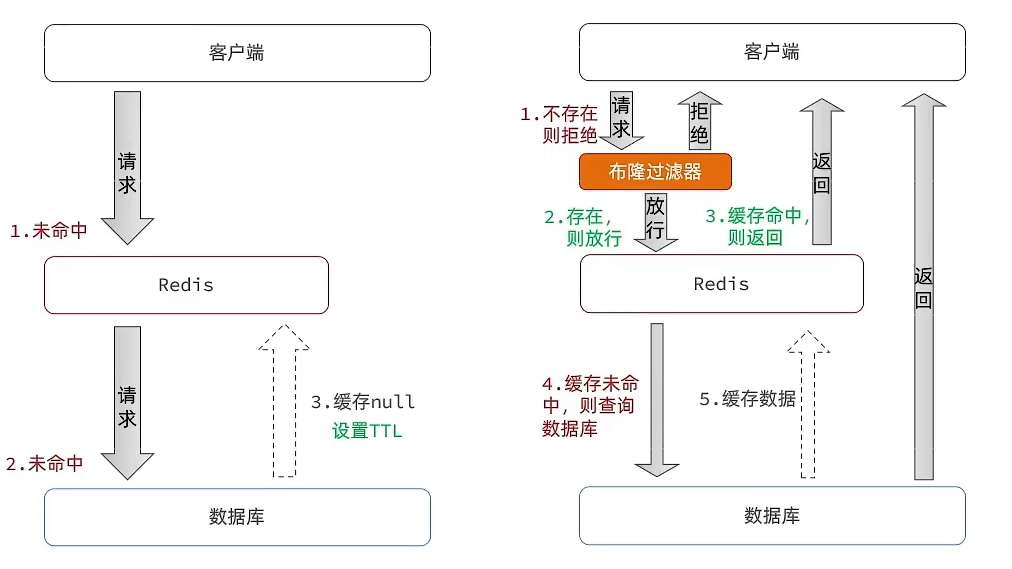
@Overridepublic Result queryById(Long id) { String key = RedisConstants.CACHE_SHOP_KEY + id; String shopJson = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isNotBlank(shopJson)) { Shop shop = JSONUtil.toBean(shopJson,Shop.class); return Result.ok(shop); } // キャッシュが空値かどうかを判定 if(shopJson != null) { return Result.fail("店铺信息不存在"); }
Shop shop = getById(id); if(shop == null) { // 空値をキャッシュに書き込む stringRedisTemplate.opsForValue().set(key,"", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES); return Result.fail("店铺不存在!"); } stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);}キャッシュ透過の解決策は何ですか?
- キャッシュのnull値
- ブルームフィルター
- idの複雑性を高め、推測されにくくする
- データの基本フォーマット検証を徹底する
- ユーザー権限の検証を強化する
- ホットパラメータのレート制限を設ける
キャッシュ崩壊
キャッシュ崩壊は、同時期に大量のキャッシュキーが同時に失効する、またはRedisサービスがダウンして大量のリクエストがデータベースへ到達し、巨大な負荷を引き起こす状態を指します。
解決策:
- 異なるキーごとにTTLの乱数を付与する
- Redisクラスタを活用してサービスの可用性を高める
- キャッシュビジネスにデグレードとレート制限の戦略を追加する
- ビジネスに多段キャッシュを追加する
キャッシュ撃穿
キャッシュ撃穿問題、別名ホットキー問題は、高負荷でアクセスされ、キャッシュ再構築の処理が複雑なキーが突然失効した場合に、多数のリクエストがデータベースへ即座に大きな衝撃を与えます。
よくある解決策は二つです:
- 排他ロック:排他性を保証するため、データの整合性が保たれ、実装が簡単です。ロックを1つだけ追加するだけで、他の処理は特に配慮する必要がなく、追加のメモリ消費はありません。欠点はロックがあるとデッドロックの問題が発生する可能性があり、基本的に直列実行になるためパフォーマンスに影響が出ます。
- 論理有効期限:スレッドの読み取り中に待つ必要がなく、高速です。データの再構築を行う別スレッドがあらかじめロックを保持し、データの再構築完了まで他のスレッドは以前のデータを返すだけです。実装は少し複雑です。
排他ロックでキャッシュ撃穿を解決
検索後、キャッシュにデータがなければ排他ロックを取得します。ロックを取得したら、ロックを取得できたかを判定します。取得できなかった場合は待機して再試行します。ロックを取得したスレッドが再度検索を実行し、結果をRedisへ書き込み、ロックを解放してデータを返します。排他ロックを使うことで、同時にデータベースへアクセスする数を1に抑え、キャッシュ撃穿を防ぎます。
private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", RedisConstants.LOCK_SHOP_TTL, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag);}
private void unlock(String key) { stringRedisTemplate.delete(key);}
public Shop queryWithMutex(Long id) { String key = CACHE_SHOP_KEY + id; // 1、Redisから店舗キャッシュを取得 String shopJson = stringRedisTemplate.opsForValue().get("key"); // 2、存在判定 if (StrUtil.isNotBlank(shopJson)) { // 存在、直接返す return JSONUtil.toBean(shopJson, Shop.class); } // 命中値が空値かどうかを判定 if (shopJson != null) { // エラー情報を返す return null; } // 4.キャッシュ再構築の実装 //4.1 排他ロックを取得 String lockKey = RedisConstants.LOCK_SHOP_KEY + id; Shop shop = null; try { boolean isLock = tryLock(lockKey); // 4.2 取得成功か判定 if(!isLock){ // 4.3 失敗、スリープしてリトライ Thread.sleep(50); return queryWithMutex(id); } // 4.4 ロック取得成功、DBを検索 shop = getById(id); // 5.存在しない場合、空値をRedisへ書き込み if(shop == null){ stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES); return null; } // 6. Redisへ書き込み stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES);
}catch (Exception e){ throw new RuntimeException(e); } finally { // 7.排他ロックを解放 unlock(lockKey); } return shop;}論理有効期限でキャッシュ撃穿を解決
ユーザーがRedisを検索開始時、ヒットしない場合は空データを返します。ヒットした場合、値を取り出し、値の有効期限が満たされているかを判定します。未だ有効ならRedisのデータをそのまま返します。期限切れの場合、独立したスレッドを起動してデータを再構築します。再構築完了後、排他ロックを解放します。
@Datapublic class RedisData { private LocalDateTime expireTime; private Object data;}
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire(Long id) { String key = CACHE_SHOP_KEY + id; // 1. RedisからJSONを取得 String json = stringRedisTemplate.opsForValue().get(key); // 2. 存在判定 if (StrUtil.isBlank(json)) { return null; } // 4.ヒットしたので、JSONをオブジェクトへデシリアライズ RedisData redisData = JSONUtil.toBean(json, RedisData.class); Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class); LocalDateTime expireTime = redisData.getExpireTime(); // 5.期限判定 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1 未期限、直接返す return shop; } // 5.2 期限切れ、キャッシュ再構築が必要 // 6. キャッシュ再構築 // 6.1 排他ロックを取得 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2 ロック取得判定 if (isLock){ CACHE_REBUILD_EXECUTOR.submit( ()->{
try{ // キャッシュを再構築 this.saveShop2Redis(id,20L); }catch (Exception e){ throw new RuntimeException(e); }finally { unlock(lockKey); } }); } // 6.4 期限切れの店舗情報を返す return shop;}
public void saveShop2Redis(Long id,Long expireSeconds) { Shop shop = getById(id);
RedisData redisData = new RedisData(); redisData.setData(shop); redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(redisData));}Redisツールクラスのカプセル化
StringRedisTemplateをベースに、以下の要件を満たすキャッシュツールクラスをラップします:
- 方法1:任意のJavaオブジェクトをJSONに直列化して、TTLを設定してstring型キーに格納
