


















ジグザグ行列
マイクロソフトの面接問題
問題の説明
入力は2つの整数 および を受け取り、 行 列の行列を出力する。数字 から までをジグザグ蛇行の形で行列に埋める。
具体的な行列の形はサンプルを参照してください。
入力形式
入力は1行で、2つの整数 と を含む。
出力形式
条件を満たす行列を出力する。
行列は 行で、各行には 個の空白で区切られた整数が含まれる。
データ範囲
解法
シミュレーション法:
#include <iostream>#include <cstring>#include <algorithm>using namespace std;const int N = 110;int n,m,a[N][N];int main(){ cin>>n>>m; int l = 0,r = m-1, t = 0,d = n-1,cnt=1; while(l<=r || t <= d){ for(int i=l;i<=r && t<=d;i++) a[t][i] = cnt++;t++; for(int i=t;i<=d && l<=r;i++) a[i][r] = cnt++;r--; for(int i=r;i>=l && t<=d;i--) a[d][i] = cnt++;d--; for(int i=d;i>=t && l<=r;i--) a[i][l] = cnt++;l++; } for(int i=0;i<n;i++) for(int j=0;j<m;j++) cout<<a[i][j]<<" \\n"[j==m-1];
return 0;}ボトムアップのシミュレーション:
#include <iostream>#include <cstring>#include <algorithm>using namespace std;const int N = 110;int n,m,a[N][N],dx[4]={0,1,0,-1},dy[4]={1,0,-1,0};int main(){ cin>>n>>m;int x=0,y=0; for(int i=1,u=0;i<=n*m;i++){ a[x][y] = i; x += dx[u];y += dy[u]; if(a[x][y] || x<0 || y<0 || x>=n || y>=m) x-=dx[u],y-=dy[u],u = (u+1)%4, x += dx[u],y += dy[u]; }
for(int i=0;i<n;i++) for(int j=0;j<m;j++) cout<<a[i][j]<<" \\n"[j==m-1]; return 0;}単方向リストのクイックソート
Megviiの面接問題
問題の説明
与えられた単方向リストを、クイックソートアルゴリズムでソートしてください。
要求:平均時間計算量は 、追加の空間計算量は 。
考察問題:リストの各ノードの val 値を変更せずに、構造だけを変える方法は?
データ範囲
リスト中の全ての数は 範囲、リストの長さは 。
本問のデータは完全にランダムに生成。
解法
通常のクイックソートとほぼ同様の考え方で、リストをある val で、小なり・等しい・大きいの3段に分け、前後の2段を再帰的にソートしてから、並べ替えた3段を前から後ろへ結合して完成。
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */class Solution {public: ListNode* quickSortList(ListNode* head) { if(!head || !head->next) return head;
auto left = new ListNode(-1),mid=new ListNode(-1),right=new ListNode(-1), ltail = left,mtail = mid,rtail = right; int val = head->val;
for(auto p=head;p;p = p->next){ if(p->val < val) ltail = ltail->next = p; else if(p->val == val) mtail = mtail->next = p; else rtail = rtail->next = p; }
ltail->next = mtail->next = rtail->next = NULL; left->next = quickSortList(left->next); right->next = quickSortList(right->next);
get_tail(left)->next = mid->next; get_tail(left)->next = right->next;
auto p = left->next; delete left;delete mid;delete right; return p; }
ListNode* get_tail(ListNode* head) { while (head->next) head = head->next; return head; }};峰値の探索
峰値は、値が左右の隣接値より厳密に大きい要素を指します。
整数配列 nums が与えられ、峰値要素を見つけてそのインデックスを返してください。配列には複数の峰値が含まれることがあります。その場合、任意の峰値の位置を返せば良いです。
nums[-1] = nums[n] = -∞ を仮定します。
この問題を O(log n) の時間計算量で解く必要があります。
ヒント:
- 1 <= nums.length <= 1000