- 方法2:任意のJavaオブジェクトをJSONに直列化して、string型キーに格納、論理的な有効期限を設定してキャッシュ撃穿を処理
- 方法3:指定のキーでキャッシュを検索し、指定型へデシリアライズ。キャッシュ空値を利用してキャッシュ透過を解決
- 方法4:指定のキーでキャッシュを検索し、指定型へデシリアライズ。論理的有効期限を活用してキャッシュ撃穿を解決
@Slf4j@Componentpublic class CacheClient {
private final StringRedisTemplate stringRedisTemplate;
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public CacheClient(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; }
public void set(String key, Object value, Long time, TimeUnit unit) { stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit); }
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) { // 論理有効期限を設定 RedisData redisData = new RedisData(); redisData.setData(value); redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time))); // Redisへ書き込み stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData)); }
public <R,ID> R queryWithPassThrough( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){ String key = keyPrefix + id; // 1.Redisからキャッシュを取得 String json = stringRedisTemplate.opsForValue().get(key); // 2.存在判定 if (StrUtil.isNotBlank(json)) { // 3.存在、型へ変換して返す return JSONUtil.toBean(json, type); } // キャッシュが空値かどうか if (json != null) { // エラーを返す return null; }
// 4.存在しない場合、DBを照会 R r = dbFallback.apply(id); // 5.存在しなければ、空値をキャッシュへ if (r == null) { stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES); return null; } // 6.存在する場合、Redisへ書き込み this.set(key, r, time, unit); return r; }
public <R, ID> R queryWithLogicalExpire( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.Redisからキャッシュを取得 String json = stringRedisTemplate.opsForValue().get(key); // 2.存在判定 if (StrUtil.isBlank(json)) { return null; } // 4.ヒット、先にJSONをオブジェクトへデシリアライズ RedisData redisData = JSONUtil.toBean(json, RedisData.class); R r = JSONUtil.toBean((JSONObject) redisData.getData(), type); LocalDateTime expireTime = redisData.getExpireTime(); // 5.期限判定 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1 未期限、返す return r; } // 5.2 期限切れ、キャッシュ再構築 // 6. キャッシュ再構築 // 6.1 排他ロックを取得 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2 ロックが取得できた場合、再構築を開始 if (isLock){ CACHE_REBUILD_EXECUTOR.submit(() -> { try { // DB照会 R newR = dbFallback.apply(id); // 再構築 this.setWithLogicalExpire(key, newR, time, unit); } catch (Exception e) { throw new RuntimeException(e); }finally { // ロックを解放 unlock(lockKey); } }); } // 6.4 期限切れのデータを返す return r; }
public <R, ID> R queryWithMutex( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.Redisからキャッシュを取得 String shopJson = stringRedisTemplate.opsForValue().get(key); // 2.存在判定 if (StrUtil.isNotBlank(shopJson)) { // 3.存在、型へ変換して返す return JSONUtil.toBean(shopJson, type); } // キャッシュが空値かどうか if (shopJson != null) { // エラーを返す return null; }
// 4.キャッシュ再構築 // 4.1 排他ロックを取得 String lockKey = LOCK_SHOP_KEY + id; R r = null; try { boolean isLock = tryLock(lockKey); // 4.2 取得成功か判定 if (!isLock) { // 4.3 ロック取得失敗、待機して再試行 Thread.sleep(50); return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit); } // 4.4 ロック取得成功、DBを検索 r = dbFallback.apply(id); // 5.存在しなければ、空値をRedisへ if (r == null) { stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES); return null; } // 6.存在する場合、Redisへ書き込み this.set(key, r, time, unit); } catch (InterruptedException e) { throw new RuntimeException(e); }finally { // 7.ロックを解放 unlock(lockKey); } // 8.返す return r; }
private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); }
private void unlock(String key) { stringRedisTemplate.delete(key); }}クーポン秒殺
グローバルID
グローバルIDジェネレータは、分散システムでグローバルに一意なIDを生成するツールです。IDの安全性を高めるため、Redisの自動インクリメント値を直接使うのではなく、他の情報を組み合わせて作成します:
IDの構成要素:符号ビット:1bit、常に0
タイムスタンプ:31bit、秒単位で69年分使用可能
シーケンス番号:32bit、秒内のカウントで、毎秒2^32個の異なるIDを生成
@Componentpublic class RedisIdWorker { /** * 開始時間のタイムスタンプ */ private static final long BEGIN_TIMESTAMP = 1640995200L; /** * シーケンスのビット数 */ private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; }
public long nextId(String keyPrefix) { // 1. 時間スタンプを生成 LocalDateTime now = LocalDateTime.now(); long nowSecond = now.toEpochSecond(ZoneOffset.UTC); long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2. シーケンスを生成 // 2.1 日付を日付で取得(日付まで) String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); // 2.2 自動増分 long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3. 結合して返却 return timestamp << COUNT_BITS | count; }}秒殺券を追加:
@Override@Transactionalpublic void addSeckillVoucher(Voucher voucher) { // クーポンを保存 save(voucher); // 秒殺情報を保存 SeckillVoucher seckillVoucher = new SeckillVoucher(); seckillVoucher.setVoucherId(voucher.getId()); seckillVoucher.setStock(voucher.getStock()); seckillVoucher.setBeginTime(voucher.getBeginTime()); seckillVoucher.setEndTime(voucher.getEndTime()); seckillVoucherService.save(seckillVoucher); // 秒殺在庫をRedisに保存 stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());}秒殺注文
注文時には2点を判定します:
- 秒殺が開始しているか、終了しているか。開始前または終了済みなら注文不可
- 在庫が十分か。不足なら注文不可
@Overridepublic Result seckillVoucher(Long voucherId) { // 1.クーポンを検索 SeckillVoucher voucher = seckillVoucherService.getById(voucherId); // 2.秒殺が開始しているかを判定 if (voucher.getBeginTime().isAfter(LocalDateTime.now())) { // 開始前 return Result.fail("秒杀尚未开始!"); } // 3.秒杀が終っているかを判定 if (voucher.getEndTime().isBefore(LocalDateTime.now())) { // 終了 return Result.fail("秒杀已经结束!"); } // 4.在庫が十分か if (voucher.getStock() < 1) { // 在庫不足 return Result.fail("库存不足!"); } //5.在庫をデクリメント boolean success = seckillVoucherService.update() .setSql("stock= stock -1") .eq("voucher_id", voucherId).update(); if (!success) { // 在庫不足 return Result.fail("库存不足!"); } //6.注文を作成 VoucherOrder voucherOrder = new VoucherOrder(); // 6.1.注文ID long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); // 6.2.ユーザーID Long userId = UserHolder.getUser().getId(); voucherOrder.setUserId(userId); // 6.3.クーポンID voucherOrder.setVoucherId(voucherId); save(voucherOrder);
return Result.ok(orderId);}在庫過剰販売
過剰販売は典型的なマルチスレッド安全問題です。この問題に対する一般的な解決策はロックを使用することです。
悲観的ロック:
悲観的ロックはデータの直列実行を実現します。たとえば、synやlockなどが代表例です。公平ロック、非公平ロック、再入可能ロックなどに細分化できます。
楽観的ロック:
楽観的ロックにはバージョン番号があり、データ操作の際にバージョンを+1します。データをコミットする時に、前のバージョンと比較して1だけ増えていれば成功とします。この仕組みの核心は、操作中に他の人が変更していなければ安全とみなせる点です。CASなどの変形があります。
楽観的ロックの典型はCASで、CASを用いた無ロック機構のロックを実現します。var5は操作前に読み取ったメモリ値、while内のvar1+var2は推定値です。推定値がメモリ値と等しければ途中で他の人に変更されていないことを意味し、新しい値をメモリ値と置換します。
このdo-whileは、操作に失敗した場合に再試行するためのループです。
boolean success = seckillVoucherService.update() .setSql("stock= stock -1") .eq("voucher_id", voucherId) .gt("stock",0) .update(); //where id = ? and stock > 0一人一注文
基本ロジック:
// 5. 一人一注文ロジック// 5.1. ユーザーIDLong userId = UserHolder.getUser().getId();int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2. 存在判定if (count > 0) { // ユーザーはすでに購入済み return Result.fail("用户已经购买过一次!");}同時実行時の挙動:悲観ロック
// maven<dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId></dependency>
// Servicesynchronized(userId.toString().intern()) { // 代理オブジェクトを取得(トランザクション) IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId);}
@Transactionalpublic Result createVoucherOrder(Long voucherId) { // 5.一人一注文ロジック // 5.1. ユーザーID Long userId = UserHolder.getUser().getId();
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); // 5.2. 存在判定 if (count > 0) { // ユーザーはすでに購入済み return Result.fail("用户已经购买过一次!"); }
//5、在庫を減らす boolean success = seckillVoucherService.update() .setSql("stock= stock -1") .eq("voucher_id", voucherId) .gt("stock",0) .update(); //where id = ? and stock > 0 if (!success) { // 在庫不足 return Result.fail("库存不足!"); } //6. 注文を作成 VoucherOrder voucherOrder = new VoucherOrder(); // 6.1.注文ID long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); // 6.2.ユーザーID voucherOrder.setUserId(userId); // 6.3.クーポンID voucherOrder.setVoucherId(voucherId); save(voucherOrder); return Result.ok(orderId);
}分散ロック
クラスタ環境での同時実行の問題
現在、複数のTomcatをデプロイしているため、各Tomcatには独自のJVMがあります。サーバAのTomcat内には2つのスレッドがあり、同じコードを共有しているため、ロックオブジェクトは同じです。しかし、サーバBのTomcat内にも2つのスレッドがあり、ロックオブジェクトは同じように見えますが、実際には別のロックである可能性があります。したがって、Thread 3とThread 4は相互排他を実現しますが、Thread 1とThread 2とは排他できません。これがクラスタ環境での同期ロックが機能しない原因です。この問題を解決するには分散ロックを使用する必要があります。
分散ロック:分散システムまたはクラスタモードで複数プロセス間の可視性と排他性を満たすロック。
分散ロックの核心思想は、全員が同じロックを使うこと、同じロックを使えばスレッドをロックして並列実行を制御できるということです。
分散ロックの要件
可視性:複数のスレッドが同じ結果を見られること。ここでの可視性は並行プログラミングにおけるメモリ可視性を指すわけではなく、複数のプロセス間で変化を認識できることを意味します
排他性:分散ロックの最も基本的な条件で、プログラムの実行を直列化します
高可用性:プログラムが崩れにくく、常に高い可用性を保証します
高性能:ロックそのものがパフォーマンス低下を伴うため、分散ロックは高いロック性能と解放性能を求められます
安全性:プログラムには必須の要素です