- -2の31乗 <= nums[i] <= 2の31乗 - 1
- 有効な i に対して nums[i] != nums[i + 1]
解法
傾斜が存在する場合、山の方向に沿って答えを見つけることができます。
class Solution {public: int findPeakElement(vector<int>& nums) { int l=0,r = nums.size()-1; while(l<r){ int mid = (l+r) >> 1; long long lm = mid-1,rm = mid+1; if(lm<0) lm = INT_MIN-1ll; else lm = nums[lm]; if(rm>=nums.size()) rm = INT_MIN-1ll; else rm = nums[rm]; long long key = nums[mid]; if(key>lm && key>rm) return mid; else if(key>lm &&rm>key) l = mid+1; else r = mid-1; }return l; }};行列の極小値の探索
マイクロソフトの面接問題
問題の説明
の行列を与える。行列には 個の 互いに異なる 整数が含まれる。
極小値の定義:ある数値が、周囲の上下左右の4方向のいずれの値よりも小さい場合、その値は極小値と呼ばれます。
ある数の隣接数は、上下左右の4方向にある数を指します。境界や角にいる数の隣接数は4つ未満になることもあります。
の時間計算量で、任意の極小値の位置を見つけ、その行と列が何番目かを出力してください。
本問の行列は隠されています。事前に用意された int 関数 query で、行列中の任意の位置の数値を取得できます。
例えば query(a,b) は行列の第 行第 列の値を取得します。
注意:
- 行と列はともに0から始まります。
- query() の呼び出し回数は を超えてはいけません。
- 答えは一意ではないため、任意の極小値の位置を出力してください。
データ範囲
、行列中の整数は int 範囲。
解法
前問と同様で、呼び出し回数をヒントとして利用します。 列を走査して、その列の最小値を含む行を調べます。ここで、二分の条件は、列の最小値とその行の左右の値の比較です。
// Forward declaration of queryAPI.// int query(int x, int y);// return int means matrix[x][y].class Solution {public: vector<int> getMinimumValue(int n) { typedef long long ll; ll INF = 1e15; int l,r;l=0;r = n-1;
while(l<r){ int mid = l+r>>1; ll val = INF; int p=0; for(int i=0;i<n;i++){ int t = query(i,mid); if(t < val) val = t,p = i; } ll lt = mid ? query(p,mid-1):INF; ll rt = mid+1<n ? query(p,mid+1):INF;
if(val<lt && val<rt) return {p,mid}; if(lt<val) r = mid - 1; else l = mid + 1; }
ll val = INF;int p=0; for(int i=0;i<n;i++){ int t = query(i,r); if(t<val) val = t,p = i; } return {p,r};
}};卵の硬度
Googleの面接問題
入力形式
入力は複数のデータセットから成り、それぞれ1行に と の2つの正の整数が含まれます。 はビルの高度を、 は現在持っている卵の個数を表します。これらの卵の硬度は同じであり(同じ高さから落とすと、割れるか割れないかがすべて同じ)、 以下です。
硬度が の卵は、高さが 以下の場所から投げても決して割れません(割れなかった卵は引き続き使用可能)、一方で より高い場所から投げると必ず割れます。
各データに対して、卵の硬度は から の範囲であると仮定します。つまり 層の高さから投げても必ず割れます。
出力形式
各データセットについて、最適な戦略を用いた場合の最悪時に必要な投げ回数を1つの整数として出力します。
データ範囲
,
サンプルの説明
最適戦略とは、最悪の場合の投げ回数を最小にする戦略のことです。
卵が1つしかない場合、最初の1階から投げるしかなく、最悪の場合硬度は 100 になるため、100 回投げる必要があります。別の戦略をとると、最悪の場合に硬度を測定できず、無限回投げる必要がある可能性があるため、最初のデータは 100 になります。
解法
dp1
長さ i の区間を j 個の卵で得られる最適戦略を表す。
卵 j を使う場合、使わない場合 f[i][j] = f[i][j-1]、使用する場合は区間の 1〜i のうちいくつかの k を選ぶ。このとき、卵が割れる場合(f[k-1][j-1])、割れない場合(f[i-k][j])、最悪はこの二者の大きさの最大値。最小の戦略は min(f[i][j], max(f[k-1][j-1], f[i-k][j]) + 1)
#include<iostream>#include<algorithm>#include<cstring>using namespace std;const int N =110,M=11;int n,m,f[N][M];