一般的な分散ロックは3種類
Mysql:MySQL自体にロック機構はありますが、性能が一般的なため、分散ロックとして使われることは少ないです
Redis:Redisを分散ロックとして使うのが非常に一般的です。現在の企業向け開発では、ほとんどRedisやZookeeperを分散ロックとして使用します。setnxを利用します。キーの挿入に成功すればロックを得たことになり、他の人が挿入に失敗すればロックを得られません。これを利用して分散ロックを実現します
Zookeeper:Zookeeperはエンタープライズ級の分散ロック実装として良い選択肢のひとつです。ノードの一意性と有序性を利用して排他を実現します
分散ロックの実装思想
- ロック取得:
- 排他性:ただ1つのスレッドだけがロックを取得できるようにする
- 非ブロッキング:試行は一度だけ行い、成功ならtrue、失敗ならfalse
- ロック解放:
- 手動解放
- タイムアウト解放:ロック取得時にタイムアウトを設定する
@Overridepublic boolean tryLock(long timeoutSec) { // 取得中のスレッドIDを取得 Long threadId = Thread.currentThread().getId(); // ロックを取得 Boolean success = stringRedisTemplate.opsForValue() .setIfAbsent(KEY_PREFIX + name, threadId + "", timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(success);}
@Overridepublic void unlock() { // ロックを削除 stringRedisTemplate.delete(KEY_PREFIX + name);}
// ビジネスコード// ロックオブジェクトを作成(新しいコード)SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);// ロックを取得boolean isLock = lock.tryLock(1200);// ロック取得に失敗if (!isLock) { return Result.fail("不允许重复下单");}try { // プロキシオブジェクトを取得(トランザクション) IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId);} finally { // ロックを解放 lock.unlock();}分散ロックの誤削除
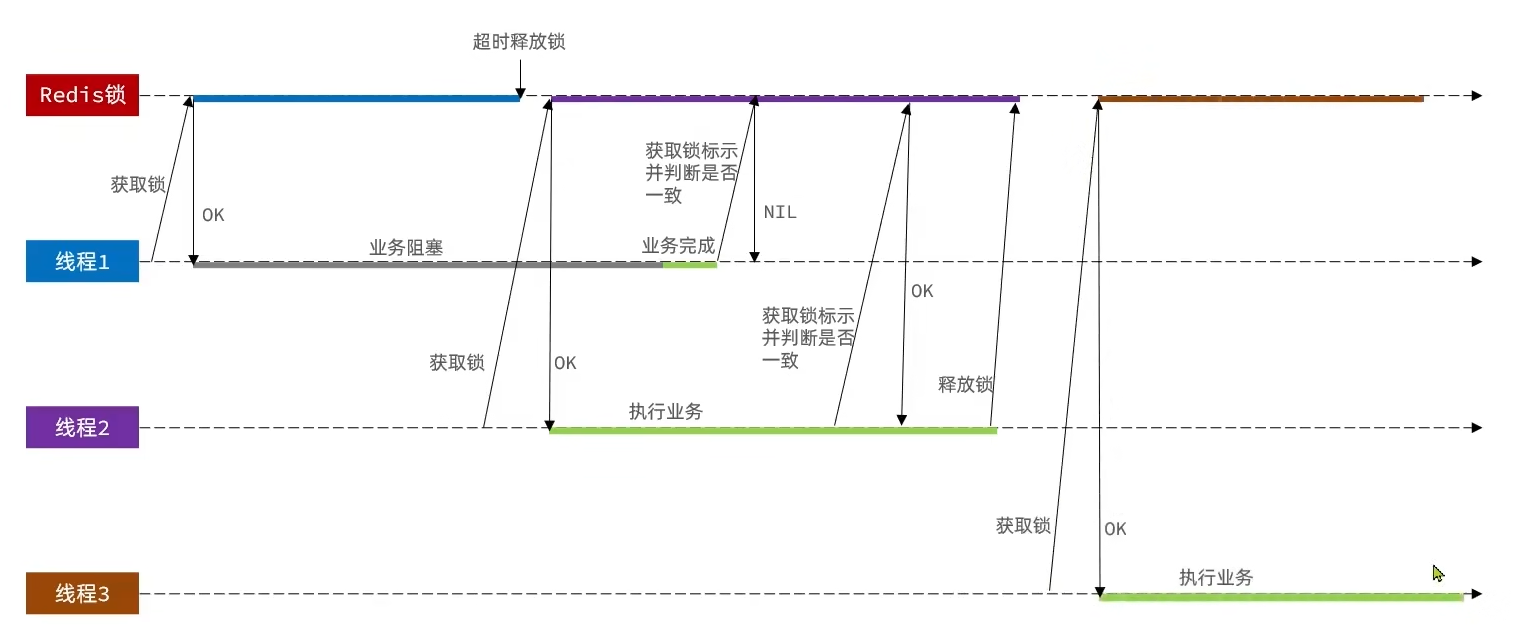
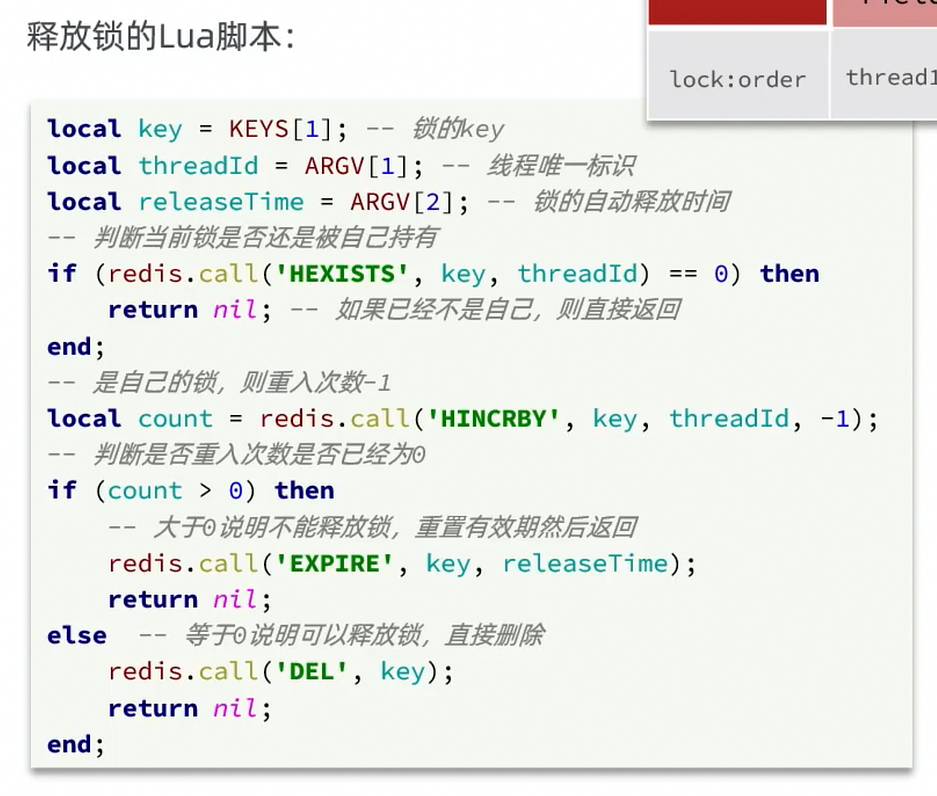
解決策:ロックを格納する際には自分のスレッド識別子を格納し、ロックを削除する際には現在のロックの識別子が自分のものかを判定します。自分のものであれば削除し、そうでなければ削除しません。
private static final String ID_PREFIX = UUID.randomUUID().toString() + "-";@Overridepublic boolean tryLock(long timeoutSec) { // 取得中のスレッド識別子を取得 String threadId = ID_PREFIX + Thread.currentThread().getId(); // ロックを取得 Boolean success = stringRedisTemplate.opsForValue() .setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(success);}
@Overridepublic void unlock() { // 取得中のスレッド識別子を取得 String threadId = ID_PREFIX + Thread.currentThread().getId(); String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// ロックを削除 if(threadId.equals(id)){ stringRedisTemplate.delete(KEY_PREFIX + name); }}分散ロックの原子性の問題
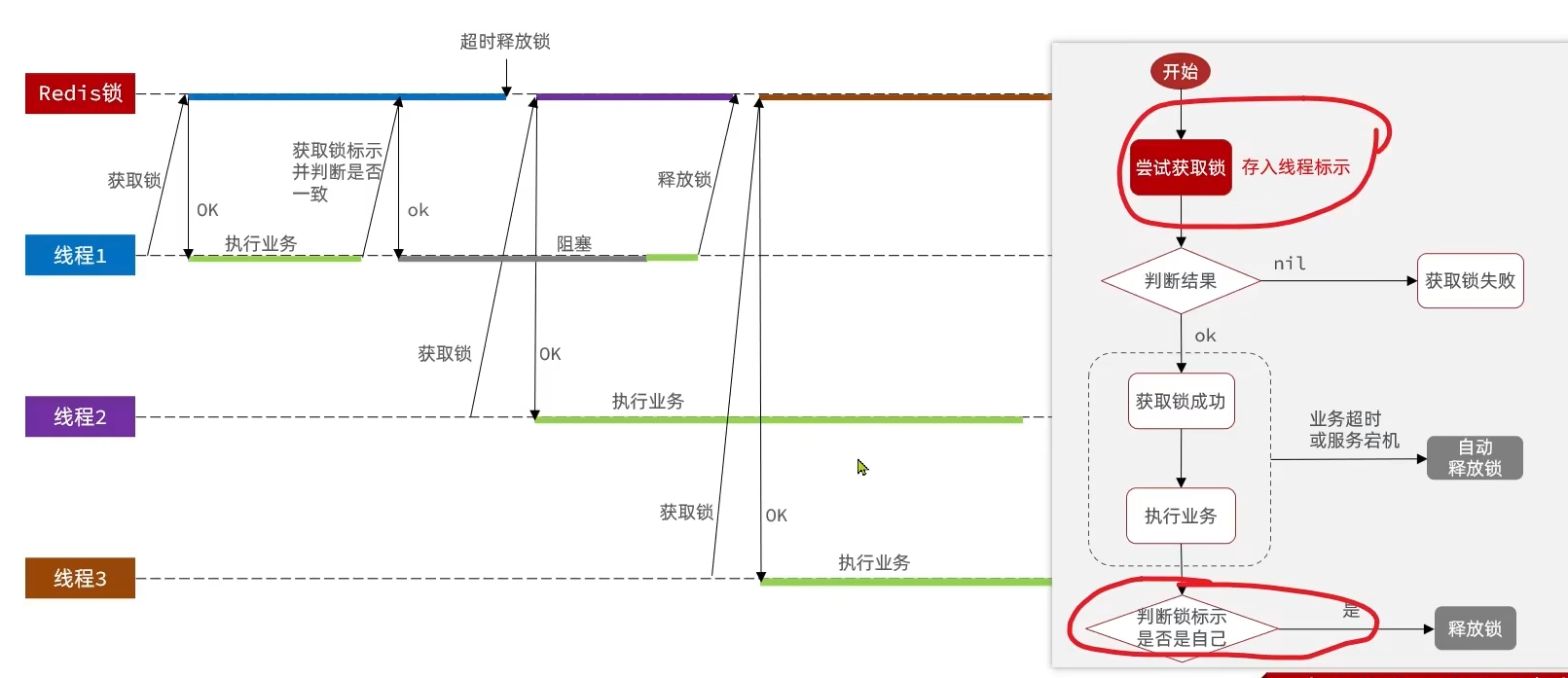
解決:Luaスクリプトを1つのスクリプトとして複数のRedisコマンドを書き込む
- ロックの識別子を取得
- 指定された識別子(現在のスレッド識別子)と一致するか判定
- 一致すればロックを解放(削除)
- 一致しなければ何も行わない
-- ここで KEYS[1] はロックのキー、ARGV[1] は現在のスレッド識別子-- ロックの識別子を取得し、現在の識別子と一致するか判定if (redis.call('GET', KEYS[1]) == ARGV[1]) then -- 一致、ロックを削除 return redis.call('DEL', KEYS[1])end-- 一致しなければ、何も返さないreturn 0private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; static { UNLOCK_SCRIPT = new DefaultRedisScript<>(); UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua")); UNLOCK_SCRIPT.setResultType(Long.class); }
public void unlock() { // Luaスクリプトを呼び出す stringRedisTemplate.execute( UNLOCK_SCRIPT, Collections.singletonList(KEY_PREFIX + name), ID_PREFIX + Thread.currentThread().getId());}分散ロック Redisson
setnxを用いた分散ロックの課題:
再入:ロックを取得したスレッドは、同じロックのコードブロックへ再び入ることができます。再入可能なロックはデッドロックを防ぐ意味があります。
再試行不可:現在の分散ロックは一度だけ試行する仕様です。合理的なケースとして、スレッドがロック取得に失敗した場合、再度ロックを取得できるべきです。
- タイムアウト解放: ロック取得時に有効期限を設定しているため、デッドロックを防げますが、カードタイムが長すぎる場合、ロックは実際には保持されていない可能性があり、安全性の問題が生じます。
マスター/スレーブ整合性: Redisがマスター/スレーブのクラスターを提供している場合、クラスターへデータを書き込むと、マスターは非同期でスレーブへデータを同期します。同期される前にマスターがダウンすると、死鎖の問題が発生する可能性があります。
RedissonはRedisを利用したJavaのメモリ内データグリッド(In-Memory Data Grid)であり、分散ロックの他にも様々な分散サービスを提供します。
redissonの使用
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version></dependency>@Configurationpublic class RedissonConfig { @Bean public RedissonClient redissonClient(){ // 設定 Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); // RedissonClientオブジェクトを作成 return Redisson.create(config); }}
//ロックオブジェクトを作成RLock lock = redissonClient.getLock("lock:order:" + userId);//ロックを取得boolean isLock = lock.tryLock();
//ロック取得に失敗if (!isLock) { return Result.fail("不允许重复下单");}try { //代理オブジェクトを取得(トランザクション) IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId);} finally { //ロックを解放 lock.unlock();}redissonの再入可能ロック
ハッシュテーブル構造を用いてロックのスレッドと再入回数を管理します
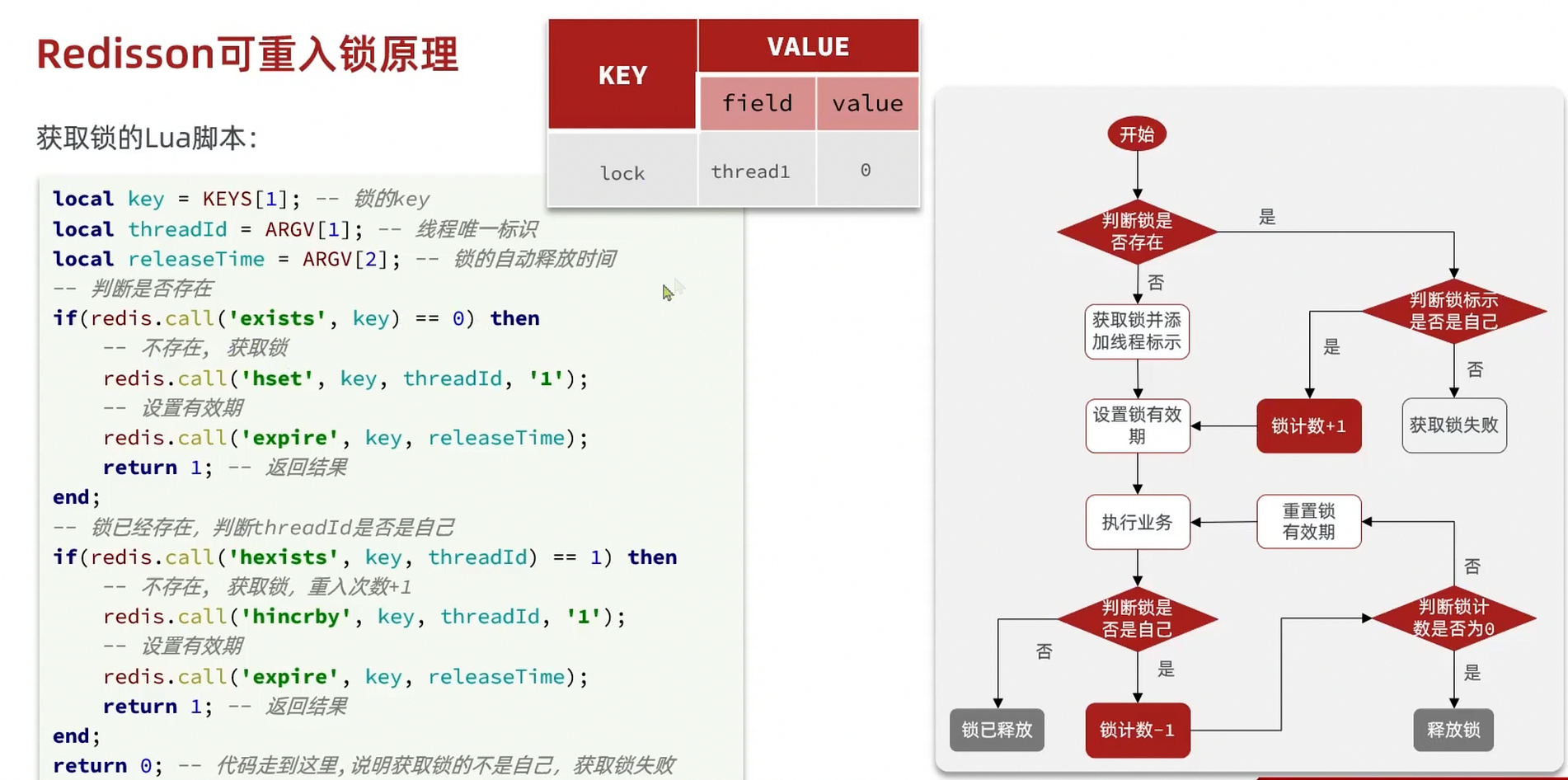
redissonのロック再試行とWatchDogメカニズム
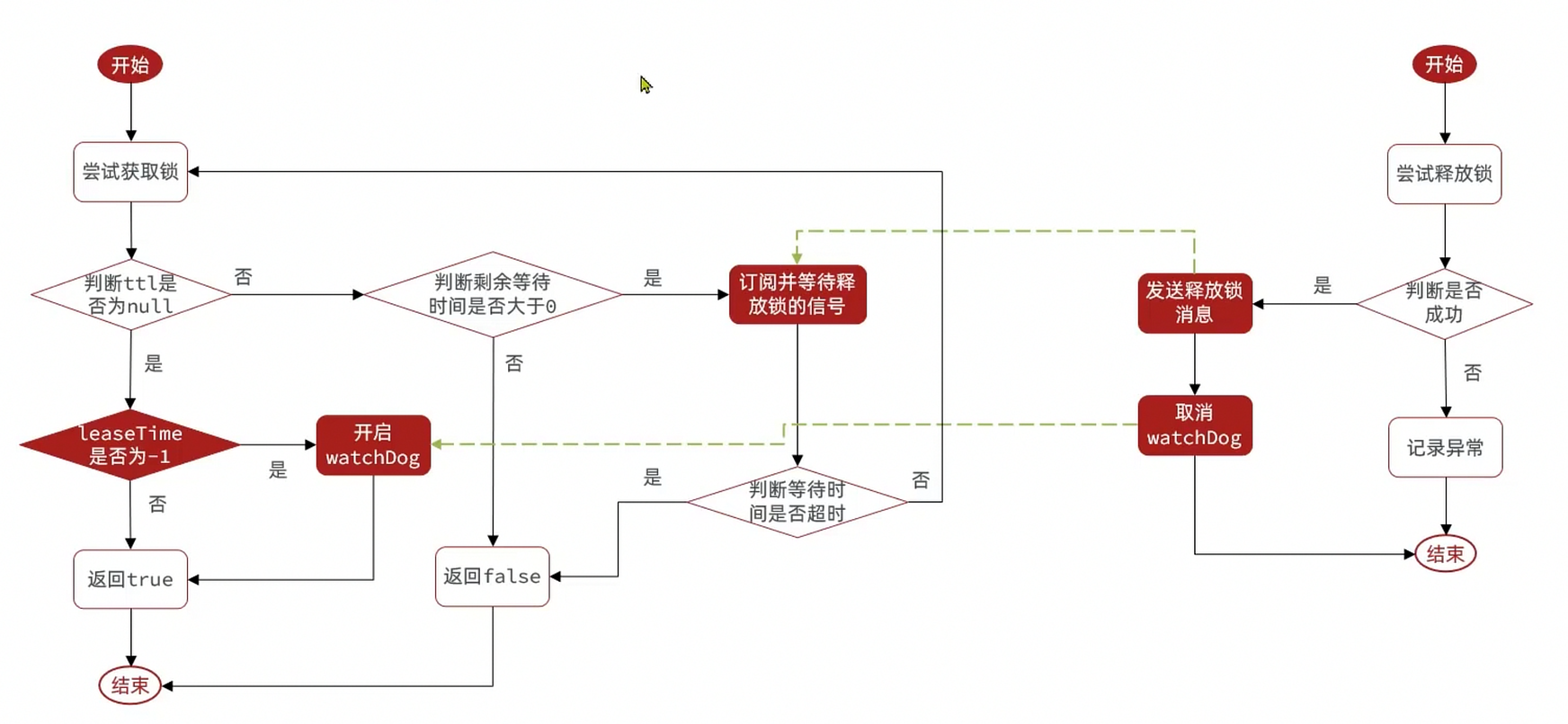
- 再試行:シグナルとPubSub機能を利用して待機・ウェイクアップを実現し、ロック取得失敗時のリトライ機能
- タイムアウト更新:WatchDogを利用して一定時間おきに(releaseTime/3)、タイムアウトを更新
redissonでの主/従整合性解決 - MutiLock
この問題を解決するため、redissonはMutiLockロックを提案します。これを使えば主従は不要になり、各ノードは同等の立場を持ちます。このロックのロック処理は全てのマスタースレーブノードへ書き込む必要があり、全てのサーバーへの書き込みが成功した時点でロック成功とみなします。もしあるノードが落ちた場合でも、他のノードがロックを取得できなければロックは成功とはみなされず、ロックの信頼性を保証します。
複数のロックを設定すると、Redissonはこれらを1つの集合へ追加し、whileループでロック取得を継続します。ただし、総ロック時間は必要なロック数×1500msです。ロックが3つある場合は4500msとなります。すべてのロックがこの期間内に取得できればロック成功、それ以外は再試行します。
秒殺の最適化
非同期秒殺
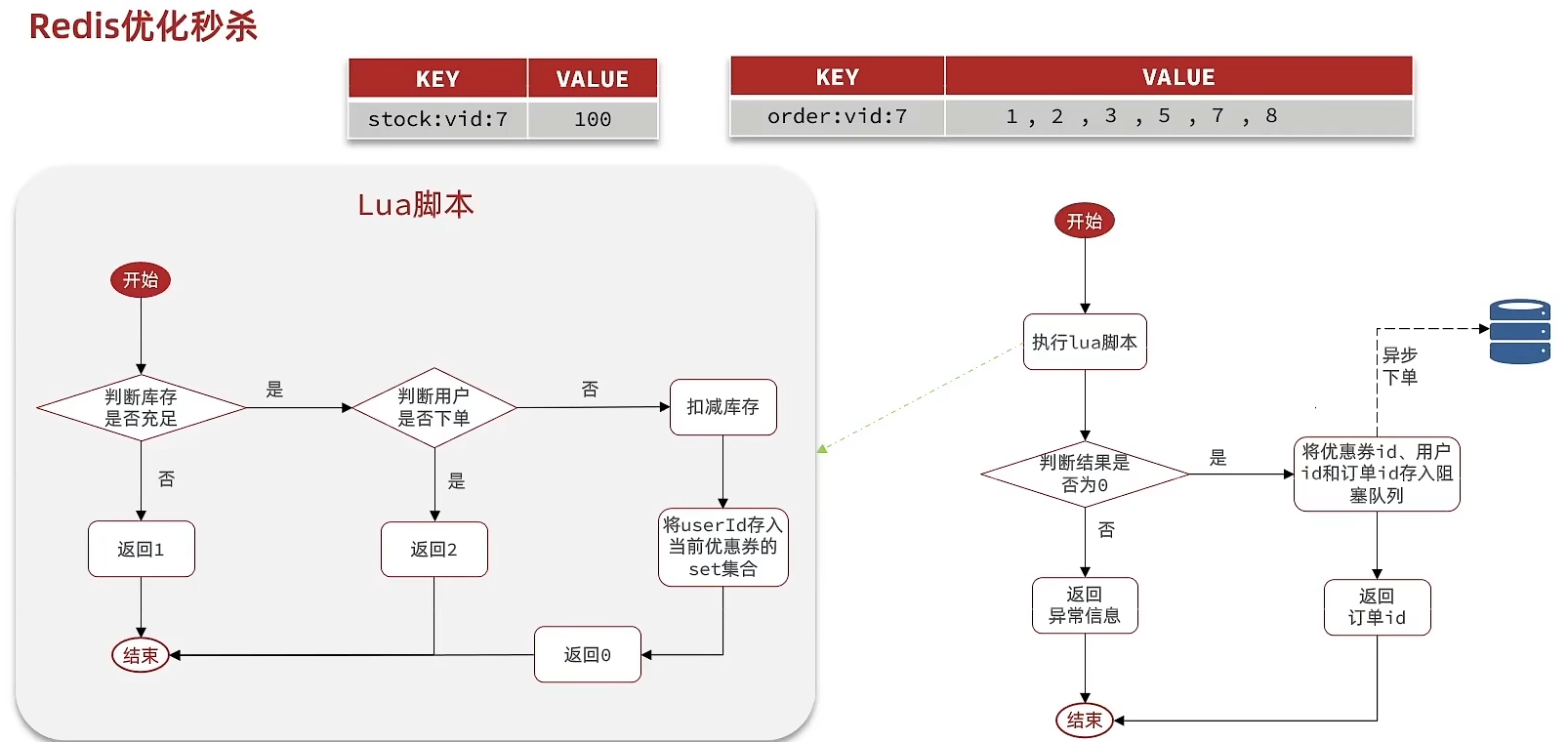
要件:
- 新しい秒殺クーポンを追加する際、クーポン情報をRedisに保存
- Luaスクリプトを基に、秒殺在庫と1人1注文を判定し、ユーザーの購入可否を決定
- 購入成功の場合、クーポンIDとユーザーIDをパッケージ化してブロックキューへ格納
- スレッドタスクを開始して、ブロックキューから情報を継続的に取得し、非同期で注文を実現
Luaスクリプトによる判定:
-- 1.パラメータリスト-- 1.1. クーポンIDlocal voucherId = ARGV[1]-- 1.2. ユーザーIDlocal userId = ARGV[2]-- 1.3. 注文IDlocal orderId = ARGV[3]
-- 2.データキー-- 2.1. 在庫キーlocal stockKey = 'seckill:stock:' .. voucherId-- 2.2. 注文キーlocal orderKey = 'seckill:order:' .. voucherId
-- 3.スクリプトのビジネス-- 3.1. 在庫が充足しているかif(tonumber(redis.call('get', stockKey)) <= 0) then -- 3.2. 在庫不足、1を返す return 1end-- 3.2. ユーザーが既に注文しているかif(redis.call('sismember', orderKey, userId) == 1) then -- 3.3. 存在する、重複注文とみなし、2を返す return 2end-- 3.4. 在庫を減らすredis.call('incrby', stockKey, -1)-- 3.5. 注文(ユーザーを保存)sadd orderKey userIdredis.call('sadd', orderKey, userId)-- 3.6. メッセージをキューへ送信、XADD stream.orders * k1 v1 k2 v2 ...redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)return 0阻塞キューによる実装:
// 非同期処理用スレッドプールprivate static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
// クラス初期化後に実行、クラスが初期化されたら、いつでも実行され得る@PostConstructprivate void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());}// スレッドプールで実行するタスク// 初期化完了後、キューから情報を取得する private class VoucherOrderHandler implements Runnable{
@Override public void run() { while (true){ try { // 1.キューの注文情報を取得 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 > List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read( Consumer.from("g1", "c1"), StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)), StreamOffset.create("stream.orders", ReadOffset.lastConsumed()) ); // 2.注文情報が空かを判定 if (list == null || list.isEmpty()) { // nullの場合、メッセージが無いとみなし、次のループへ continue; } // データを解析 MapRecord<String, Object, Object> record = list.get(0); Map<Object, Object> value = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true); // 3.注文を作成 createVoucherOrder(voucherOrder); // 4.メッセージの確認 XACK stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId()); } catch (Exception e) { log.error("处理订单异常", e); // 異常メッセージを処理 handlePendingList(); } } }
private void handlePendingList() { while (true) { try { // 1. pending-list の情報を取得 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 0 List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read( Consumer.from("g1", "c1"), StreamReadOptions.empty().count(1), StreamOffset.create("stream.orders", ReadOffset.from("0")) ); // 2.注文情報が空かを判定 if (list == null || list.isEmpty()) { // nullの場合、異常データが無いので終了 break; } // データを解析 MapRecord<String, Object, Object> record = list.get(0); Map<Object, Object> value = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true); // 3.注文を作成 createVoucherOrder(voucherOrder); // 4.メッセージの確認 XACK stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId()); } catch (Exception e) { log.error("处理pendding订单异常", e); try{ Thread.sleep(20); }catch(Exception e){ e.printStackTrace(); } } } }}ダントン探店
探店ノートを公開
探店ノートはレビューサイトの評価に似ており、しばしば画像と文章の組み合わせです。対応するテーブルは2つあります: tb_blog:探店ノートのテーブル。ノートのタイトル、本文、画像などを含む tb_blog_comments:探店ノートに対する他ユーザーの評価
- アップロード、送信、閲覧:
@Slf4j@RestController@RequestMapping("upload")public class UploadController {
@PostMapping("blog") public Result uploadImage(@RequestParam("file") MultipartFile image) { try { // 元のファイル名を取得 String originalFilename = image.getOriginalFilename(); // 新しいファイル名を生成 String fileName = createNewFileName(originalFilename); // ファイルを保存 image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName)); // 結果を返す log.debug("ファイル上传成功,{}", fileName); return Result.ok(fileName); } catch (IOException e) { throw new RuntimeException("ファイル上传失败", e); } }}
@PostMappingpublic Result saveBlog(@RequestBody Blog blog) { // ログインユーザーを取得 UserDTO user = UserHolder.getUser(); blog.setUpdateTime(user.getId()); // 探店ノートを保存 blogService.saveBlog(blog); // IDを返す return Result.ok(blog.getId());}