int main(){ while(cin>>n>>m){ for(int i=1;i<=n;i++) f[i][1] = i; for(int i=1;i<=m;i++) f[1][i] = 1;
for(int i=2;i<=n;i++) for(int j=2;j<=m;j++){ f[i][j] = f[i][j-1]; for(int k=1;k<=i;k++) f[i][j] = min(f[i][j],max(f[k-1][j-1],f[i-k][j])+1); } cout<<f[n][m]<<endl; }return 0;}dp2
異なる方法として、f[i][j] は i 回の測定で j 個の卵を使って得られる最大長さを表す。
測定位置 k を仮定すると、卵が割れる(f[i-1][j-1]、下半分を再帰)または割れない(f[i-1][j]、上半分を再帰)という二つのケース。
#include<iostream>#include<algorithm>#include<cstring>using namespace std;const int N =110,M=11;int n,m,f[N][M];
int main(){ while(cin>>n>>m){ for(int i=1;i<=n;i++){ for(int j=1;j<=m;j++) f[i][j] = f[i-1][j]+f[i-1][j-1]+1;
if(f[i][m] >= n){ cout<<i<<endl; break; } } }return 0;}最小値を含むスタック
Huluの面接問題
問題の説明
push,pop,top などの操作をサポートし、かつ最小値を O(1) で検索できるスタックを設計する。
- push(x) – 要素 x をスタックに挿入
- pop() – スタックのトップ要素を取り除く
- top() – ストップ要素を得る
- getMin() – スタック中の最小要素を得る
データ範囲
操作コマンドの総数は [0,100]。
サンプル
MStack minStack = new MStack();minStack.push(-1);minStack.push(3);minStack.push(-4);minStack.getM(); --> Returns -4.minStack.pop();minStack.top(); --> Returns 3.minStack.getM(); --> Returns -1.解法
方法1
挿入時にその時点の最小値を格納する形で、配列を直接使います。
class MinStack {public: /** initialize your data structure here. */ int len; int a[110],ck[110];
MinStack() { len = a[0] = ck[0] = 0; }
void push(int x) { a[len] = x; ck[len] = min(len?ck[len-1]:x,x); len++; }
void pop() { len--; }
int top() { return a[len-1]; }
int getMin() { return ck[len-1]; }};方法2
単調スタックを用いて最小値を維持します。
ck.top() >= x の場合、ck に格納される値は単調減少の最小値になります。pop の場合、ck の現在の最小値と一致しなければ ck の更新は不要です。最小値を取得するには ck.top() を使います。
class MinStack {public: /** initialize your data structure here. */ stack<int> a; stack<int> ck;
MinStack() {
}
void push(int x) { a.push(x); if(ck.empty() || ck.top() >= x) ck.push(x); }
void pop() { if(ck.top() == a.top()) ck.pop(); a.pop(); }
int top() { return a.top(); }
int getMin() { return ck.top(); }};リンケージ内の環の入口結点
アリババの面接問題
問題の説明
リストが与えられ、もし環が含まれていれば、その環の入口ノードを出力してください。環が含まれていない場合は null を出力します。
データ範囲
ノードの val の値は 。ノードの val はすべて異なります。リストの長さは 。
サンプル
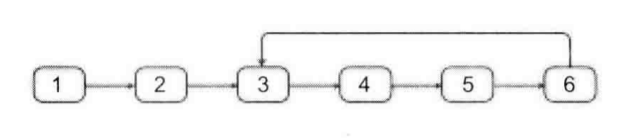
上記のようなリスト:[1, 2, 3, 4, 5, 6]2ここでの 2 は番号が 2 のノードを表します。ノード番号は 0 から始まるので、番号が 2 のノードは val が 3 のノードです。したがって環の入口ノードは 3 です。解法
val の値は異なり範囲が 1000 に限定されていることから、既に出現した val 値に対応するノードを記録する配列を用いればよい。再度同じ val に出会うと、それが循環を示します。
class Solution {public: ListNode *entryNodeOfLoop(ListNode *head) { ListNode* ck[1010];
for(auto p=head;p;p=p->next){ int val = p->val; if(ck[val]) return ck[val]; ck[val] = p; }return NULL; }};この記事が役に立ったときは、ぜひ他の人に共有してください!
一部の情報は古い可能性があります