@Overridepublic Result queryBlogById(Long id) { // 1.ブログを検索 Blog blog = getById(id); if (blog == null) { return Result.fail("笔记不存在!"); } // 2.ブログに関連するユーザーを検索 queryBlogUser(blog);
return Result.ok(blog);}-
いいね
要件:
- 同一ユーザーは1回だけいいねでき、再度クリックするといいねを取り消します
- 現在のユーザーがすでにいいねしている場合、いいねボタンはハイライト表示されます(フロントエンドは既に実装済み。BlogクラスのisLike属性で判断)
実装手順:
- BlogクラスにisLikeフィールドを追加し、現在のユーザーがいいねしたかを示す
- いいね機能を変更し、RedisのSet集合を利用して「いいね済みかどうか」を判定。未いいねなら+1、既にいいねしている場合は-1
- idでBlogを検索する処理を変更し、現在のログインユーザーがいいね済みかを判定してisLikeへ設定
- Blogをページングして検索する処理を変更し、現在のログインユーザーがいいね済みかを判定してisLikeへ設定
private void isBlogLiked(Blog blog) { // 1.ログインユーザーを取得 Long userId = UserHolder.getUser().getId(); // 2.現在のログインユーザーがいいね済みかを判断 String key = BLOG_LIKED_KEY + blog.getId(); Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); blog.setIsLike(BooleanUtil.isTrue(isMember));}
@Overridepublic Result likeBlog(Long id) { // 1.ユーザーを取得 Long userId = UserHolder.getUser().getId(); // 2.現在のユーザーがいいね済みかを判定 String key = BLOG_LIKED_KEY + id; Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); if(BooleanUtil.isFalse(isMember)){ // 3.未いいねなら、いいねを追加 // 3.1 データベースのいいね数を+1 boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update(); // 3.2 RedisのSetにユーザーを追加 if(isSuccess){ stringRedisTemplate.opsForSet().add(key,userId.toString()); } }else { // 4.すでにいいね済み、取り消し // 4.1 DBのいいね数を-1 boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update(); // 4.2 RedisのSet集合からユーザーを削除 if (isSuccess) { stringRedisTemplate.opsForSet().remove(key, userId.toString()); } } return Result.ok();}- いいねランキング
setをsortedSetへ変更:set → zset
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());stringRedisTemplate.opsForZSet().remove(key, userId.toString());
// いいねのトップ5表示@Overridepublic Result queryBlogLikes(Long id) { String key = BLOG_LIKED_KEY + id; // 1.トップ5のいいねユーザーを取得 Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4); if (top5 == null || top5.isEmpty()) { return Result.ok(Collections.emptyList()); } // 2.ユーザーIDを抽出 List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList()); String idStr = StrUtil.join(",", ids); // 3.ユーザーを検索 List<UserDTO> userDTOS = userService.query() .in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list() .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); // 4.返却 return Result.ok(userDTOS);}友達フォロー
フォローとアンフォロー
要件:このテーブル構造に基づき、2つのエンドポイントを実装します。
- フォローとフォロー解除のエンドポイント
- フォローしているかを判定するエンドポイント
FollowController
// フォロー@PutMapping("/{id}/{isFollow}")public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) { return followService.follow(followUserId, isFollow);}// アンフォロー@GetMapping("/or/not/{id}")public Result isFollow(@PathVariable("id") Long followUserId) { return followService.isFollow(followUserId);}FollowService
取消关注service@Overridepublic Result isFollow(Long followUserId) { // 1.ログインユーザーを取得 Long userId = UserHolder.getUser().getId(); // 2.フォローしているかを検索 select count(*) from tb_follow where user_id = ? and follow_user_id = ? Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count(); // 3.判定 return Result.ok(count > 0); }
关注service @Override public Result follow(Long followUserId, Boolean isFollow) { // 1.ログインユーザーを取得 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 1.フォローかフォロー解除かを判定 if (isFollow) { // 2.フォロー、データを追加 Follow follow = new Follow(); follow.setUserId(userId); follow.setFollowUserId(followUserId); boolean isSuccess = save(follow);
} else { // 3.フォロー解除、削除 remove(new QueryWrapper<Follow>() .eq("user_id", userId).eq("follow_user_id", followUserId));
} return Result.ok(); }共同フォロー(共通フォロー)
setの共通要素
FollowServiceImpl
@Overridepublic Result follow(Long followUserId, Boolean isFollow) { // 1.ログインユーザーを取得 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 1.フォローかフォロー解除かを判定 if (isFollow) { // 2.フォロー、データを追加 Follow follow = new Follow(); follow.setUserId(userId); follow.setFollowUserId(followUserId); boolean isSuccess = save(follow); if (isSuccess) { // フォローしたユーザーIDをRedisのSet集合へ追加 sadd userId followerUserId stringRedisTemplate.opsForSet().add(key, followUserId.toString()); } } else { // 3.フォロー解除、削除 boolean isSuccess = remove(new QueryWrapper<Follow>() .eq("user_id", userId).eq("follow_user_id", followUserId)); if (isSuccess) { // Redisの集合からフォローしたユーザーIDを削除 stringRedisTemplate.opsForSet().remove(key, followUserId.toString()); } } return Result.ok();}具体のフォローコード:
FollowServiceImpl
@Overridepublic Result followCommons(Long id) { // 1.現在のユーザーを取得 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 2.交差集合を求める String key2 = "follows:" + id; Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2); if (intersect == null || intersect.isEmpty()) { // 交差なし return Result.ok(Collections.emptyList()); } // 3.交差集合のIDを解析 List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList()); // 4.ユーザーを検索 List<UserDTO> users = userService.listByIds(ids) .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(users);}Feedフロー
私たちが特定のユーザーをフォローした後、そのユーザーが投稿をすると、これらのデータをフォロワーへプッシュする必要があります。この機能はFeedフローと呼ばれ、フォロー通知とも呼ばれます。ユーザーへ没入型の体験を継続的に提供するため、無限スクロールで新しい情報を取得します。
Feedフローには、TimelineとSmart排序という2つの一般的な模式があります:
- Timeline:内容のフィルタを行わず、公開時刻で単純にソートします。友人・フォロー対象に多く使用されます。
- 利点:情報が全体的、欠損がない。実装が比較的簡単
- 欠点:情報ノイズが多く、ユーザーの関心が薄い可能性、データ取得の効率が低い
- Smart排序:アルゴリズムで違反・関心の薄い内容を除外します。ユーザーが興味を持つ情報をプッシュして、ユーザーの関心を引きつけます
- 利点:ユーザーの関心が高い情報を提供し、粘着性が高い
- 欠点:アルゴリズムが正確でない場合、逆効果になる可能性
今回、友人の操作に対してはTimeline方式を採用します。フォローしているユーザーの情報を取得し、時系列で並べるだけです。
Timelineモードの実現方法は3つあります:
-
プルモード(Pullの拡散)
- 利点:スペースを節約、読み取り時に重複読み取りがなく、読み終えたら受信箱をクリアできる
- 欠点:遅延が大きい。ユーザーがデータを読む時にフォローしている人のデータを読みに行く。フォロー人数が多いと大量のデータを取得することになり、サーバーへの負荷が大きい
-
プッシュモード(Pushの拡散)
- 利点:時效性が高い。再取得の必要が少ない
- 欠点:メモリの負荷が大きい。大きなインフルエンサーが情報を流す場合、多くのファンへ分データを書き込むことになる
-
プッシュ・プル併用:読み書きの両方の長所を活用
- ファン通知
要件:
- 新規の探店ノートを追加する際、ノートをDBへ保存すると同時にファンの受信箱へプッシュします
- 受信箱はタイムスタンプでソート可能で、Redisのデータ構造を使って実現します
- 受信箱データを照会する際にページネーションを実装します
要旨:探店ノートを保存した後、現在のノートのファンを取得し、そのデータをファンのRedisへプッシュします。
@Overridepublic Result saveBlog(Blog blog) { // 1.ログインユーザーを取得 UserDTO user = UserHolder.getUser(); blog.setUserId(user.getId()); // 2.探店ノートを保存 boolean isSuccess = save(blog); if(!isSuccess){ return Result.fail("新增笔记失败!"); } // 3.作者の全ファンを取得 select * from tb_follow where follow_user_id = ? List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list(); // 4.ノートIDを全ファンへプッシュ for (Follow follow : follows) { // 4.1.ファンIDを取得 Long userId = follow.getUserId(); // 4.2.プッシュ String key = FEED_KEY + userId; stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis()); } // 5.返却 return Result.ok(blog.getId());}- 受信箱のページネーション検索
- 使用するZREVRANGEBYSCORE key Max Min LIMIT offset count
@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) { // 1.現在のユーザーを取得 Long userId = UserHolder.getUser().getId(); // 2.受信箱を検索、距離でソート、ページング String key = FEED_KEY + userId; Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet() .reverseRangeByScoreWithScores(key, 0, max, offset, 2); // 3.空判定 if (typedTuples == null || typedTuples.isEmpty()) { return Result.ok(); } // 4.データを解析:blogId、minTime(タイムスタンプ)、offset List<Long> ids = new ArrayList<>(typedTuples.size()); long minTime = 0; // 2 int os = 1; // 2 for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2 // 4.1. IDを取得 ids.add(Long.valueOf(tuple.getValue())); // 4.3. 距離を取得(タイムスタンプ) long time = tuple.getScore().longValue(); if(time == minTime){ os++; }else{ minTime = time; os = 1; } } os = minTime != max ? os : os + offset; // 5. IDを用いてBlogを検索 String idStr = StrUtil.join(",", ids); List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); for (Blog blog : blogs) { // 5.1. ブログ関連ユーザーを検索 queryBlogUser(blog); // 5.2. ブログがいいねされたかを確認 isBlogLiked(blog); }
// 6. ラップして返却 ScrollResult r = new ScrollResult(); r.setList(blogs); r.setOffset(os); r.setMinTime(minTime);
return Result.ok(r);}近くの商店 GEO
GEOはGeolocationの略で、地理座標を表します。Redisは3.2以降GEOサポートを追加し、経度・緯度・メンバーを格納し、緯度経度に基づく検索を支援します。一般的なコマンドは以下のとおりです:
- GEOADD:地理空間情報を追加。経度、緯度、メンバー
- GEODIST:指定した2点間の距離を計算して返す
- GEOHASH:指定メンバーの座標をハッシュ文字列形式へ変換して返す
- GEOPOS:指定メンバーの座標を返す
- GEORADIUS:円の中心と半径を指定して、その円内に含まれる全メンバーを距離の順に返す。6.以降は廃止
- GEOSEARCH:指定された範囲内でメンバーを検索し、指定点との距離でソートして返す。範囲は円形または長方形。6.2 新機能
- GEOSEARCHSTORE:GEOSEARCH機能と同様だが、結果を指定のキーに格納できる。 6.2 新機能
データ導入
@Testvoid loadShopData() { // 1.店舗情報を検索 List<Shop> list = shopService.list(); // 2.タイプ別に店舗をグループ化。typeIdが同じものを1つの集合へ Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId)); // 3.バッチでRedisへ書き込み for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) { // 3.1.タイプIDを取得 Long typeId = entry.getKey(); String key = SHOP_GEO_KEY + typeId; // 3.2.同タイプの店舗集合を取得 List<Shop> value = entry.getValue(); List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size()); // 3.3. Redis GEOADD key 経度 纬度 member を書き込み for (Shop shop : value) { // stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getY()), shop.getId().toString()); locations.add(new RedisGeoCommands.GeoLocation<>( shop.getId().toString(), new Point(shop.getX(), shop.getY()) )); } stringRedisTemplate.opsForGeo().add(key, locations); }}実装:
- pomの導入
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <artifactId>spring-data-redis</artifactId> <groupId>org.springframework.data</groupId> </exclusion> <exclusion> <artifactId>lettuce-core</artifactId> <groupId>io.lettuce</groupId> </exclusions> </exclusions></dependency><dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>2.6.2</version></dependency><dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.1.6.RELEASE</version></dependency>- 実装機能(検索 | ページング | ソート)
@Overridepublic Result queryShopByType(Integer typeId, Integer current, Double x, Double y) { // 1.座標ベース検索が必要か判断 if (x == null || y == null) { // 座標検索なし、DBで検索 Page<Shop> page = query() .eq("type_id", typeId) .page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE)); // データを返す return Result.ok(page.getRecords()); }
// 2.ページングパラメータを計算 int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE; int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3.Redisを検索、距離でソート、ページング。結果は shopId、distance String key = SHOP_GEO_KEY + typeId; GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE .search( key, GeoReference.fromCoordinate(x, y), new Distance(5000), RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end) ); // 4. idを解析 if (results == null) { return Result.ok(Collections.emptyList()); } List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent(); if (list.size() <= from) { // 次のページはない return Result.ok(Collections.emptyList()); } // 4.1. from ~ endを取得 List<Long> ids = new ArrayList<>(list.size()); Map<String, Distance> distanceMap = new HashMap<>(list.size()); list.stream().skip(from).forEach(result -> { // 4.2. 店舗IDを取得 String shopIdStr = result.getContent().getName(); ids.add(Long.valueOf(shopIdStr)); // 4.3. 距離を取得 Distance distance = result.getDistance(); distanceMap.put(shopIdStr, distance); }); // 5. idからShopを検索 String idStr = StrUtil.join(",", ids); List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); for (Shop shop : shops) { shop.setDistance(distanceMap.get(shop.getId().toString()).getValue()); } // 6.返却 return Result.ok(shops);}ユーザーのサインイン
BitMapの操作コマンドには以下があります:
- SETBIT:指定位置(offset)に0または1を格納
- GETBIT:指定位置のビット値を取得
- BITCOUNT:Bitmap内の1のビット数をカウント
- BITFIELD:Bitmapの特定位置の値を操作(照会・変更・自動増分)
- BITFIELD_RO:Bitmapのビット配列を10進で返す
- BITOP:複数のBitmapのビット演算(AND、OR、XOR)
- BITPOS:ビット配列の指定範囲で1または0が初めて現れる位置を検索
サインイン:
@Overridepublic Result sign() { // 1.現在のログインユーザーを取得 Long userId = UserHolder.getUser().getId(); // 2.日付を取得 LocalDateTime now = LocalDateTime.now(); // 3.キーを組み立て String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM")); String key = USER_SIGN_KEY + userId + keySuffix; // 4.本日が今月の何日目かを取得 int dayOfMonth = now.getDayOfMonth(); // 5.RedisへSETBIT、オフセットは dayOfMonth - 1 stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true); return Result.ok();}UV統計
- UV:Unique Visitor(ユニーク訪問者)。同一人物が1日内に何度訪問しても1回としてカウントします。
- PV:Page View。サイトのページを閲覧するごとに1回としてカウントします。
一般的にはUVはPVよりも大きくなるケースが多いです。従って、同じサイトの訪問量を評価する際には、これら2つの値を参考値として扱います。
HyperLogLog(HLL)は、Loglogアルゴリズムを派生させた確率的アルゴリズムで、非常に大規模な集合の基数を推定します。RedisのHLLはstring構造に基づいており、単一のHLLはメモリが常に16KB未満、メモリ使用量が低いです。その代償として、測定結果は確率的で、誤差は0.81%未満の可能性があります。
@Testvoid testHLL() { String[] users = new String[1000]; int idx = 0; for(int i= 1;i<=100000;i++){ users[idx++] = "user_" + i; if(i % 1000 == 0){ idx = 0; stringRedisTemplate.opsForHyperLogLog().add("hll1",users); } } Long size = stringRedisTemplate.opsForHyperLogLog().size("hll1"); System.out.println("size = "+ size);}この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります